Introduction à la
programmation orientée objet et au langage C++
Jacques PHILIPP
Professeur
adjoint d'Informatique à l'ENPC le 19 février 2002
Table
des matières
1. Le génie logiciel 10
1.1 De l'art de la programmation aux méthodes
du génie logiciel 10
1.1.1 Evolutions de la programmation 10
1.1.2 Le génie logiciel 11
1.2 Etapes du développement d'un logiciel 12
1.2.1 Analyse 12
1.2.2 Spécification 12
1.2.3 Programmation 13
1.2.4 Mise au point et tests 13
1.2.5 Maintenance et support 14
1.2.6 Productivité du logiciel 14
1.3 Critères de qualité du logiciel 15
1.4 Les mécanismes d'abstraction 16
1.4.1 L'abstraction procédurale 16
1.4.2 L'abstraction des données 16
1.4.3 La programmation orientée objet 17
1.4.4 Le principe de partage 17
1.4.5 Les invariants 17
1.5 La chaîne de développement et ses outils 17
1.5.1 Généralités sur les outils de
développement 17
1.5.2 Editeurs de textes 18
1.5.3 Mise en forme 18
1.5.4 Analyseur syntaxique 18
1.5.5 Compilation et édition de lien 18
1.5.6 Langage machine 19
1.5.7 Outils de recherche d'erreurs 19
1.5.8 Outils de génie logiciel 19
1.5.9 Profileur 19
1.5.10 Outils de test 19
1.5.11 Graphe de la chaîne de développement 20
1.5.12 Choix du langage de programmation 20
1.5.13 Raisons du succès du langage C 20
2. Algorithmique élémentaire 22
2.1 Introduction 22
2.2 Mise au point préalable et preuve d'un
algorithme 22
2.3 Transcription du problème sous une forme
calculable 22
2.4 Complexité 23
2.4.1 Problèmes NP‑complets 23
2.4.2 Comportement asymptotique 23
2.5 Enoncés de problèmes classiques 24
2.5.1 Recherche d'une valeur dans un tableau 24
2.5.2 Problème du tri 25
2.5.3 Enoncé du problème du représentant de
commerce 25
2.5.4 Problème de l'arrêt 25
2.6 Méthodes de conception d'algorithmes 26
2.6.1 Méthodes par décomposition 26
2.6.2 Diviser pour régner 26
2.6.3 La modularité 27
2.6.4 Critères de modularité 27
2.6.5 Principes de modularité 27
3. Méthodologie de programmation 29
3.1 Principes généraux de la programmation 29
3.1.1 Choix du langage de programmation 29
3.1.2 Méta langage 29
3.1.3 Commentaires 29
3.1.4 Règles d'or de la programmation 29
3.2 Grammaire 30
3.2.1 Langage et grammaire 30
3.2.2 Syntaxe et sémantique 31
3.2.3 Mots clés 31
3.2.4 Représentation interne des objets 31
3.2.5 Objets de base du langage 32
3.2.6 Construction d'objets complexes 32
3.2.7 Opérations sur les objets de base 32
3.3 Opérations d'entrées/sorties 33
3.4 Structure d'un programme 33
3.4.1 Instruction élémentaire 33
3.4.2 Alphabet 33
3.4.3 Définition 34
3.4.4 Déclaration 34
3.4.5 Affectation 34
3.4.6 Niveaux de complexité d'une instruction 35
3.4.7 Structure de bloc 35
3.4.8 Fonction 36
3.4.9 Modes de transmission des arguments
d'une fonction 36
3.4.10 Exemple de fonction
complexe : la fonction qsort 37
3.4.11 Procédure 37
3.4.12 Programme principal 38
3.4.13 Structure d'un programme en C++ 38
3.5 Structures de contrôle des programmes 38
3.5.1 Test 39
3.5.2 Branchement inconditionnel (ne pas
utiliser) 39
3.5.3 Branchement conditionnel (ne pas
utiliser) 39
3.6 Algorithme itératif ‑ boucle 42
3.6.1 Généralités 42
3.6.2 Boucle à nombre d'itérations bornées 43
3.6.3 Boucle à nombre d'itération non borné 44
3.6.4 Boucle Répéter jusqu'à 47
3.7 Programmes itératifs 47
3.7.1 Construction récurrente 47
3.7.2 Exemples 48
3.7.3 Exercice commenté : le
problème du drapeau hollandais 48
3.7.4 Cas des boucles imbriquées 51
3.7.5 Bibliographie du présent chapitre 51
4. Concepts de base des Langages Orientés
Objet et langage C 52
4.1 Généralités 52
4.2 Classes 52
4.2.1 Définitions 52
4.2.2 Héritage 53
4.3 Approche orientée objet, données abstraites
et encapsulation 53
4.3.1 Types abstraits de données 53
4.3.2 Encapsulation des données 54
4.4 Initialisation des données 54
4.5 Polymorphisme, surcharge et généricité 55
4.6 Principes généraux de protection des
données 56
4.7 Abstraction et encapsulation en langage C 56
4.7.1 Premier essai d’implémentation 56
4.7.2 Deuxième essai d’implémentation d'un
type abstrait en C 57
4.7.3 Troisième essai d’implémentation d'un
type abstrait en C 59
4.7.4 Conclusion sur les types abstraits en C 60
5. Le C++, langage procédural 61
5.1 Introduction 61
5.2 Commentaire 61
5.3 Types de base 62
5.4 Saisie et affichage élémentaire en C++ 63
5.4.1 Opérateurs de base 63
5.4.2 Interprétation objet des entrées/sorties 64
5.5 Définition et instruction exécutable 65
5.6 Déclaration et définition 66
5.7 Nouveaux opérateurs du langage C++ 66
5.8 Caractéristiques d'un fichier en tête 66
5.9 Le spécificateur const et les variables 66
5.10 Complément sur le type struct 67
5.11 L'opérateur de résolution de visibilité 67
6. Le C++, langage fonctionnel 69
6.1 Prototypage 69
6.2 Le type void 69
6.3 Surcharge d'une fonction 70
6.4 Valeur par défaut des arguments d'appel 72
6.5 Référence 74
6.5.1 Le type référence 74
6.5.2 Transmission d'argument par référence 75
6.5.3 Le spécificateur const et la transmission d'argument par
référence 77
6.5.4 Transmission du résultat d'un appel de
fonction par référence 78
6.6 Variables et fonctions statiques 79
6.6.1 Variables statiques 79
6.6.2 Fonctions statiques 80
6.7 Fonctions spécifiées inline 80
7. Classes en langage C++ 82
7.1 Principes 82
7.2 Définition 82
7.3 Qualification d'accès aux membres d'une
classe 84
7.4 Méthode 86
7.5 Le pointeur this 86
7.6 Méthode spécifiée constante 87
7.7 Membre statique 88
7.7.1 Donnée membre statique de
la classe 89
7.7.2 Variable statique définie
dans une méthode 89
7.7.3 Méthode statique 91
7.8 Pointeur sur les membres d'une classe 92
8. Constructeur et destructeur 93
8.1 Définitions 93
8.2 Constructeur 93
8.2.1 Constructeur implicite 93
8.2.2 Constructeur explicite 94
8.2.3 Constructeurs multiples 96
8.2.4 Transtypage par appel d'un constructeur 98
8.3 Destructeur 102
8.4 Allocation dynamique 102
8.4.1 Principes de gestion de l’allocation
dynamique en C++ 102
8.4.2 L'opérateur new 102
8.4.3 L'opérateur delete 102
8.4.4 Règles d'utilisation 103
8.4.5 Exemples 103
9. Surcharge des opérateurs 108
9.1 Généralités et syntaxe 108
9.2 Opérateur surchargé membre d'une classe 108
9.3 Opérateur surchargé non membre d'une
classe 110
9.4 Amitie et Levée partielle de
l'encapsulation 111
9.5 Surcharge de l'opérateur < 112
9.6 Transtypage d'un objet typé vers le type
classe 113
9.7 Surcharge d'opérateur et fonction amie 115
9.8 Surcharge de l'opérateur [] 116
9.9 L'opérateur d'affectation 118
9.9.1 Constructeur copie 118
9.9.2 Surcharge de l'opérateur d'affectation 122
9.10 Surcharge des opérateurs d'incrémentation et
de décrémentation 124
9.11 Surcharge de l'opérateur fonctionnel 125
9.12 Opérateurs de transtypage 128
9.13 Opérateurs de comparaison 128
9.14 Opérateurs de déréférenciation, de
référence, de sélection de membre 128
9.15 Opérateurs d'allocation dynamique de mémoire 129
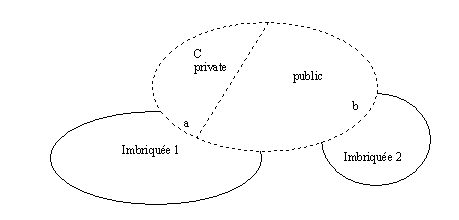
10. Classes imbriquées 131
10.1 Définition 131
10.2 Données membres instances d'une autre classe 131
10.3 Exercice récapitulatif sur les classes
imbriquées 133
11. L'héritage en langage C++ 138
11.1 Définitions 138
11.2 Résolution de visibilité 140
11.3 Qualifications d'accès des objets d'une
classe 141
11.4 Qualification de l'héritage 141
11.4.1 Qualifications de l'héritage des objets de
la classe de base 141
11.4.2 Règles d'accès aux objets dans la classe
dérivée selon la qualification de l'héritage 142
11.4.3 Inclusion des classes dérivées dans la
classe de base selon la qualification de l'héritage 143
11.4.4 Transtypage selon la qualification de
l'héritage 144
11.4.5 Requalification des qualifications d'accès
dans les classes dérivées 144
11.5 Classes dérivées et constructeur 150
11.6 Classe virtuelle 152
11.6.1 Définition 152
11.6.2 Règles
d'utilisation des classes virtuelles 156
11.7 Méthodes virtuelles, lien dynamique,
polymorphisme 156
11.8 Règles de dérivation 159
11.9 Méthodes virtuelles pures - classes
abstraites 161
11.9.1 Définitions 161
11.9.2 Conteneur et objets polymorphiques 162
12. Les modèles génériques (template) 168
12.1 Généralités 168
12.2 Déclaration de type générique 168
12.3 Fonction et classe générique 169
12.3.1 Fonctions avec des types d'arguments génériques 169
12.3.2 Classe générique 171
12.3.3 Méthodes génériques 174
12.4 Instanciation des paramètres génériques 176
12.4.1 Instanciation implicite de fonction avec
des arguments de type générique 176
12.4.2 Instanciation explicite d'objet générique 178
12.4.3 Problèmes soulevés par l'instanciation des
objets génériques 181
12.5 Spécialisation des objets génériques 181
12.5.1 Spécialisation partielle d'une classe 182
12.5.2 Spécialisation totale d'une classe 184
12.5.3 Spécialisation d'une méthode d'une classe générique 184
12.6 Paramètres génériques
template template 186
12.7 Déclaration des constantes génériques 187
12.8 Généricité et méthode
virtuelle 188
12.9 Mot clé typename 191
12.10 Fonctions exportées 191
13. Espace de nommage 193
13.1 Espace nommé et anonyme 193
13.1.1 Espace nommé 193
13.1.2 Espace anonyme 195
13.2 Alias d'espace de nommage 196
13.3 Déclaration et directive using 196
13.3.1 Déclaration using 198
13.3.2 Directive using 199
14. Les exceptions en langage C++ 202
14.1 Principes sémantiques 202
14.2 Principes de gestion des
exceptions en langage C++ 202
14.3 Génération et traitement d'une exception 203
14.3.1 Zone
de prise en compte d'une exception 203
14.3.2 Définition
d'un gestionnaire d'exception 204
14.4 Remontée des exceptions 205
14.5 Liste des exceptions autorisées pour une fonction 206
14.6 Exceptions et constructeurs 207
14.7 Exceptions et allocation mémoire 209
14.8 Hiérarchie des exceptions 209
15. Identification des types dynamiques 211
15.1 Identification dynamique d’un type 212
15.1.1 L'opérateur typeid 212
15.1.2 La classe type_info 213
15.2 Transtypages en langage C++ 214
15.2.1 Généralités sur les opérateurs de
transtypage 214
15.2.2 Transtypage dynamique 214
15.2.3 Transtypage statique 216
15.2.4 Transtypage de constance et de volatilité 217
15.2.5 Réinterprétation des données 217
16. Exercices 219
16.1 Exercice récapitulatif 219
16.2 Exercices sur les constructeurs et les
destructeurs 222
16.2.1 Exercice 1 222
16.2.2 Exercice 2 223
16.2.3 Exercice 3 224
16.2.4 Exercice 4 226
16.3 Exercice : implémentation de type
utilisateur en C++ 227
16.4 Exercice : exemple de type abstrait en C++ 229
17. Priorité des opérateurs 234
18. BIBLIOGRAPHIE 236
Index 237
Cinquante ans après les débuts de
l'informatique, les méthodes et les outils de développement d'applications ont
beaucoup évolués : on est passé du langage machine au langage de cinquième génération ainsi qu'au générateur
d'applications. On peut faire la classification
sommaire suivante
Génération : 1ère 2ème 3ème 4ème 5ème
langage
machine Assembleur langage évolué S.G.B.D. L4G, générateurs
Þ Programmation et rendement
En 1972, le rendement moyen d'un programmeur
professionnel est de 8 lignes par heure (source Pentagone : colloque
de Monterey : The high cost of software). L'écriture de
"bons" programmes est très longue et difficile.
Þ Coûts de développement
Les mêmes statistiques indiquent à cette
époque un coût d'écriture par instruction de 75 $ US et de mise au
point de 4 000 $ US.
Þ Evolution du profil du programmeur
Le profil du programmeur a évolué depuis
1950 :
1950 Il
est un initié qui utilise
exclusivement le langage machine.
1968 Il
est considérée comme un artiste
(Knuth).
1975 Il doit respecter une discipline (Dijkstra) et suivre quelques
règles de programmation non empirique.
1981 La
programmation est devenue une science
(D.Gries).
Þ Les causes
Les concepts de test et de branchement
conditionnel (ou rupture de séquence) dûs à Von Neumann, ont permis le démarrage de l'écriture de
programmes informatiques. Malheureusement, l'utilisation du branchement
conditionnel est aussi une des sources importante d'erreurs car bien souvent
les programmeurs, au moment de la rédaction du programme, effectuent des
branchements multiples et quelquefois (?) ne savent plus, oublient le
pourquoi du branchement. Petit à petit, la nécessité de structurer sa pensée et
les programmes est apparue et a donné naissance aux concepts de la programmation structurée. "Ce qui
se conçoit bien s'énonce clairement et les mots pour le dire arrivent
aisément..."
Ces concepts sont utilisés dans les langages
structurés tels le le C (Kernighan & Ritchie), ADA (Ichbiah), Java.
Leur utilisation a conduit à la suppression de
la rupture de séquence, "ennemie du bon programmeur".
Þ Erreurs et preuves de programmes
Il faut toujours se souvenir de cette
constatation d'E. Dijkstra : "Essayer un programme peut
seulement montrer qu'il contient des erreurs. Jamais qu'il est juste".
Le génie
logiciel est l'art de développer des
logiciels. Il devrait être une discipline d'ingénierie aussi solidement établie
dans ses méthodes et ses principes que le génie civil. Nous en sommes encore
loin aujourd'hui.
Þ Difficultés de conception des logiciels
Plusieurs facteurs contribuent à rendre
difficile la conception et le développement des logiciels :
·
Ils peuvent être d'une très grande
complexité, à la limite de l'ingéniosité humaine.
·
Aucune loi physique ne permet de limiter
l'espace des solutions possibles.
·
Les causes des pannes sont aléatoires.
Une simple erreur d'inattention dans un programme de plusieurs millions de
lignes peut interrompre le service qu'il fournit.
Þ Chaque détail compte
Des erreurs d'apparence anodine peuvent se
glisser dans des programmes. Soit le programme C suivant :
if
(i = 0) printf ("la valeur de i est zéro\n");
else
printf('la valeur de i n'est pas zéro\n");
Contrairement à ce qu'une lecture rapide
laisserait penser, et contrairement à l'intention du programmeur, ce programme
imprime "la valeur de i est zéro" quelle que soit la valeur de la variable
i car en C, le symbole = représente l'opérateur d'affectation et non
l'opérateur de comparaison logique (qui en C s'écrit = = ). La
valeur de l'expression i = 0 est toujours nulle, quel que soit le
contenu initial de la variable i, et la condition du test n'est jamais
satisfaite.
Þ Une simple question d'argent ?
Le logiciel embarqué dans la navette spatiale
américaine a été développé avec le soin le plus extrême, et on estime son prix
de revient à 25.000 FF par ligne (sans les commentaires). Aucun organisme dans
le monde, à part la NASA ne peut se permettre d'investir autant d'argent par
ligne de code. Pourtant, ce logiciel contient encore des erreurs. A chaque vol,
les astronautes partent avec la liste des erreurs référencées dont l'une est la
suivante : lors de l'utilisation simultanée de deux claviers , le ou logique des caractères saisis est
transmis à l'ordinateur. La solution retenue a été de n'utiliser qu'un clavier
à la fois.
Þ Le développeur de logiciels
On observe des différences de productivité considérables
entre programmeurs médiocres et programmeurs de talent.
On pense trop souvent que le développement de
logiciel est une tâche dégradante, à confier à des ingénieurs débutants.
Pourtant, la conception d'ouvrages d'art importants est toujours confiée à des
ingénieurs confirmés. Et on comprend mal pourquoi il faudrait opérer
différemment pour la conception des logiciels car c'est une tâche qui requiert
autant d'expertise pour être menée à bien.
Þ Valeur d'un logiciel
Le folklore
informatique ignore un point important : la valeur marchande d'un
logiciel tient autant à son introduction rapide sur le marché qu'à ses qualités
propres. Le client n'est pas toujours
prêt à attendre qu'un programmeur exceptionnellement doué ait trouvé une
solution élégante à son problème. Il a tort à long terme, mais il paie.
Les différentes étapes de développement d'un
logiciel, présentées ici en séquence, interagissent en réalité de façon
complexe.
L'analyse
consiste à déterminer les grandes lignes du logiciel ainsi que ses contraintes
d'utilisation et d'exploitation. Il faut en outre cerner les besoins de
l'utilisateur.
Voici quelques questions typiquement abordées
lors de cette phase de développement.
·
De quel type de programme s'agit‑il
(traitement de transactions, contrôleur temps réel, applicatif bureautique,
etc.) ?
·
Quelles en sont les entrées et les sorties ?
·
Sur quel matériel et quel système
d'exploitation doit‑il s'exécuter?
·
De combien de temps et de personnel
dispose‑t'on pour développer l'application ?
·
Quelles en seront les extensions futures
les plus probables ?
·
Qui en est le destinataire (grand public
ou professionnels pour lesquels une période de formation peut être
prévue) ?
La spécification
est une réponse formelle aux besoins identifiés durant l'étape
d'analyse. Elle comprend :
·
une description précise des entrées et
des sorties,
·
des données chiffrées sur le temps de
développement et sur les configurations matérielles et logicielles requises,
·
des données chiffrées résultants des
spécifications (nombre d'utilisateurs, temps de réponse, etc.),
·
une version préliminaire de la
documentation de l'application.
Þ Documentation
La documentation
fait partie intégrante de l'effort de programmation. Le programme lui‑même
en constitue une partie importante.
A cela doit s'ajouter un document technique de référence qui comprend des aspects normatifs,
et formalise l'effort de conception du logiciel. Notamment :
·
une description précise de l'architecture
générale du projet et de son découpage en modules,
·
une description précise des fonctions de
chaque module, de leurs interfaces et
protocoles de communication,
·
une description précise des composants
logiciels utilisés (bibliothèques graphiques, générateurs d'interface,
générateurs de requêtes de base de données, composants réutilisables pour
d'autres projets, etc.).
Une fois les outils de développement choisis,
l'étape de la programmation consiste à écrire le code des différents modules.
On réalise généralement incrémentalement les fonctionnalités du logiciel, et on
effectue des tests sur chaque module avant d'assembler le tout.
Þ La méthode des approximations successives
L'effort de programmation fait généralement
apparaître des erreurs de conception, qui nécessitent une modification du
découpage du logiciel en modules et en conséquence une modification des
documents rédigés à l'étape précédente.
Þ Programmation et chirurgie
Programmer prend du temps et n'est pas
toujours une tâche d'exécutant. Les éditeurs de logiciel les plus performants
utilisent plutôt le modèle de l'équipe chirurgicale. Le chirurgien est responsable des parties les plus délicates et les
plus difficiles du logiciel, et le reste de l'équipe sert de support,
programmant les parties les plus aisées et rédigeant la documentation.
Þ Preuves de programmes
La preuve mathématique complète qu'un
programme correspond à ses spécifications est la seule garantie qu'un programme
ne comporte pas d'erreurs. Toutefois, on ignore comment rédiger les
spécifications d'un logiciel de façon non ambiguë et parfaite. La complexité
d'une telle preuve la rendrait impossible sans une certaine forme
d'automatisation. Or les logiciels d'analyse de programmes sont limités pour
des raisons théoriques. On sait par exemple qu'il n'existe aucun algorithme
capable de déterminer si un programme risque de boucler indéfiniment. Les
logiciels d'analyse formelle (de logiciels) ne peuvent être que des aides partielles à la preuve. Il en existe, mais leur application
est pour le moment limitée car ils imposent une méthodologie de développement
très rigide.
Þ Jeux d'essais
On se rabat donc sur des simulations ou tests pour
valider un logiciel. Idéalement il faudrait en essayer tous les modules de
façon exhaustive. Dans la réalité, on utilise deux types d'approches :
·
des tests
ciblés, pour mettre des erreurs en évidence. Un bon exemple est de tester
les conditions limites. On pourra
tester le fonctionnement d'une procédure de tri sur un tableau de taille nulle
ou sur un tableau contenant des entrées identiques. Ces tests ciblés peuvent
demander de l'ingéniosité.
·
Des tests en utilisation réelle,
généralement faits par un client enthousiaste ou impatient. Ces tests sont
réalisés sur des versions préliminaires du logiciel, appelées alpha ou beta releases. C'est ce qu'à fait, à 500 000 exemplaires,
l'éditeur de logiciels Microsoft, avant la sortie du système Windows 95. Cela
n'a d'ailleurs pas suffit, loin de là, à éliminer tous les bogues.
La maintenance d'un logiciel consiste à en corriger les bogues, à en étendre les fonctionnalités, et à en assurer le portage sur différentes
plateformes matérielles et systèmes d'exploitation. Elle est coûteuse et son
importance souvent sous‑estimée. Il s'agit en fait de la continuation de
l'effort de développement. Ainsi, le logiciel de traitement de texte Word,
initialement développé par une équipe de quatre personnes, est maintenu par une équipe de vingt‑cinq.
On commet trop souvent l'erreur de ne pas anticiper les besoins de maintenance
pendant le développement initial d'un logiciel.
Le support
d'un
logiciel consiste à assurer un service de formation et d'assistance auprès de
la clientèle. Son coût n'est pas non plus négligeable.
On estime à 70% du
coût total de développement celui de la maintenance
dont on rappelle la nécessité :
·
évolutivité du logiciel.
·
correction de ses bugs.
Les aspects économiques du développement de
logiciel sont encore mal maîtrisés. Ainsi, connaissant le coût de la
réalisation du logiciel de l'A310 et le cahier des charges de celui de l'A320,
son coût fut estimé, à méthode de développement équivalente, entre 3 et 12 fois
celui de l'A310, selon les méthodes d'évaluation. Une des difficultés de ce
type d'exercice prévisionnel est la manque de précision de la mesure de productivité du logiciel que
plusieurs techniques permettent, imparfaitement, de mesurer.
Þ Le nombre de lignes de code par programmeur par jour
La mesure la plus couramment utilisée de la
productivité d'une équipe de développement est le nombre de lignes de programme
produites par jour. Elle est mauvaise pour au moins trois raisons :
·
Un programmeur compétent consacre un
temps parfaitement productif à réduire le taille de ses programmes. Ce travail
en réduit la complexité et en augmente la valeur.
·
Cette mesure ne fait pas la différence
entre la productivité d'une équipe qui réalise un logiciel de 10.000 lignes de
code en un an, et celle qui réalise en deux ans un logiciel de capacité
équivalente de 20.000 lignes de code.
·
Le nombre de lignes de code produites par
un programmeur par jour varie selon la complexité du logiciel. Une mesure
empirique de cet effet est donnée par la formule suivante :
effort = constante * (taille du programme)1.5
Þ Une meilleure mesure de productivité
Pour obtenir une meilleure mesure de la
productivité d'une équipe de développement, il est préférable d'estimer
directement la valeur et le coût de développement d'un logiciel.
La
valeur d'un logiciel tient compte de sa valeur
marchande, de son évolution probable dans le temps ainsi que de la complexité
intrinsèque du problème résolu, qui représente une indication de la difficulté qu'aura
la concurrence à reproduire un effort de développement similaire ainsi que la
possibilité de réutiliser tout ou partie de ce logiciel.
Le coût
de développement d'un
logiciel doit inclure le coût de développement proprement dit, le surcoût
du au retard possible de sa commercialisation, ainsi que celui de son support
et de sa maintenance pendant sa durée de vie.
Un
logiciel doit être doté des qualités
suivantes :
·
Validité : aptitude d'un
logiciel à réaliser exactement les tâches définies par sa spécification.
·
Robustesse : aptitude d'un
logiciel à fonctionner même dans des conditions anormales.
·
Extensibilité : facilité
d'adaptation d'un logiciel à une modification des spécifications.
·
Réutilisabilité : aptitude d'un
logiciel à être réutilisé en partie ou en totalité pour de nouvelles
applications.
·
Compatibilité : aptitude d'un
logiciel à pouvoir être combiné avec d'autres.
·
Efficacité : bonne utilisation des ressources matérielles et
logicielles
·
Portabilité : facilité d'adaptation d'un logiciel à différents
environnements matériels et logiciels.
·
Vérifiabilité : facilité de préparation des procédures de recette et de
certification, notamment des tests et des procédures de déboguage.
·
Intégrité : aptitudes d'un
logiciel à protéger ses différentes composantes (programmes, données) contre
des accès ou des modifications non autorisées.
·
Facilité
d'utilisation du logiciel par les utilisateurs
(fonctionnement, préparation d'utilisation, interprétation des résultats,
réparation en cas d'erreurs d'utilisation).
Þ L'ergonomie
Un programme peut être parfait du point de vue
de ses concepteurs et contenir cependant des défauts qui peuvent s'avérer
fatals. La catastrophe de l'Airbus A320 du Mont Sainte Odile en est une
illustration. Cet avion avait un écran d'affichage sur lequel s'affichait,
selon un mode choisi par le pilote (la position d'un bouton), la vitesse
verticale de l'avion en pieds par seconde ou l'inclinaison de sa trajectoire en
degrés. Il semble que le pilote ait interprété le contenu de l'écran
d'affichage d'une façon, sans s'apercevoir que le copilote avait changé le mode
d'affichage. L'avion a ainsi perdu trop rapidement de l'altitude sans que le
pilote s'en aperçoive à temps. Dans cet exemple, le logiciel a fonctionné
parfaitement, selon ses spécifications. De nos jours, nous plaçons des
barrières de sécurité le long des routes aux endroits dangereux. Nous avons
encore à apprendre à le faire dans la conception du logiciel. La leçon à
retenir de la catastrophe du Mont Sainte Odile est qu'une mauvaise interface
homme‑machine peut être aussi dangereuse qu'une erreur de programmation.
Þ Le long terme
Le manque de vision à long terme dans le
développement de logiciels est aussi la source de nombreux déboires. Le
problème de loin le plus fréquent est causé par l'introduction de limites
arbitraires d'adressage ou de précision, dont il est difficile de se
débarrasser après coup. En voici deux exemples.
Cobol
Cobol, un langage de programmation introduit
dans les années cinquante pour les programmes de gestion, a connu un succès qui
a dépassé de loin les anticipations de ses concepteurs. De nombreux programmes
Cobol seront toujours utilisés en l'an 2000; malheureusement Cobol ne réservant
que deux chiffres décimaux pour indiquer l'année, il a fallu dépenser des
milliards pour corriger le bogue de l'an 2000.
Les missiles Patriot
Le système de défense anti‑aérienne
Patriot de l'armée américaine n'a pas intercepté un missile SCUD qui a fait 28
victimes au nord de l'Arabie Saoudite durant la guerre du Golfe. La raison
était un décalage de l'horloge du système de défense dans le temps, le système
ayant été initialement conçu pour intercepter des avions, et non des missiles
ballistiques qui se déplacent plus rapidement.
Deux
grandes classes de méthodes permettent de simplifier la conception et la
réalisation de logiciels : les mécanismes d'abstraction et les
invariants de programme.
Les mécanismes d'abstraction cherchent à distinguer
l'information nécessaire à l'utilisation d'un logiciel et celle qui est
nécessaire à sa réalisation. L'objectif est de permettre le développement de
logiciels complexes en minimisant les dépendances entre les modules et la
communication nécessaire entre les équipes de développement. Rappelons pour
mémoire la définition du mot abstraction :
Þ Définition
Fait de considérer à part un
élément (qualité
ou relation) d'une représentation ou
d'une notion, en portant spécialement l'attention sur lui et en négligeant les
autres.
Les
deux principaux mécanismes d'abstraction sont l'abstraction procédurale et l'abstraction par les données. Une bonne abstraction dissimule
une fonction à la fois complexe et utile derrière une interface simple à
utiliser. Toute la difficulté de la conception d'un programme réside dans leurs
choix.
L'abstraction procédurale regroupe dans une procédure
une action (calcul, action de contrôle, manipulation de données, etc.), pour la
rendre utilisable comme une primitive de
l'environnement de programmation. Elle permet au programmeur de faire appel à
une fonction tout en faisant abstraction des
détails de sa réalisation. Le programmeur n'a besoin de comprendre que les
paramètres qu'elle accepte et la fonction qu'elle réalise. Il n'a pas besoin de savoir comment cette fonction est réalisée. Par exemple, l'utilisation d'une
procédure de tri ne nécessite pas de connaître l'algorithme utilisé par le
programme.
La
plupart des logiciels s'organisent naturellement autour de la manipulation de
certains types de données : listes,
tables, graphes, fichiers, processus, fenêtres, transactions, relations, etc.
L'abstraction des données masque leur représentation interne selon leur type. Elle
n'autorise leur manipulation qu'à travers un ensemble défini de procédures,
appelées méthodes, dérivant de leur définition
mathématique.
Þ Définition
Un type abstrait est la donnée d'un ensemble de
valeurs et des procédures nécessaires pour y accéder et les modifier.
L'illustration
la plus simple d'une telle abstraction est la notion de fichier utilisée par
les appels systèmes du système d'exploitation UNIX, qui leur donne accès à
travers un ensemble d'appels système (open,
close, read, write).
L'abstraction des données est l'idée la
plus importante en génie logiciel de ces vingt dernières années. Son
utilisation simplifie considérablement l'architecture de logiciels complexes.
Depuis les années quatre‑vingt, elle a connu une explosion de popularité
avec l'introduction de langages de programmation dits orientés objet, dont le langage C++ est un des représentants
connus. Comme l'exemple des fichiers UNIX l'illustre, on peut simuler
l'abstraction des données par le mécanisme d'abstraction procédurale d'un
langage comme le C.
L'abstraction
procédurale comme l'abstraction des données permettent de respecter un des
principes les plus importants du développement logiciel : le principe du partage.
Þ Définition
Aucune
partie ou fonction d'un logiciel ne doit être dupliquée.
Toute
violation du principe du partage est source d'erreurs et de surcoûts durant la
maintenance du logiciel. Lorsqu'un logiciel complexe ne respecte pas ce
principe, il est facile d'oublier de modifier une des multiples copies d'une
fonction, créant ainsi des inconsistances
dans le logiciel. Le principe du partage est un excellent guide pour qui
cherche à déterminer les bonnes abstractions sur lesquelles baser
l'architecture d'un logiciel.
Un invariant est une propriété d'un
programme qui est vraie à un point donné d'exécution du programme, pour chaque
exécution possible du programme. C'est un outil conceptuel simple mais
essentiel.
Pour
s'exécuter, tout programme doit suivre le cycle suivant :
·
écriture du programme dans un langage évolué : c'est
le code source,
·
transformation du code source en langage
machine : c'est la compilation,
·
recherche par l'éditeur de liens dans les diverses bibliothèques des variables
dont les références sont
non satisfaites à la compilation pour la génération définitive du code exécutable
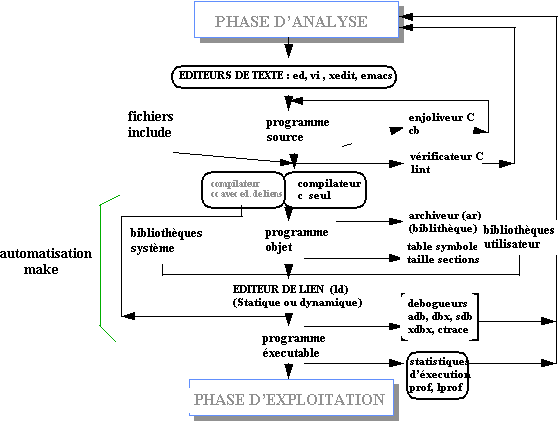
La chaîne de développement est constituée
par l'ensemble des outils constituant le support de programmation et permettant
de créer des programmes exécutables. Ils sont de quatre types :
·
édition et génération d'un programme
exécutable,
·
analyseur syntaxique et sémantique des
programmes,
·
outils de génie logiciel,
·
utilitaires divers.
Un éditeur de texte est un programme puissant
permettant l'écriture du texte. Il doit permettre de modifier facilement un (ou
plusieurs) mots dans une ligne, ou dans tout un programme, d'insérer, de
modifier, de déplacer, de dupliquer des lignes dans un texte. Certains éditeurs
très évolués sont de véritables traitements de texte.
La
mise en forme d'un fichier source d'un programme peut être complétée par
l'utilisation d'un enjoliveur de
programmes
La
vérification de la grammaire d'un programme source est réalisé par un analyseur syntaxique, dont les règles
grammaticales sont plus strictes que celles du compilateur lui même. Il renvoit
les messages d'erreurs du compilateur ainsi que des messages d'avertissement
spécifiques lorsqu'il détecte des incohérences de définition ou des problèmes
éventuels de portabilité.
L'utilisation
systématique d'un tel outil est recommandée avec comme objectifs l'élimination
progressive de tous les messages
d'avertissement (warning) ou
d'erreur.
L'adressage symbolique désigne des adresses mémoire ou des valeurs par des symboles alphanumériques appelés respectivement étiquettes (labels) ou symboles. Le programmeur peut ainsi associer une adresse en mémoire avec son
contenu. On fait référence à un symbole quand il est utilisé dans une
instruction du programme. Cette référence est une référence interne si le symbole est défini dans
le programme, référence externe sinon. Si on fait référence à
un symbole avant de l'avoir défini explicitement, on dit que la référence est
une référence en avant. La correspondance entre un
symbole et son adresse est assurée par la table
des symboles. Les références sont satisfaites quand il est possible
d'associer un symbole à son adresse à partir de la table des symboles.
Pour
que les références puissent être satisfaites, il est nécessaire à la plupart
des compilateurs de procéder en deux passes :
·
passe 1 : construction de
la table des symboles,
·
passe 2 : achèvement de la
table des références en avant, incomplète à la première passe.
Le
langage machine est spécifique au calculateur. Toutes les instructions en
langage machine sont représentées par une suite de 0 et 1 sous la forme :
CO CA AD
code condition zone
opération d'adressage adresse
Exemple : soit l'instruction (codée ici en hexadécimal et en binaire)
sur 32 bits
Hexadécimal 10 25 0208
Binaire 0001 0000 0010
1001 0000 0010 0000 1000
Un debugger (débogueur) permet de contrôler l'exécution et d'examiner les
données internes d'un programme pour isoler l'origine d'erreurs. D'autres
outils de mise au point permettent d'identifier des anomalies de références en
mémoire (pointeurs pendants, fuites de mémoire).
Un débogueur symbolique exécute sous son contrôle des
programmes pas à pas avec édition possible des variables intermédiaires
permettant la recherche des erreurs de programmation.
Les
techniques actuelles de développement d'applications imposent une programmation
de plus en plus modulaire. Il faut donc disposer d'outils de génération de
fichiers exécutables construits à partir de fichiers sources, éventuellement
écrits dans différents langages de programmation, de fichiers compilés, de
fichiers édités de telle sorte que l'on puisse faire des modifications dans un
fichier (source, bibliothèque,...) sans avoir à recompiler tout l'ensemble,
surtout s'il est important (plusieurs milliers de lignes de codes d'origines
diverses par exemple).
Les profileurs permettent d'obtenir des
statistiques d'exécution et de déterminer les éventuelles inutilisations des
certaines séquences en isolant les parties d'un programme qui utilisent le plus
de temps d'exécution.
Les
outils de tests sont importants pendant le développement et la maintenance d'un
logiciel.
Un test de régression est une suite de tests que l'on utilise pour
vérifier systématiquement qu'une modification n'a pas introduit d'erreur, donc
qu'elle n'a pas fait régresser le
logiciel.
Les tests de couverture vérifient que toutes les
parties d'un logiciel sont effectivement vérifiées.
D'autres
outils enfin génèrent automatiquement des jeux de test ayant certaines
propriétés.
La
plupart des logiciels sont développés dans des langages d'usage général, tels
le C ou le C++. Le langage Fortran est surtout utilisé en calcul scientifique,
et Cobol en informatique de gestion, mais C et C++ peuvent aussi être utilisés
dans ce type d'applications.
Le
langage C n'est pas un langage de programmation sans défaut. Il n'est pas
fortement typé, et il lui manque certains mécanismes importants d'abstraction
(objets) et de contrôle (exceptions). Enfin il force le programmeur à gérer lui‑même
son espace mémoire. Ces problèmes sont partiellement corrigés en C++, dont le
succès est essentiellement du à sa compatibilité avec C.
La
popularité du langage C s'explique de différentes façons :
Þ UNIX et C
Le
langage C a été inventé dans les laboratoires de recherche d'AT&T pour
réaliser les premières versions d'UNIX. Il a donc bénéficié de sa diffusion.
Þ Langage de bas niveau
Le
langage C est un langage dit de bas
niveau qui permet un contrôle fin des performances d'un logiciel et peut
être utilisé dans la plupart des applications.
Þ Normalisation et portabilité
Le
langage C est normalisé. Il s'exécute de façon presque identique sur toutes les
machines. C'est la meilleure approximation d'un langage portable qui existe. Un logiciel développé en langage C sur une
machine peut être compilé et exécuté avec un minimum d'effort sur la plupart
des ordinateurs existants. La portabilité
du langage C est un avantage économique considérable pour un développeur de
logiciel.
Þ Interface homme‑machine
La
plupart des logiciels existants offrent une interface avec le langage
C : système d'exploitation, système de gestion de bases de données,
systèmes de fenêtrage, tableurs, pour ne citer que les plus importants. En
outre, de nombreux outils de développement existent.
Pour
un développeur de logiciel, la portabilité
est le critère le plus important, suivi de l'existence d'outils de
développement.
Le mot algorithme est dérivé du nom du
mathématicien Persan Mohammed ibn Mûsâ al‑Khoârizmî à qui l'on doit un traité d'arithmétique : règles de
restauration et de réduction.
Un calcul
effectif est une suite d'opérations élémentaires que l'on peut, au moins théoriquement,
en disposant de suffisant de temps et de papier, effectuer à la main.
Un problème
calculatoire est une relation binaire entre un ensemble d'entrées (input) et un ensemble de sorties (output). Il faut donc clairement identifier les
données et les résultats que l'on souhaite obtenir.
Un algorithme est une méthode effective de calcul qui permet de résoudre un problème
calculatoire donné. Il est important d'en définir précisément la notion pour
utiliser à bon escient la puissance des outils mathématiques et les classifier.
Les points essentiels pour mettre au point un
algorithme sont les suivants :
·
Nécessité d'analyser le problème
préalablement à sa programmation.
·
Formalisation de l'énoncé.
On peut à ce moment là seulement définir
l'algorithme pour obtenir les résultats recherchés.
Þ Robustesse
Il doit être robuste en ce sens qu'il doit fonctionner quelles que soient ses
données. Tous les cas doivent avoir été prévus de telle sorte qu'il existe
toujours un traitement correspondant à la situation du problème (toujours
particulier) à résoudre.
Þ Preuve de l'algorithme
Il faut au moins vérifier, à défaut de prouver
théoriquement, que l'algorithme choisi donne la solution théorique et définir,
préalablement au passage sur ordinateur, un jeu
complet d'essais devant représenter l'ensemble des cas possibles. Cette dernière étape
est, en principe, la plus rapide car l'écriture du programme doit être ramenée
à une simple traduction de l'algorithme dans le langage de programmation
retenu.
L'algorithme posé en langage naturel doit être
transcrit dans un langage de programmation, de préférence évolué.
Le compilateur
ou l'interprète de commandes permet
de traduire le problème en langage machine, selon le type du langage choisi,
interprété ou compilé.
La complexité
d'un problème représente le nombre d'opérations nécessaires à sa résolution.
Elle devra avoir été évaluée de telle sorte que l'on puisse déterminer à priori le temps de calcul.
Certains problèmes ont des solutions
théoriques inexploitables. Par exemple au jeu d'échecs, un ordinateur peut
parfaitement battre le champion du monde dans la mesure où il peut faire, de
façon itérative, l'inventaire de toutes les solutions, en ...3 siècles de
calcul pour les ordinateurs les plus performants actuellement.
L'algorithme choisi sera donc un compromis
entre sa complexité et sa difficulté de mise en œuvre. Souvent, les algorithmes
les plus simples sont les plus efficaces.
Þ Exemple
La résolution d'un système d'équation par la
méthode de Cramer nécessite un temps de calcul très important puisque le calcul
d'un déterminant d'une matrice carrée d'ordre n par cette méthode nécessite n!
opérations. L'inversion d'un système linéaire par cette méthode nécessite donc
0((n+1)!) opérations. Dès que n est "suffisamment" grand, le
nombre d'opérations de cette méthode devient rédhibitoire. En comparaison, la
méthode de Gauss de résolution de système par triangulation ne nécessite que
0(n2) opérations.
Þ Il faudra donc vérifier que l'algorithme retenu n'est pas stupide.
Il est parfois impossible de calculer le
nombre d'opérations nécessaires à la résolution d'un problème. Dans
certaines situations, la complexité
d'un algorithme n'est pas polynomiale ce qui conduit à de nouvelles classes de
problèmes : les problèmes NP‑complets.
L'analyse de la performance des algorithmes
détermine les ressources matérielles nécessaires à leur
exécution : temps de calcul, mémoire, nombre d'accès disque pour des
algorithmes de gestion de bases de données opérant sur de grandes quantités
d'informations.
Þ Comportement asymptotique
L'analyse des algorithmes étudie leur comportement asymptotique en fonction
d'un petit nombre de paramètres caractéristiques de la taille de leurs entrées.
Pour un algorithme de tri, un seul paramètre suffit : le nombre
d'éléments à trier. Dans le cas d'un graphe,
on en utilise souvent deux : son nombre de sommets et son nombre
d'arêtes.
Voici trois types d'analyse
asymptotique : l'analyse du cas
pire, l'analyse en moyenne, et l'analyse amortie. Dans tous les cas, on
recherche une borne supérieure de la forme O(f(n)), où f
est le plus souvent un polynôme en n
ou une fonction logarithmique en log n.
·
L'analyse
du cas pire consiste à déterminer une borne supérieure au temps d'exécution d'un
algorithme.
·
L'analyse
en moyenne consiste à déterminer une borne supérieure au temps d'exécution moyen d'un algorithme. Elle suppose la
définition d'un espace de probabilités sur l'ensemble des entrées de
l'algorithme pour une taille d'entrées donnée. Ses résultats dépendent du choix
de l'espace de probabilités.
·
L'analyse
amortie permet d'obtenir des résultats en moyenne sans hypothèse probabiliste.
Elle consiste à déterminer une borne supérieure au temps d'exécution d'une séquence d'opérations algorithmiques
dont le temps d'exécution moyen est obtenu en divisant le temps total par le
nombre d'opérations.
Þ Algorithmes presque toujours corrects
Un algorithme probabiliste joue aux dés : il prend des décisions en
tirant des nombres au hasard, et produit un résultat correct avec une
probabilité arbitrairement proche de 1, mais non égale à un. Ce concept permet
d'obtenir efficacement de très grands nombres premiers.
Þ Enoncé du problème
Entrées
A, un
tableau d'entiers, contenant n éléments,
notés (A[0],...,A[n-1]); X, un entier;
Sortie
Recherche,
s'il existe, du plus petit entier positif i tel que A[i] =
X; sinon n.
Þ Exemple d'algorithme
Tous les éléments du tableau sont examinés jusqu'à
ce qu'un élément A[i]
égal à X soit trouvé. Le résultat est la première valeur de i pour laquelle A[i] = X, ou n si
aucun élément de A n'est égal à X.
Cet algorithme est optimal si aucune information sur le contenu de A n'est connue. Par contre, si les
éléments de A sont rangés en ordre de
croissant, la recherche peut s'effectuer beaucoup plus efficacement, avec un
temps proportionnel à log n. En voici
une réalisation en C :
int
recherche_element_tableau(const int
a[], int n, int x)
//
tableau a[], dimension n, élément recherché x
{int
i;
for (i =
0; i < n; i++)
if
(x = = a[i]) return i;
return
n;
}
Þ Enoncé du problème
Le problème du tri est l'un des plus étudiés
de l'algorithmique. Il existe des algorithmes en temps polynomial très
efficaces pour le résoudre.
Þ Entrées
Un tableau d'entiers A, contenant n éléments, notés (A[0],...,A[n‑1])
Þ Sorties
Une permutation de
{0,...,n‑l} telle que la suite
(A[0],..., A[n‑1]) soit ordonnée par ordre croissant.
Þ Entrées
Un ensemble fini de villes (V1,... ,Vn); pour toute paire de villes (Vi, Vj) un entier positif dij représentant la distance entre Vi et Vj ;
un entier positif B, égal au budget de voyage du représentant de commerce.
Þ Sorties
La réponse à la question : existe‑t'il
une permutation de
{1,...,n} telle que la visite des villes dans l'ordre indiqué par conduit
à une distance totale traversée :
inférieure ou égale à B ? Personne ne
connaît d'algorithme polynomial capable de résoudre le problème du représentant
de commerce, et il y a peu d'espoir que l'on en trouve jamais un. Ce problème
est NP‑difficile.
Enoncé du problème
Þ Entrées
Deux chaînes de caractères, FN et DATA. FN est
la représentation textuelle d'une fonction Pascal de type function FN (var DATA
text) : boolean;
Þ Sorties
La réponse à la question: l'exécution de FN
sur les données DATA est‑elle terminée ?
Il n'existe aucun algorithme pour résoudre ce problème qui est indécidable.
La conception d'algorithmes est un art dont
les techniques s'appliquent à une grande variété de problèmes calculatoires.
Nous pouvons les regrouper en deux catégories: celles qui sont dérivées des
mathématiques, et celles qui sont dérivées de l'informatique.
La méthode dite du diviser pour régner (du latin divide
et impera; divide and conquer en anglais) est l'équivalent algorithmique de
l'induction mathématique.
La méthode de la programmation dynamique consiste à bâtir la solution optimale d'un
problème à partir de solutions optimales de sous‑problèmes.
Les techniques informatiques reposent sur
l'utilisation de structures de données
qui sont des techniques d'organisation de l'information qui en rendent l'accès
efficace possible pour certains types d'opérations. On les utilise souvent sans
le savoir : les fiches d'index d'une bibliothèque, un annuaire
téléphonique en sont deux exemples.
Trois structures de données sont
particulièrement utiles : la liste, la table de hachage, et la file
de priorité.
Dans ce qui suit, le mot problème fait référence à la fois à son sens abstrait de problème
calculatoire et à son sens concret de problème calculatoire spécifié avec un
jeu d'entrées.
Un algorithme fait référence au sens abstrait
à savoir une résolution du problème pour n'importe quel jeu d'entrées.
La taille d'un problème fait référence au sens
concret à savoir la taille d'un de ses jeux d'entrées.
Un sous‑problème
P' d'un problème P est un
problème concret correspondant au même problème abstrait que P dont le jeu d'entrées forme une sous‑partie
du jeu d'entrées de P.
On suppose ici que la taille d'un problème
peut être caractérisée par un entier n,
par exemple la taille d'un problème de tri est donnée par la taille du tableau
d'entiers à trier.
La résolution d'un problème complexe se
ramène, par décompositions successives, à une suite de sous problèmes dont la
résolution est immédiate.
Pour résoudre un problème P de taille n, il est
souvent possible de le décomposer en
sous‑problèmes (P1,...,Pk) de taille plus petite, de façon à ce
que les solutions aux sous‑problèmes (P1,...,Pk)
puissent être combinées efficacement
pour former une solution du problème P.
Selon ce principe, les sous‑problèmes (P1,...,Pk) ainsi
obtenus peuvent être à leur tour décomposés, et ce jusqu'à atteindre des sous‑problèmes
suffisamment petits pour pouvoir être résolus directement.
Ce principe de conception d'algorithmes est le
principe du diviser pour régner.
Un algorithme conçu selon ce principe résout
un problème par application successive de la même méthode de calcul sur des
sous‑problèmes de tailles successivement plus petites. La programmation
de tels algorithmes se fait généralement par récursion, c'est‑à‑dire en utilisant des procédures qui
s'appellent elles‑mêmes. La correction et l'analyse de la performance de
tels algorithmes s'établit généralement par induction.
La décomposition d'un problème en problèmes
d'une complexité moindre conduit à la notion de programmation modulaire.
Les critères de modularité suivants ont été
définis :
Þ Décomposabilité modulaire
Méthode de conception permettant de décomposer
un problème en plusieurs sous problèmes dont la solution peut être recherchée
séparément.
Þ Composabilité modulaire
Méthode
favorisant la production d'éléments de logiciels pouvant être combinés
librement les uns avec les autres pour produire de nouveaux systèmes, comme par
exemple les bibliothèques de programmes.
Þ Compréhension modulaire
Méthode
de production d'éléments dont chacun peut être compris isolément par un
lecteur.
Þ Continuité modulaire
Méthode
de conception telle qu'une petite modification de la spécification du problème
n'amène à modifier qu'un seul (ou peu de) module(s) de l'application.
Þ Protection modulaire
Méthode
de conception telle que l'effet d'une condition anormale se produisant lors de
l'exécution d'un module y reste localisée ou tout au moins ne se propage qu'à
quelques modules voisins.
Þ Unités modulaires linguistiques
Les
différents modules abstraits doivent correspondre à des unités syntaxiques du
langage.
Þ Peu d'interfaces
Tout
module doit communiquer avec aussi peut d'autres que possible (appel, partage
de données).
Le
nombre d'informations échangées doit être aussi réduit que possible.
Þ Interfaces explicites
Quand
deux modules communiquent, les informations échangées doivent être connues et
lisibles dans chacun d'entre eux.
Plusieurs possibilités :
·
le langage peut être imposé à priori
(disponibilité, stratégie d'entreprise, connaissance préalable du programmeur,
etc.). La méthode de résolution choisie devra alors tenir compte de ces
caractéristiques.
·
le choix du langage est ouvert. Il devra
être fait en fonction du type du problème (calcul scientifique, gestion ,
application système, etc.).
Un autre point de vue est qu'un langage de
programmation n'est que le support de la pensée et le programme obtenu doit
être, si possible, indépendant du langage choisi.
Dans tout ce qui suit, le langage utilisé pour
illustrer les exemples sera le C++.
Un métalangage
est un
langage utilisé pour décrire un algorithme. Des conventions sont utilisées pour
décrire les différentes opérations autorisées (affectation, boucle, etc.).
Un programme est destiné à être lu. C'est
pourquoi il est indispensable de le commenter.
Þ Exemple
// Ceci est un commentaire
Þ Situation
Une analyse de la situation du programme est
nécessaire. Dans tout ce qui suit, les situations seront décrites entre les
délimiteurs // .
Þ Clarté
La lisibilité d'un programme est essentielle à
sa maintenance et à son développement. Il faut toujours se rappeler qu'un
programme est destiné avant tout à être utilisé par d'autres et qu'il est
appelé à évoluer. Dans une entreprise, tout programmeur devra, en principe,
être capable de comprendre sa structure et de le modifier.
Le programme devra être présenté de telle
sorte qu'on puisse comprendre, rien qu'en le voyant, sa structure globale. Il
doit être clair, lisible, bien présenté.
Þ Contre‑exemple
x = a;
y = b;
x = x‑y;
y = y‑x; x = y‑x; y = x‑y; // que valent (x,y,z) après exécution de
l'instruction
Þ Nom des objets
Les
noms des objets (variables, fonctions, procédures) doivent être
appropriés.
Þ Exemple
float
r; // que représente
r ?
float
rayon // c'est mieux
Þ Identification des procédures
Chaque procédure ou fonction doit être
identifiée par une en tête qui spécifie son action, ses arguments et leur
domaine de validité, ses effets de bord et ses limitations. Ces entêtes doivent
respecter un format uniforme permettant l'extraction automatique d'un manuel de
référence à partir du texte du programme.
Les variables devront être regroupées par type,
thèmes, etc.
Des commentaires devront indiquer :
·
la méthode de résolution choisie,
·
la description des conventions utilisées
pour nommer les variables,
·
les fonctions et les procédures
utilisées,
·
les bibliothèques appelées,
·
les éventuelles astuces de programmation
(à éviter en principe).
Þ Exemple
//
programme de résolution d'une équation du 2° degré
//
coefficients de l'équation a, b ,c à valeurs réelles
//
solution réelles et complexes
//
Programmeur : tartempion le 10 Janvier 2018
//
variables utilisées
//
float a, b ,c ;
//
etc.
Tout langage de programmation est défini par
l'utilisation de règles très précises que le programmeur devra respecter de
façon impérative. Certains langages sont très rigoureux de telle sorte que le
programmeur n'ait aucun choix possible à part le bon (langage PASCAL).
D'autres sont plus permissifs (langage C).
Chaque langage a ses propres règles de
grammaire.
Þ Syntaxe
La syntaxe
d'une instruction
est son mode d'emploi. Elle est vérifiée par le compilateur ou l'interprète
de commandes qui procède à une analyse
syntaxique préalablement à toute exécution.
Þ Sémantique
Sa sémantique correspond à l'action qu'elle exécute.
Pour qu'un programme fonctionne correctement,
les deux conditions suivantes sont nécessaires
et non suffisantes : il doit être correct sur les plans syntaxique et sémantique car certaines
instructions peuvent être correctes sur le plan syntaxique et fausses sur le
plan sémantique.
Þ Exemple
En C, l'instruction
if (i = 1)
est syntaxiquement correcte et sémantiquement fausse.
Le langage est constitué par un ensemble de
mots clés qui représentent les instructions autorisées. Ils ont une syntaxe d'utilisation définie par sa grammaire.
Þ Exemple
La liste ci-dessous récapitule pratiquement la
totalité des mots clés du langage C.
Þ Déclarations de type
char double enum float int long short signed sizeof struct typedef union unsigned void
Þ Déclarations de la classe de mémorisation
auto extern register static const volatile
Þ Structures de contrôle
break case continue default
do
else
for goto if return switch while
Les différents objets que l'on manipule
peuvent être (liste non exhaustive) :
·
des nombres (entiers, relatifs, réels,
complexes),
·
des caractères (français, allemand,
russes, etc.),
·
du son,
·
de l'image,
·
etc.
Ils ont une représentation digitale interne en fonction des déclarations de
type qui la masquent.
Tout langage de programmation permet de
manipuler des objets dits "de base". Ainsi, le C permet de manipuler
des objets scalaires (entiers, réels, caractères), des vecteurs sous forme de
tableaux. A chacun de ces objets est associé un ou plusieurs types :
objet déclaration de type
entier naturel int, short, unsigned
entier relatif int, short, signed
rationnel float, double
réel float,
double
caractère char
vecteur tableau
etc.
A partir des objets de base, il est possible
de construire des objets complexes, par exemple les tableaux. Rappelons qu'un tableau est un ensemble d'objets de même type stockés consécutivement en
mémoire dont chaque élément est accessible par un indice relatif au premier
élément.
Þ Exemple
int
a[100]; // un tableau de 100 entiers
Il est également possible de construire des
objets de types composites appelés enregistrements
ou structures.
Þ Exemple
La structure
constituée des informations nom, prenom,
adresse permet de définir un individu. D'autres informations peuvent être
ajoutées.
struct individu {char nom[20]
; char prenom[20] ; char adresse[50] ;};
struct complexe {float x
; float y};
Les opérateurs du langage permettent de faire
des opérations sur les objets de base. On distingue :
·
les opérateurs arithmétiques +, ‑,
*, /
·
les opérateurs logiques et, ou ,
non,
·
les opérateurs relationnels, qui
permettent de faire des comparaisons entres objets.
Certains langages permettent de redéfinir le
comportement des opérateurs. Ainsi, il est possible en C++ de (re)définir
l'opérateur + pour qu'il permette d'additionner des matrices. Ce principe est
appelé la surcharge des opérateurs.
Les opérations d'entrée/sortie permettent de
gérer les échanges d'informations entre la mémoire centrale et les
périphériques. Ainsi, il existe des instructions permettant de faire la saisie, l'affichage, l'écriture ou
la lecture de fichiers.
Þ Exemple
int main(void)
{int a ; //
définition de a
cin >> a; // saisie de l'entier a
cout << "a =" << a
<< endl; // impression de
l'entier a
}
Un programme est un ensemble d'instructions
(élémentaires ou complexes).
Une instruction porte sur une ou plusieurs
variables. Elles opère sur des variables
ou des expressions en utilisant des opérateurs.
En C++, toute instruction doit se finir par le
terminateur ;
On distingue les instructions exécutables et non exécutables.
Þ Exemple
int a, b; // non exécutable
en C , exécutable en C++
float c = 45.67;
a = 12; //
exécutable
b = a+c;
if ((a > 1)
&& (b < 5)) ....; else ...;
Une instruction peut appeler des procédures ou
des fonctions, prédéfinies ou non.
Þ Exemple
x = f(a); // appel de la fonction f
g(y); // appel de la procédure g
Les caractères autorisés dans un langage sont
définis par un alphabet. En C, il est possible d'utiliser les lettres minuscules, majuscules,
les caractères alphanumériques, et certains caractères spéciaux pour constituer
les variables symboliques. L'utilisation des mots clés pour définir les variables symbolique est
interdite (en PL/1, c'est autorisé). Enfin, les lettres minuscules et
majuscules sont différentes.
Þ Exemple
int a = 1;
float A = 6.78;
char chaine[128] =
"bonjour";
char
ceci_est_une_longue_chaine[128] =
"anticonstitutionnellement";
La définition
d'une
variable lui donne naissance. Selon la grammaire utilisée, il est obligatoire
(PASCAL ou C) ou facultatif (FORTRAN) de définir préalablement les variables
utilisées.
A chaque objet est associée une variable symbolique du programme, accessible par un nom
symbolique, qui devra suivre les règles de construction du langage. C'est en
général un ensemble de caractères alphanumériques.
Þ Exemple
// définition de variables
int i; //
l'entier i
float a,b; //
deux réels a et b
char chaine[10] = "bonjour"; // une chaîne de caractères
Une déclaration
est
indicative. Elle peut être obligatoire dans certaines situations. Ainsi, la
déclaration :
float
somme(int, int);
indique que somme est une fonction à valeur
réelle avec deux variables entières. Une déclaration
est aussi appelée prototype, maquette, signature.
Une instruction d'affectation comporte deux
membres : le membre de gauche et le membre de droite, séparé par l'opérateur d'affectation. Le membre de
droite précise la valeur à affecter à la variable de gauche.
Þ Symboles d'affectation
: = PASCAL
= C++,
FORTRAN
En C, le membre de droite est appelé Rvalue et celui de gauche Lvalue.
Þ Exemple
b = 3;
pi = 3.14;
c = b + pi;
Þ Remarques
1°) Considérons les deux cas suivants
x = a; // on affecte à x une valeur
constante
x = x+1; // x est calculé à partir de son ancienne
valeur
2°) L'affectation
réalise une transformation de l'état du programme. Elle en réduit la clarté.
Þ Exemple
x = a;
y = b;
x = x‑y;
y = y‑x; x = y‑x; y = x‑y;
Que valent (x,y) après exécution de ces
deux instructions ?
3°) L'affectation
provoque une modification des situations des variables.
// situation de
départ
x = b; situation
1 : porte sur x
x = x+1; situation
2 : porte sur x‑1
Une instruction peut être simple ou complexe, selon
les variables et les opérateurs manipulés. Certaines instructions deviennent illisibles
à cause de leur complexité.
On en distingue plusieurs niveaux.
Þ La formule simple
Exemple: calcul du salaire brut. Soit h le salaire horaire, t le nombre
d'heures de travail. Alors
b = h 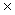 t;
t;
Þ Le résultat intermédiaire
On souhaite ici calculer le salaire net b.
Soit p le pourcentage de retenue.
b = h 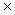 t ‑ h
t ‑ h 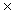 t
t 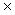 p;
p;
Il est judicieux de
procéder en deux instructions :
aux = h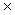 t;
t;
b = aux (1‑p);
(1‑p);
ce qui évite de
calculer deux fois l'expression h t.
t.
Une action est un ensemble d'instructions élémentaires. Le concept d'instructions généralisées ou bloc permet de les représenter.
En C, un bloc
est représenté par des accolades ouvrantes et fermantes {...}.
Þ Exemple
if (a > 0) {traitement}
else {autre traitement}
Une fonction s'apparente à une fonction
mathématique. Elle permet de calculer le résultat
d'opérations portant sur des variables scalaires, transmis en argument.
Þ Définition
Une fonction est une application
(E1 X E2 X ... X En)
D
où (Ei)i=1,n sont les domaines de définition des arguments de la fonction et D
est le domaine de valeur du résultat.
Les types d'arguments de fonctions autorisés
sont les types prédéfinis scalaires entier, réel, caractère, pointeur. Le type
du résultat d'une fonction est scalaire.
Þ Retour du résultat
Le résultat d'une fonction peut
être transmis à l'expression appelante par l'instruction return.
Þ Exemple
int main(void)
{int x = 2,
y = 3;
printf("somme = %d\n", somme(x,y)); // appel de la fonction somme
}
// corps de la fonction
somme
int somme (int a; int b)
{return (a+b);}
Il existe deux méthodes de transmission des
arguments :
Þ Transmission par adresse
L'argument effectif est transmis directement par son adresse. La fonction appelée travaille donc avec la variable
originelle. La grammaire du langage C utilise explicitement les pointeurs pour effectuer ce mode de
transmission.
Son inconvénient est le suivant : la
pérennité des variables transmises n'est pas garantie puisque elles sont
modifiables par la fonction appelée. Or, le programmeur peut souhaiter modifier
certaines variables seulement. Le problème est de garantir la perrenité des
autres variables transmises à la fonction. En effet, une erreur d'indice dans
un tableau transmis risque de provoquer l'écrasement des variables stockées
avant ou après l'espace alloué au tableau. Un autre mode de transmission a donc
été défini.
Þ Transmission par valeur
L'argument effectif est sauvegardé dans une pile d'exécution. Une variable auxiliaire, initialisée avec cette valeur de l'argument
d'appel, est utilisée lors de l'exécution de la fonction. La variable initiale
n'est donc pas accessible est n'est donc jamais modifiée.par la fonction
appelée. Ce mode est indispensable pour la gestion interne de la récursivité.
Il garantit de plus l'intégrité dans la fonction appelante des variables transmises par valeur.
L'exemple suivant met en évidence la nécessité de pouvoir utiliser ces deux
modes.
!
Exemple : procédure de
permutation de deux variables avec une transmission par valeur.
int main(void )
{int a = 1 ,b = 2;
void swap
(int, int); // prototype
de swap
printf( " a= %d b= %d\n",
a,b);
swap(a,b); // appel de swap
printf( " a= %d b= %d\n",
a,b);
return(1);
}
void swap (int x, int y) //
définition de la fonction swap
{int aux; //
corps de la fonction swap
aux
= x; x = y; y = aux;
}
//
résultats
a=
1 b= 2
a=
1 b= 2
La bibliothèque C est constituée d'un grand
nombre de fonctions, appelables depuis n'importe quel programme C. Ainsi, la
fonction qsort effectue un tri d'un
tableau selon un algorithme de Quick sort.
Son prototype est le suivant :
#include < stdlib.h >
void qsort(void *tableau, size_t n, size_t t,
int(*comparaison)(const void *arg1, const void *arg2));
Þ Description
La variable tableau pointe sur la base du tableau de n éléments, chacun est composé de t octets, à trier par ordre croissant. En général, tableau est un
tableau de pointeurs et t la taille
des objets pointés.
La variable
comparaison est un pointeur sur une fonction de comparaison de deux
composantes du tableau. Elle retourne 0 si les deux éléments comparés sont
identiques, un nombre positif si l'élément pointé par arg1 est supérieur à arg2, un nombre négatif
s'il est inférieur.
Une procédure
représente
une action, éventuellement très complexe. Par exemple, inverser un système
linéaire. Le programme ci‑dessous est constitué d'un programme principal
qui appelle les procédures nécessaires à la solution du problème.
Þ Exemple
{// début du programme
float a[100][100], b[100],
x[100];
// appels des procédures
d'initialisation
initialiser_tableau(b);
initialiser_tableau(x);
initialiser_matrice(a);
// inversion du système
inverser(a,x,b);
affichage(x);
...
// fin du programme
principal
// définition des
procédures
void initialiser_tableau(float x[])
{// code de la procédure }
...
void affichage(float x[])
{// code de la procédure
d'affichage }
Tout programme doit être constitué d'un
programme principal au moins qui en est le point d'entrée. Il est constitué de
définitions, déclarations, blocs, et éventuellement des appels de fonctions et
des procédures.
En C, le programme principal est toujours
constitué d'au moins une fonction : la fonction main.
Þ Exemple1
// programme d'impression de coucou c'est
moi
int main(void)
{cout << "coucou!!
c'est moi" << endl;} //
instruction d'impression
Tout programme C++ doit respecter les règles
suivantes :
int main(void) //
point d'entrée de la fonction main
{// début de la fonction main()
définition(s) et
déclaration(s) obligatoires de toutes les variables utilisées
initialisation (recommandée) des
variables
instructions du programme
fin de la fonction main()
}
Définition des éventuelles
fonctions et/ou procédures appelées.
L'ordre de la
définition des différentes fonctions est arbitraire.
Les structures
de contrôle du programme permettent d'en maîtriser l'exécution. On distingue les tests et les boucles.
Un test permet de sélectionner une partie du
programme en fonction de critère à définir. Leur forme générale est la
suivante :
Þ Forme générale
si (condition logique)
alors action1
sinon action2
is
Þ Exemple
// Plafonnement de la
sécurité sociale
b = h * t;
r = b * p;
if
(r > max) r =
max ;
n = b ‑ r;
Il est possible d'imbriquer des tests et de
faire des branchements multiples selon la forme :
switch(valeur_de_a)
{ case 1 : action1;
case 2 : action2;
...
défault : action_par_défaut;
}
Forme générale : aller_à
L'exécution de cette instruction ne modifie
pas l'état du programme.
si condition logique alors aller_à
Þ Exemple1
Calcul de x
imprimer x
lire x
si x > 0 alors aller_à impression
sinon x = ‑x
is
impression : imprimer
x
!
Exemple2 : Résolution d'une équation
du second degré
On se donne a,b,c réels. On cherche x solution
de l'équation ax2 + bx + c = 0. La solution est bien connue.
Soit delta = b2 ‑ 4ac.
(Notation racine : rac).
si delta 0 alors
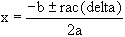 is
is
si delta < 0 alors
pas de solution réelle is
Algorithme N°1
Lire a,b,c
CALCUL : calculer delta =
b2 ‑ 4ac
si delta < 0 aller_à // delta négatif
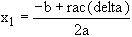
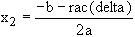
aller à Fin du calcul.
// Delta négatif
Imprimer "pas de solution".
Fin du calcul
!
Remarque
Cet algorithme est mauvais, car il ne tient
pas compte des cas particuliers. Que se passe t‑il si a = 0 et
b 0, c quelconque ou si a = b = 0, c 0 ou
c = 0. Nous en déduisons l'algorithme suivant, écrit dans un langage
très voisin de BASIC
10 lire a,b,c
2O si a =
0 aller_à 200
30 ' cas a 0
40 delta = b*b ‑ 4*a*c
50 si delta > 0
aller_à 100
60 si delta
négatif aller_à 400
70 ' delta = 0'
80 x = ‑b/(2*a)
90 aller_à
500
100 ' delta = positif
110 x1 = (‑b +
rac(delta))/(2*a)
120 x2 = (‑b ‑ rac(delta))/(2*a)
130 aller_à
500
200 ' a = 0'
210 si b =
0 aller_à 300
220 x = ‑c/b
230 aller_à
500
300 si c =
0 aller_à 330
310 imprimer 'impossible'
320 aller_à
500
330 imprimer 'impossible'
340 aller_à
500
400 imprimer "pas de racine réelle"
500 FIN
Quelques mots sur ce programme :
·
il est peu lisible (c'est un euphémisme).
·
il n'est pas certain qu'il fonctionne.
·
tous les cas possibles ont‑ils été
traités ?
·
enfin, à quelles étiquettes théoriques
les renvois font‑ils référence?
Bref, un carnage.
Nous allons maintenant réécrire cet
algorithme, en supprimant tous les branchements. On y gagnera en lisibilité, en
clarté, en efficacité. On obtient l'algorithme définitif :
Algorithme 3
Début
Lire a,b,c.
si a = 0 alors
si b 0 alors 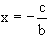
sinon
si c = 0 alors
indétermination sinon impossibilité is
is
sinon
delta =
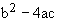
si
delta = 0 alors
x =
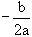 ; imprimer "racine double"
; imprimer "racine double"
sinon
si delta < 0 alors
imprimer "pas de racine réelle"
sinon
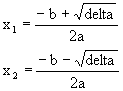
imprimer
x1, x2
is
is
is
Fin du calcul
Les différentes parties du programme
correspondant chacune à une action différente apparaissent nettement.
La notion de bloc des langages de programmation structurés permet de mettre ces
actions en évidence.
On considère le problème de l'édition du
bulletin de paie des employés d'une entreprise.
Þ Méthode 1
Calcul
de la paie du 1er employé
Edition
Calcul
de la paie du second employé
Edition
..
Calcul
de la paie du dernier employé
Edition.
C'est
long surtout s'il y a 10.000 employés.
Þ Autre méthode
Du
1er jusqu'au dernier employé de la firme, faire
calcul
de la paie
édition
Recommencer
Ce
qui est équivalent à la séquence
Nombre
total d'employés : nombre
Pour n = 1 jusqu'à nombre faire // marque
de début de boucle
calcul de la paie de l'employé n // corps
de la boucle
édition
FinFaire // marque
de fin de boucle
Une structure d'itération permet de répéter l'exécution d'une séquence d'instructions un certain
nombre de fois (fixé ou non).
Toutes les actions situées entre la marque de
début de boucle et la marque de fin de boucle constituent le corps de la boucle
dont il est nécessaire de prévoir l'arrêt. C'est le test de fin de boucle. Nous allons mettre en évidence son importance dans les exemples ci‑dessous
!
Exemple 1
n =
1
calcul : calculer
la paie de l'employé n
Edition
n =
n+1;
si
n < nombre alors aller
en calcul sinon fin du calcul is
Ici,
le test de fin de boucle est effectué à
la fin de la boucle.
!
Exemple 2
n =
1
test : si n > nombre alors Fin du travail
sinon
calculer la paie de n;
édition
n = n+1
aller à test
is
Le test est ici effectué en début de boucle.
Il vaut mieux que le test de fin de boucle
soit effectué en début de boucle. En effet : si nombre = 0 que se passe t‑il ?
algorithme n°1 : la boucle s'exécute
au moins une une fois.
algorithme n°2 : arrêt
immédiat .
Syntaxe générale
Pour valeur_initiale à valeur_finale faire
instruction(s) ou bloc
FinFaire
Application au cas précédent
Pour n = 1 jusqu'à nombre faire
calculer la paie de l'employé n
édition
FinFaire
!
Remarques
1) Le nombre d'itérations est connu (fixé
à l'avance).
2) La variable
de contrôle n est incrémentée à chaque itération et comparée avec la
variable nombre. Un bon compilateur
l'évalue à chaque début de boucle.
3) Il est évident qu'il ne faut pas modifier n à l'intérieur de
la boucle.
!
Exemple 1
Imprimer les nombres, leurs carré de 1 à 100
Pour i = 1 jusqu'à 100 faire
imprimer
i, i*i
FinFaire
Forme générale
Tant que < condition logique > Faire
< groupe
d'instructions >
FinFaire
!
Exemple 1
Calcul de exp(x)
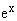 =
= 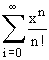
Le calcul à l'infini étant impossible, il faut
définir ici un test d'arrêt. Soit
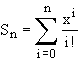
Le calcul est arrêté dès que 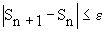 , fixé.
, fixé.
Þ Algorithme
Initialisation
Tant que d > faire
calcul
de Sn+1
calcul
de d = 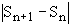
FinFaire
Þ Problème
Que
se passe t‑il si l'algorithme ne converge pas et que le
test d'arrêt n'est pas vérifié (d n'est jamais < ) ?
Il peut donc y avoir un problème lors de l'arrêt d'une boucle et il faut
toujours le prévoir (ici, ajouter un compteur d'itération maximum).
Þ Remarque
si dès le départ, D < , il n'y
a pas de boucle.
!
Exemple 1 : programmation de e
à partir de la formule 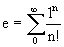
La convergence est rapide (7 itérations)
#include <iostream.h>
int main()
//
calcul itératif de la valeur de e = 2.71828....
// algorithme est très efficace (7 itérations =
bon résultat)
{double epselon ;
cout
<< "indiquez la valeur de epselon : ";
cin
>> epselon; // précision du
calcul
int
factorielle(int); // prototype (ou
maquette), retour entier, 1 argument
entier
double
somme=0;
double
valeur;
//
initialisation de la boucle
int
n=0;
valeur=1./factorielle(n); // appel
//
boucle Tant que (condition) Faire
// .....
//
FinFaire
while
((valeur > epselon) && (n <20))
{
somme+=valeur;
n=n+1;
valeur=1./factorielle(n);
}
cout
<< "nombre d'itérations : " << n << " valeur de e approchée : "<<
somme << endl ;
printf("e = %16.13g\n",somme);
}
int
factorielle(int p) // fonction factorielle définie récursivement
{if
(p==0) return 1;
else return
factorielle(p-1)*p;
}
!
Exemple 2 : calcul de p par la formule 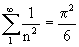
// REMARQUE
// Cet algorithme est peu performant : 46000
itérations pour 5 décimales
// Complexité importante pour un résultat
minable
#include <iostream.h>
#include <math.h>
int main()
{int carre(int); // MAQUETTE ou un PROTOTYPE de la fonction carre (retourne un
int, 1 argument
// int
double
epselon ;
cout
<< "indiquez la valeur de epselon : ";
cin
>> epselon; // précision du
calcul
double
somme=0;
double
valeur;
//
boucle de calcul
int
n=1;
valeur=1./carre(n); // APPEL DE
LA FONCTION AVEC L'ARGUMENT EFFECTIF CARRE
cout
<< "nombre maximum d'itérations : ";
int
iter;
cin
>> iter ;
while
((valeur > epselon) && (n < iter )) // boucle de calcul
//
nombre d'itérations inconnu à priori
donc borné par un maximum autorisé
{somme+=valeur;
n=n+1;
valeur=1./carre(n);
}
double
pi = sqrt(6*somme);
cout
<< " nombre d'itérations : " << n << " pi =
" << pi << endl;
}
//
définition de la fonction
int
carre(int p) // fonction de
calcul du carré d'un nombre fourni en argument (ici p)
{return(p*p);}
REPETER
instruction(s) ou bloc
jusqu'à < condition
logique >
Exemple
n = 1
REPETER
imprimer n, n*n;
n = n+1;
jusqu'à n > 100
Þ Remarques
1) La boucle
REPETER est toujours exécutée au moins une fois puisque le test de fin de
boucle est effectué en fin de boucle.
2) Equivalence
des structures TANT QUE et REPETER
Tant que < condition > faire si
condition alors répéter
Instruction(s) Instruction(s)
FinFaire jusqu'à
is
Voici une méthode de construction de programme
basée sur le raisonnement par récurrence.
·
on sait le faire pour n petit.
·
on suppose qu'on sait le faire pour n‑1.
·
on montre que c'est vrai pour n.
En effet, un programme procède par
approximations successives pour trouver un résultat. A chaque instruction
exécutée, il se rapproche en principe un peu plus de la solution.
La méthode proposée est la suivante :
·
proposer une situation générale
invariante pour la boucle (hypothèse de récurrence),
·
si c'est
fini alors sortir,
·
se rapprocher de la solution en conservant l'hypothèse de
récurrence, ou en la rétablissant,
·
initialiser le processus avec des valeurs
initiales compatibles avec le problème et satisfaisant l'hypothèse de
récurrence.
a) n! = fac(n)
Þ Hypothèse de récurrence
A
l'étape i, on connaît fac(i)
Boucle : si i = n alors Fini is
// à l'étape
i+1
fac(i+1) =
(i+1)*fac(i)
i = i+1 // rétablir l'hypothèse de
récurrence
aller_à Boucle
initialisation : i =
1; fac(i) = 1
b) xn =
P(x,n)
Þ Hypothèse de récurrence
On
connaît (x1, ...,xn) =
P(x,1) ..., P(x,i)
Boucle : si i > n alors Fini
sinon
P(x,i+1) = x*P(x,i)
i = i+1
aller_à
Boucle
is
Initialisation : P(x,1) =
x
Soit (a1,...,an) une suite d'entiers
naturels, dans un ordre quelconque.
Il faut la réordonner de la façon
suivante :
·
on classe à gauche tous les entiers de la
liste congrus à 0 modulo 3,
·
on classe à droite tous les entiers de la
liste congrus à 2 modulo 3,
·
on classe "au milieu" tous les
entiers de la liste congrus à 1 modulo 3.
Þ Hypothèse de récurrence et notations
Soient :
i l'indice du 1er élément congru à 1 mod 3,
j l'indice de l'élément courant, que l'on
va trier,
k l'indice du 1er élément congru à 2 mod 3.
Avant le tri, à l'étape j, on est dans la
situation suivante :
i‑1 nombres congrus à 0 modulo 3 sont
triés, en place,
j‑i nombres congrus à 1 modulo 3 sont
triés, en place,
n‑k+1 nombres congrus à 2 modulo 3
sont triés, en place.
tableau ( 0, 1, x, , 2 ...)
indice 1 i j k n
états triés triés non triés triés
Soit r = reste de la division de aj mod(3) = mod(aj, 3).
1ère analyse
si r = 1 alors aj est à sa place is
si
r = 2 alors permuter (aj, ak‑1) is
si
r = 0 alors permuter (ai, aj)is
Méthode à utiliser
1) Proposer
·
une hypothèse de récurrence,
·
une situation générale,
·
un invariant de boucle.
Cette hypothèse est de la forme : on
a fait une partie du travail. C'est la phase constructive.
2) Voir si
c'est fini
si j = k alors FINI is
3) Se rapprocher
de la solution en préservant l'hypothèse de récurrence;
On considère aj, nouvel élément de la liste. Il y a 3 situations à
évaluer :
(i) r =
1 : l'élément est à sa place.
si r = 1 alors
j = j+1; SUIVANT is recommencer
en tête de boucle
// l'hypothèse de récurrence reste vérifiée
puisque l'on a rien fait
(ii) déplacer l'élément
a) r = 0 : dans ce
cas, on permute (ai, aj) . Ainsi, on classe aj sans perturber le tri.
0 1 1 2
1 i j k n
Il faut rétablir l'hypothèse de récurrence en
incrèmentant i et j. Donc
si r = 0 alors ech(ai, aj); //
modifie l'hypothèse de récurrence
i = i+1; j = j+1;
SUIVANT // rétablit l'hypothèse de récurrence
is
b) Dernier cas : r =
2
On procède comme dans le cas
précédent : on échange ak‑1
inconnu avec aj connu.
ech(ai, ak‑1); k = k‑1
Il reste à initialiser le processus
Les valeurs initiales à choisir doivent
respecter l'hypothèse de récurrence. Il faut vérifier les conditions intiales.
Le nombre d'éléments en place au départ est tel que :
i-1 = 0
i = 1
j-i = 0
j = i = 1
n-k+1 = 0
k = n+1
!
Remarques
a) A chaque pas de
boucle : d(j,k) diminue de 1.
b) Le nombre d'échanges est inférieur à n
par cette méthode.
c) Il faut rechercher une bonne hypothèse
de récurrence.
d) Il ne pas forcément rechercher la
meilleure.
e) Autre méthode : boucle TANT QUE
Le programme final obtenu est le
suivant :
!
Initialisation
k = n+1; i = 1;
j = 1
!
Tri
Tant
que j k
Faire
r = mod(aj,3)
si r = 1 alors
j = j+1; is // aj
est à sa place donc au suivant
si r = 2 alors
permuter (aj, ak‑1); k = k‑1; is // permuter
ak‑1, aj
si
r = 0 alors permuter (aj, ai); i = i+1; j = j+1 is
FinFaire
Supposons que l'on ait deux boucles imbriquées
de la forme suivante :
Pour i = 1 à n faire
pour j = 1 à p faire
si < condition
logique > alors sortir
de la boucle 2 is
FinFaire 2
FinFaire 1
On écrira :
sortir
de la boucle 2 par exit 2.
Premières leçons de
programmation : J. ARSAC - 1980 Cedic‑Nathan
The science of
programming : DIJKSTRA - 1981 Digue
PASCAL ‑ Manuel de
l'utilisateur : Kathleen JENSEN ‑ Niklaus WIRTH
The art of programming ‑ Donald
Knuth (1968)
Some notes on structure programming ‑ Edger
Dijkstra
A discipline of programming ‑ Edger
Dijkstra
The science of programming ‑ D.
Gries (1981)
Le langage C : Kernighan &
Ritchie (1988)
·
La couche
objet constitue une abstraction entre l'implémentation des
applications et leur utilisation, apportant ainsi un meilleur confort de
programmation.
·
Elle intègre le concept traditionnel de modularité.
·
L'encapsulation des données leurs garantit une meilleure
protection donc une plus grande fiabilité des programmes.
Þ Philosophie objet
L'analyse des problèmes se présente d'une
manière plus naturelle si l'on considère séparément les données et leurs propriétés :
·
les données
constituent les variables,
·
les propriétés
les opérations qu'on peut leur appliquer.
De ce point de vue, les données et le code sont
logiquement inséparables, même s'ils sont gérés dans différentes régions de la
mémoire.
Ces considérations conduisent à la définition
d'un objet : ensemble de données sur lesquelles des procédures,
appelées méthodes, peuvent
opérer. La programmation d'un objet étant réalisée à partir de ses données et méthodes, elle semble plus logique que la programmation procédurale
les méthodes étant partagées et les
données séparées.
4.2 Classes
Þ Objet
Un objet est un "paquet"
logiciel constitué d’un ensemble de procédures appelées méthodes et de données associées.
Ces objets peuvent être définis et gérés
indépendamment les uns des autres.
Þ Messages
Les objets peuvent échanger des informations
sous forme de message que le langage Simula définit comme le résultat de
l'application d'une méthode opérant sur
un objet. L'objet à l'origine du message en est l'émetteur et l'objet destinataire le récepteur.
Þ Classe
·
Une classe est constituée d'un ensemble d'objets
appelés instances, dotés de
propriétés communes représentées selon à un modèle
abstrait.
·
L'instanciation est une relation d'appartenance d'un objet à une classe donnée. Chaque
instanciation provoque une allocation de mémoire dont l'initialisation est réalisée par
une méthode appelée constructeur. Lorsqu'elle est détruite, une méthode conjuguée est exécutée : le destructeur. Le programmeur peut redéfinir ses propres constructeurs et
destructeurs.
·
La classe définit la structure des données, appelées champs, variables d'instance, ou données membres de la classe (aspect statique) dont seront constitués les objets correspondants.
·
Les opérations
sur les instances sont réalisées par
les méthodes ou fonctions membres de la classe (aspect dynamique).
Þ Définition
L'héritage permet de transmettre les propriétés d'une classe (la classe mère ou classe de base) à une autre classe (classe
fille ou classe dérivée) ce qui permet la réutilisation par la classe fille des fonctions et/ou des données membres de la
classe mère accessibles.
Þ Hiérarchie de classes
Les classes peuvent être organisées selon un modèle
arborescent pour intégrer des cas de plus en plus particuliers au modèle générique de base.
Þ Classes virtuelles (ou
abstraites)
Une classe
virtuelle est une classe sans possibilité
d'instanciation d'objet, créée pour définir les données membres et les méthodes
associées qui s'appliqueront à des classes de plus bas niveau dans la hiérarchie de classe.
Þ Approche orientée objet
Les logiciels
orientés objet modélisent un système qui se veut une meilleure
représentation du monde réel.
Þ Types abstraits
·
La plupart des langages de programmation
permettent au programmeur de définir ses propres types de données abstraites, en
complément des types prédéfinis. Les
langages orientés objets permettent en outre d'utiliser les opérateurs
classiques sur ces données abstraites par surcharge.
·
De nouveaux types abstraits sont définis par création de nouvelles classes.
Þ Extension de la notion de type du langage C en langage C++
·
La couche
objet constitue l'apport essentiel du
langage C++ au langage C.
·
En langage C++, les notions de type et de classe sont identiques, les notions intégrées au
langage C++ ayant transformé en classe le typage traditionnel des données du langage C.
·
Le programmeur peut définir de nouvelles classes donc de nouveaux types.
!
Exemple
Les types prédéfinis char, int, double, etc. représentent l'ensemble des
propriétés des variables de ce type et en constituent la classe avec les
opérateurs arithmétiques comme méthodes.
L'addition devient un opérateur pouvant opérer sur des instances de la classe
entier retournant un objet de la classe entier.
Þ Utilisateur et programmeur
Les règles
d'accès aux objets doivent être différentes pour l'utilisateur et le
programmeur car il y a une distinction entre l'utilisation d'un objet et son implémentation :
·
l'utilisateur d'un objet n'a pas à connaître
sa représentation interne; pour lui, seul compte son comportement (principe de la boîte noire).
·
Le programmeur ne peut ignorer la façon
dont une instance d'un type donné est représentée en binaire car la plage des
valeurs possibles est essentielle. Ainsi, un mauvais choix de type de données
abstraites à conduit au crash du premier vol de qualification du lanceur Ariane
5.
Pour accroître
la fiabilité des programmes, les données peuvent être protégées pour que seules les méthodes autorisées puissent y accéder. En cas d'erreur, seules ces
dernières doivent être vérifiées.
Les méthodes constituent une interface d'accès entre les
instances et l'utilisateur de l'objet qui n'a donc pas à
savoir comment elles sont gérées. L'implémentation est alors masquée.
Les avantages sont immédiats :
·
l'utilisateur ne risque pas de provoquer
des erreurs d'exécution par modification des données,
·
d'interface d'accès standard, l'objet est
réutilisable dans un autre programme,
·
le programmeur peut modifier
l'implémentation interne de l'objet sans réécrire tout le programme, les
méthodes utilisées devant conserver les mêmes identificateurs et arguments.
Les logiciels orientés objet sont conçus par
assemblage de différents modules
indépendants qui encapsulent les données et les comportements.
Þ Encapsulation
On appelle encapsulation le regroupement des données
et de leur comportement.
L'encapsulation encourage la dissimulation
d'informations car le programmeur ne peut accéder à une instance qu'au travers
des méthodes autorisées ce qui protège les données des objets extérieurs.
L'encapsulation permet de limiter les
modifications au seul objet concerné.
Les types prédéfinis des langages C ou Pascal
garantissent l'abstraction et l'encapsulation des données prédéfinies (par exemple le type float en C). Par contre, la complexité de la grammaire de ces
langages ne permet pas ou n'incite pas
le programmeur à définir des types
utilisateur garantissant ces mêmes propriétés.
·
En langage C, les règles d’initialisation
des variables sont complexes voir confuses. Ainsi, les variables statiques sont par défaut toujours initialisés, les variables automatiques non.
·
Ces règles sont appliquées sur des
tableaux de façon fantaisistes par les éditeurs de logiciel ce qui nuit à la portabilité et à la robustesse des programmes.
Þ Constructeur et destructeur
·
Une méthode d’initialisation, appelée constructeur, est définie par défaut ou peut être redéfinie par le programmeur.
Elle est toujours appelée implicitement
ou explicitement lors de
l'instanciation d'une variable de la classe.
·
La mémoire allouée par un constructeur est toujours récupérée par
une méthode de destruction appelée destructeur.
Þ Polymorphisme
On appelle polymorphisme la faculté de dissimulation des
détails de l'implémentation à travers une interface d’utilisation commune qui
simplifie la communication entre objets.
Þ Surcharge
·
La surcharge
d'une fonction permet de donner le même identificateur à plusieurs fonctions
réalisant une action similaire sur des objets d'un type différent.
·
La surcharge
d'un opérateur permet d'étendre ses caractéristiques d'origine à des opérandes d'un
type différent.
·
La surcharge est donc une forme de polymorphisme.
·
La surcharge peut s'exécuter en mode :
à
statique (early binding) : la
détermination de la fonction ou de l'opérateur à exécuter est effectué à la compilation.
à
dynamique (dynamic binding ou late binding) : le choix de la
fonction ou de l'opérateur à exécuter est effectué à l'exécution comme avec les méthodes
virtuelles.
!
Exemple de fonction surchargée
Soit la classe des figures géométriques
(cercles, carrés, rectangles, trapèzes). La méthode surchargée dessiner opère sur les instances de la
classe… et dessiner un cercle est différent de dessiner un carré.
!
Exemple d'opérateur surchargé
Les opérateurs arithmétiques traditionnels du
langage C sont surchargés :
·
l'opérateur arithmétique + est utilisé
sur des opérandes de type int, float,
double,
etc..
·
En langage C++, cet opérateur surchargé
peut opérer sur des nombres complexes, des matrices, etc.
Þ Généricité
Un (unique) code générique peut opérer sur des données de
différent type.
!
Exemple de code générique
Les
macros définitions de type fonction du préprocesseur C.
Þ Surcharge et généricité
Il ne faut pas confondre surcharge et généricité :
·
Une fonction surchargée utilise une syntaxe d’appel
unique pour traiter différentes implémentations d'une structure de données
mais utilise différentes implémentations.
·
Une fonction générique utilise un code unique pouvant opérer sur des objets de
type différent.
Le langage C++ implémente des objets génériques comme les fonctions génériques, les classes génériques, les méthodes génériques et les constantes génériques.
·
La protection des données dépend de
l'application.
·
Le langage C++ n'offre pas de moyens de
contrôle permettant de réaliser n'importe quelle protection. Les principes de
base sont les suivants :
à
la protection contre les accidents de
programmation est assurée par le compilateur. Elle n'est pas assurée contre la
fraude ou des violations explicites des règles.
à
L'unité de protection et d'accès est la classe.
à
Le contrôle
d'accès est réalisé à partir des identificateurs
des objets et non à partir de leur type.
à
L'accès
est contrôlé, pas la visibilité.
Nous allons utiliser les concepts de
programmation objet en C sur l'exemple suivant : définition d'une
structure abstraite de pile et des méthodes associées.
Þ Représentation interne et méthodes
·
La pile
est représentée par un tableau.
·
La base
et le sommet de la pile sont
représentés par les deux pointeurs top et pile.
·
Les méthodes définies sont les suivantes :
à
la fonction pile_vide réalise l’initialisation
de la pile,
à la fonction push empile un objet,
à la fonction pop
dépile un objet.
·
L’ensemble est codé dans le fichier pile.c qui peut être compilé et
édité dans une bibliothèque.
Þ Interface utilisateur
L’interface
utilisateur est décrite dans le fichier pile.h.
Þ Fichier pile.c : définition d'une structure de pile d'entiers
et des méthodes associées
/* Représentation de l'objet pile */
#define TAILLE 1024
static
int pile[TAILLE];
static
int* top=pile;
/*
opérations autorisée */
int
pile_vide (void){return top==pile;}
int
push(int e)
{if
(top-pile == TAILLE) return 0;
*top++=e;
return 1;
}
int
pop(void)
{if
(top!=pile) return *--top;}
void reinit_pile(void) {top=pile;}
Þ Interface avec le programme de
l’utilisateur
/*
prototypes contenus dans le fichier utilisateur pile.h */
int
pile vide(void);
int
push(int);
int
pop(void);
void reinit_pile(void);
Þ Avantages et inconvénients
+ abstraction et encapsulation des données : on peut modifier l'implémentation (structure de données,
corps des méthodes) sans modifier l'interface (prototypes des méthodes),
+ simplicité de l'écriture,
+ efficacité à l'exécution.
- la mémoire est gérée statiquement.
- l'utilisation est très
limitée : un seul objet pile
étant défini et l'objet abstrait correspondant ne l'étant pas, l'utilisateur ne
peut pas instancier d'autres objets du même type. Cette remarque conduit à la
modification de l’implémentation suivante.
Þ Deuxième version de l'interface pile.h
typedef
struct {int taille; int* base; int*
top;} PILE;
/*
Opérations autorisées */
void init_pile(PILE
*, int);
int pile_vide(PILE *);
int push(PILE*, int);
int pop(PILE*);
void effacer_pile(PILE*);
Þ Fichier pile.c (deuxième version)
#include <malloc.h>
#include
"pile.h"
void init_pile(PILE * pile, int taille)
{pile->top
= pile->base = (int*) malloc((pile->taille=taille) *sizeof(int));}
int
pile_vide(PILE *pile)
{return
(pile->top == pile->base);}
int
push(PILE* pile, int entier)
{if
((pile->top - pile->base) == pile->taille) return 0;
*pile->top++
= entier;
return
1;
}
int
pop(PILE* pile)
{if
(pile->top != pile->base) return *--pile->top;}
void effacer_pile(PILE* pile)
{free(pile->base);
pile->top=pile->base=0;
pile->taille
= 0;
}
Þ Programme d'utilisation
#include
"pile.c"
#include
<stdio.h>
int
main(void)
{int
i=0;
PILE
pile;
/*
initialisation non automatique */
init_pile(&pile,
10);
/*
utilisation de la pile */
while
(push(&pile, i++))
while
(!pile_vide(&pile)) printf("%d\n", pop(&pile));
/*
destruction non automatique de la pile après utilisation */
effacer_pile(&pile);
}
Þ Avantages et inconvénients
+ efficacité à l'exécution,
+ gestion mémoire dynamique,
+ le type abstrait pile est défini ce qui
permet à l'utilisateur d'instancier autant d'objets pile qu'il le souhaite.
- abstraction
et encapsulation des
données : rien n'empêche l'utilisateur de manipuler la représentation
d'un objet pile sans utiliser l'interface.
- simplicité de
l'écriture : pointeurs
- initialisation et effacement à la charge
de l'utilisateur
La prise en compte des dernières remarques
conduit à l'implémentation suivante :
Þ Troisième version du fichier pile.h
/*
Représentation des données */
typedef
void* PILE ;
/*
Opérations autorisées */
void init_pile(PILE, int);
int
pile_vide(PILE);
int
push(PILE, int);
int
pop(PILE);
void effacer_pile(PILE*);
Þ Troisième version du fichier pile.c
#include
<malloc.h>
#include
"pile.h"
typedef
struct{int taille; int *base; int *top;}pile;
void init_pile(void*a, int t)
{a
= malloc(sizeof(pile));
((pile*)a)->top
= ((pile*)a)->base = (int*)malloc((((pile*)a)->taille=t)*sizeof(int));
}
int
pile_vide(void* a)
{if
(((pile*)a)->top == ((pile*)a)->base) return 1; else return 0;}
int
push(void* a, int e)
{if
((((pile*)a)->top - ((pile*)a)->base) == ((pile*)a)->taille) return 0;
*((pile*)a)->top++=e;
return 1;
}
int
pop(void* a)
{if
(((pile*)a)->top !=((pile*)a)->base) return *--((pile*)a)->top;}
void effacer_pile(void** a)
{free(((pile*)*a)->base);
free(*a);
*a=0;
}
Þ Avantages et inconvénients
++ abstraction
et encapsulation des données
+ gestion
dynamique de la mémoire
+ le type pile est défini
ce qui permet à l'utilisateur d'instancier autant d'objets pile qu'il le
souhaite.
-- simplicité
de l'écriture
- efficacité
à l'exécution : indirection
- initialisation
et vidage de la pile à la charge de l'utilisateur.
·
Le langage C permet d'encapsuler des données et de définir des
types abstraits.
·
Il ne facilite pas la tâche du
programmeur car l'encapsulation nécessite d'utiliser l'indirection d'où une
complexité d'écriture.
·
Tout effort d'abstraction et d'encapsulation
en C se traduit par une écriture plus complexe et un ralentissement possible à
l'exécution.
Þ C++ langage de programmation orienté objet
Le langage C++ a été crée par Bjarne Stroustrup pour intégrer les concepts de programmation objet dans le langage C à
savoir :
·
définition de classes, d'instances et de méthodes,
·
définition des méthodes constructeur et destructeur,
·
prise en compte de l'héritage,
·
définition d'objets génériques.
Le C++ est un
des langages de programmation les plus utilisés actuellement. Très efficace et
performant, il est complexe et
quelquefois illisible, la complexité
du langage étant inévitable lorsque les fonctionnalités implémentées sont
nombreuses. Rappelons que la lisibilité
des programmes dépend essentiellement du programmeur. Enfin, ce langage est,
avec le C, idéal pour ceux qui doivent assurer la portabilité de leurs programmes sources.
Þ
Le langage
fonctionnel C++
Les principales
caractéristiques du langage C++ sont les suivantes :
·
nombre
important de fonctionnalités,
·
performances similaires à celles du langage C,
·
puissance d'utilisation des langages orientés objets,
·
portabilité des fichiers sources,
·
contrôle
d'erreur à la compilation basé sur un typage
très fort,
·
contrôle
des erreurs d'exécution possible pour le programmeur à partir de la gestion des exceptions.
Þ
Compatibilité
C et C++
Le C++ peut être
considéré comme un surensemble du C, certains programmes C devant être
adaptés. Cependant, les modifications sont minimes la syntaxe du C++ étant
basée sur celle du C et n'utilisant pas certaines de ses fonctionnalités
grammaticalement douteuses.
Le délimiteur // permet d'insérer des
commentaires dans le programme, en particulier à la droite d’une instruction.
!
Exemple
int valeur; // Ceci est un
entier
Þ Types de base
On retrouve les types de base classiques du langage C, avec quelques
évolutions :
void;
char (unsigned et signed);
short int, int;
long int (unsigned), float, double, long double (non
implémenté);
enum;
Þ Type booléen et énumération
Définition du type booléen dans la bibliothèque
standard du langage C++.
Définition de constantes symboliques par énumération, le type ainsi défini
devenant "presque" synonyme du type int.
!
Exemple
enum {FAUX, VRAI }; // par défaut FAUX vaut 0 et VRAI vaut 1
//
attention différent de {VRAI, FAUX} ;
enum COULEUR {VERT=5, ROUGE, JAUNE=9 };
// ROUGE équivaut à 6 par défaut et est
quasi-synonyme de int.
COULEUR couleur = ROUGE;
// couleur est initialisée à 6.
couleur = -7; //
syntaxiquement correct, message d'avertissement uniquement.
Þ Type intégral
char, wchar_t; //caractère, caractère
long
short, int, long, enum;
Þ Type flottant
float, double;
Þ Types arithmétiques
Les deux types précédents.
Þ Les types dérivés
& opérateur
de référence,
* opérateur
de déréférenciation,
[] tableau,
() fonction,
const qualification
d'un type, d'une variable ou du comportement d'une méthode,
class, struct, union types définis par le
programmeur,
.* sélecteur
sur objet membre,
-> sélecteur
sur pointeur.
Þ Le type void*
Le pointeur
générique void* doit toujours explicitement
être converti en un pointeur d'un type non générique.
Le langage C++ utilise les flots (streams), très souples, de préférence aux nombreuses fonctions
traditionnelles de la bibliothèque d'entrées/sorties du langage C :
scanf, printf, fscanf, fprintf,
sscanf, sprints, gets, puts, fgets, fputs, getchar, putchar, etc…
Quatre flots
sont initialisés au démarrage de l'exécution :
·
cin et l'opérateur associé >>
·
cout et l'opérateur associé <<
·
cerr et l'opérateur associé << (non bufferisé),
·
clog et l'opérateur associé << (bufferisé).
·
Les flots utilisent le fichier en tête iostream.h.
Þ Saisie
·
L'opérateur cin permet d'éviter les (trop) fréquentes erreurs de saisie dues à
une mauvaise utilisation de la fonction scanf
comme l'illustre l'exemple ci‑dessous :
int i ;
scanf("%d", i); //
horreur : sur un PC sous Windows, le plantage total est possible
scanf("%d",&i); //
correct mais les pointeurs arrivent
·
Le flot cin saisit en format libre des
données d'un quelconque type prédéfini sans obligation de le spécifier.
L'opérateur associé >> est par définition le délimiteur syntaxique des données à saisir.
·
Le séparateur
des données saisies est représenté par un ou
(ou non exclusif) plusieurs caractères d'espacement, de tabulation ou
les deux. Le caractère CR (retour chariot) est également autorisé.
Þ Affichage
·
Le flot cout affiche des données d'un type prédéfini en format
libre.
·
L’éventuel texte d'accompagnement est
délimité par deux ".
·
L'opérateur << précède les objets à
imprimer.
·
L'impression s'effectue de la gauche vers
la droite.
·
La fonction endl permet de gérer le passage à la ligne
!
Exemple 1
#include
<iostream.h>
int main()
{int a,b ;
cout << "Saisir a et b : "; // affichage du message de saisie
en format libre
cin >> a >> b; // saisie
des variables a et b
cout << "a= " << a << "\tb=
" << b << endl ; // affichage
et passage à la ligne
}
//
résultat
Saisir
a et b : 2 3
a=
2 b= 3
//
résultat
Saisir
a et b : 2
3
a=
2 b= 3
!
Exemple 2
/*
Fonction fact */
#include
<iostream.h>
unsigned
long fact(unsigned n)
{return
((n>1) ? n*fact(n-1) : 1); }
int
main()
{int
i =1 ;
while
(i)
{cout
<< "Entrez un nombre : ";
if
(! (cin >> i) ) break;
cout
<< "fact(" << n << ") = << fact(n);
}
}
!
Remarques
L’expression cin i, retourne i si la saisie s'est déroulée correctement, 0
sinon.
Þ Affichage de données en format libre
char
c='a';
int i=17;
float f=4.2;
char
*s="coucou";
char *v=s;
cout
<< c << ' ' << i << ' '<< f << '\t'
<< v << ':' << *v << endl;
//
résultat
a
17 4.2 0x4ab2:coucou
Þ Objet et traitement associé
·
En programmation
orientée objet, les objets contrôlent
les traitements par refus ou acceptation d'un message. Dans
cette dernière situation, il déclenche
le traitement correspondant à chaque message accepté.
·
En langage C++, un message résulte de l'utilisation d'un opérateur ou d'un appel de fonction.
·
Les méthodes cin et cout peuvent être
considérées comme des objets opérant respectivement sur les flots de données (messages) stdin et stdout.
!
Exemple
#include <iostream.h> // définition des objets de base de gestion
des flux standards
int main()
{// exemples d'objets
float PrixLu;
cout << "Prix hors taxes :
";
// l'opérateur cout opère sur le message (flux standard de sortie) stdout
cin >> PrixLu; // l'objet
(l'opérateur) cin traite un message
cout << "Prix TTC :
" << PrixLu*1.196 << endl ;
// l'opérateur cout traite trois messages consécutifs
cout.width(16); // un message peut aussi être un appel
de méthode width()
cout << PrixLu*1.196 << endl ;
cout.width(16); // méthode de facteur de cadrage sur 16
caractères
cout.fill('*'); // méthode remplissage dans la
limite du facteur de cadrage
cout << PrixLu*1.196 << endl ;
return(1);
}
// résultat
Prix hors taxes : 100
Prix TTC : 119.06
119.06
***********119.06
Contrairement au langage C, en langage C++,
les définitions des objets sont des instructions exécutables ce qui permet de définir une
variable à n'importe quelle instruction du programme.
!
Exemple
#include
<iostream.h>
int
main()
{int
t[] = {7, 4, 2, 9, 3, 6, 1, 4}; //
un tableau d'entiers de dimension incomplète
for (int
i=0; i<8; i++) cout<<t[i]; // définition de la variable
entière i
cout
<<endl ;
for (i=0;
i<8; i++) cout<< t[i];
cout <<endl ;
}
//
résultats
7
4 2 9 3 6 1 4
7
4 2 9 3 6 1 4
Þ Remarque
Dans cet exemple, les variables définies dans
la boucle for ne doivent pas être
redéfinies dans une boucle du même bloc.
Contrairement au langage C, l'ambiguïté entre définition et déclaration est interdite.
Þ Déclaration
En langage C++, toute déclaration de variable globale doit comporter obligatoirement
le mot-clef extern, contrairement au langage C ou les déclarations sont, selon les
situations, facultatives (avec des
choix par défaut) ou obligatoires.
Þ Définition
Toute variable globale doit être définie explicitement une et une seule
fois dans le programme et déclarée
explicitement au moins une fois dans chaque fichier où elle est utilisée.
·
En complément des opérateurs traditionnels
du langage C, trois opérateurs ont été définis :
à
l'opérateur de résolution de visibilité ::, essentiel pour
l'utilisation des structures et des
classes,
à
l'opérateur
d'allocation
dynamique d'instances new, simple à utiliser, ne
nécessitant pas de pointeur,
à
l'opérateur conjugué de libération de la mémoire delete.
·
Une nouvelle forme de transtypage (cast) est introduite : le transtypage
par appel de fonction ou encore transtypage fonctionnel.
En C++, un fichier en tête (header) peut contenir :
·
des commentaires,
·
des déclarations
de type, de constantes, de fonctions qualifiées inline (fonction en ligne),
·
des déclarations
de données et de fonctions externes,
·
des types énumérés,
·
des directives d'inclusion,
·
des macro‑définitions du préprocesseur (#define).
Il ne doit jamais
contenir de définition de donnée, de fonction, d'agrégat de constantes.
Le spécificateur
const qualifie tout type de variable pour
indiquer qu'il doit rester constant après son initialisation.
!
Exemple
const char new_line = endl ;
const char * voyelles =
"aeiouy"; // horreur du
C reprise en C++
const char* format1 = "%4d\t%d
<< endl" ;
const float pi = 3.14159265;
L'utilisation du mot clé const est une très bonne alternative à celle de l'utilisation de la
directive du préprocesseur #define pour
définir des constantes symboliques, la vérification de type étant effectuée dès
la compilation.
En langage C++, la portée du qualificatif const est
limitée au fichier courant.
Þ Suppression de la nécessité de l’utilisation de l'instruction typedef
·
En C++, une instance d'une classe de type
struct, union ou class est
définie directement à partir de l'identificateur de la classe en omettant
l'utilisation du mot clé struct, union ou class. Il n'est pas nécessaire d'utiliser le mot clé typedef du langage C.
·
Deux structures, même construites selon
le même modèle abstrait, sont différentes.
!
Exemple
struct type1 {int a; int b;};
struct type2 {int a; int b;};
type1
s10, s11
type2
s20;
s11
= s10; // OK
s11
= s20; // erreur de type
Þ Le qualificatif mutable
·
Cette
classe de mémorisation n'existe qu'en C++.
·
Elle n'est
utilisée que pour redéfinir les qualifications d'accès aux membres des
structures.
·
Elle permet
de passer outre la constance éventuelle d'une structure pour ce membre. Ainsi,
un champ d’une structure qualifié mutable
peut être modifié même si la structure est qualifiée const.
Une des utilisations de l'opérateur unaire de résolution de visibilité :: est de démasquer un nom global masqué par un nom local.
!
Exemple
#include <iostream.h>
int
x =1; // x variable globale
int
main()
{void f(); // prototype
cout
<< " x global " << x << endl ;
f();
cout
<< " x global depuis la fonction main : " << x <<
endl ;
}
void f()
{int
x = 3; // masque le x global
cout
<< " x local avant affectation x global : " << x
<< endl ;
::x=
2; // affectation du x global
cout
<< " x local après affectation du x global : " << x
<< endl ;
cout
<< " x global depuis f : " << ::x << endl ;
}
// résultats
x global 1
x local avant
affectation x global : 3
x local après
affectation x global : 3
x global depuis f :
2
x global depuis la
fonction main : 2
Le langage C++ modifie et complète le principe
du prototypage du C ANSI et propose en outre :
·
le spécificateur inline pour les méthodes,
·
la possibilité de définir des valeurs par défaut des arguments d'appel
des fonctions,
·
la surcharge
des fonctions,
·
la surcharge
des opérateurs.
Þ Obligation
L'utilisation du prototype est obligatoire
si la fonction n'est pas définie
préalablement à la fonction appelante dans le fichier courant contrairement au
langage C où cette déclaration est facultative,
selon les situations.
Þ Synopsis
définition := en_tête
corps_de_la_fonction
déclaration := extern en_tête;
en_tête:=
classe_de_memorisation type_résultat
identificateur_fonction (déclar_params)
corps
:= instruction_composée
!
Exemple
//
définition
int
f(int a, float b, int c) // en-tête
{/*
corps de la fonction */ }
//
déclarations ou prototypes ou signature
extern
int f(int, float, int);
extern int printf(const char*, ...); // nombre et type d'arguments variables.
·
Une procédure
est une fonction qui ne retourne rien
ce qui se traduit sur le plan syntaxique par le retour d'un objet de type void. L'utilisation du mot clé return est interdite.
·
Une fonction ou procédure déclarée sans argument a une liste vide, contrairement au langage C ou l'ambiguïté est de
rigueur.
!
Exemple
void f() {...} // procédure sans argument
·
Dans les langages procéduraux
traditionnels, plusieurs fonctions effectuant la même action, avec la même
sémantique, opérant sur des objets de types différents doivent être
implémentées avec des identificateurs et des types d'arguments différents.
·
En langage C, le préprocesseur (directive #define) permet d'implémenter des fonctions génériques dont l'inconvénient est
l'absence de vérification syntaxique
des instructions symboliques et
des types symboliques.
·
Le langage C++ autorise une définition multiple d'une fonction dont
le nombre et les types d'arguments peuvent différer. Ce concept, appelé surcharge ou polymorphisme, est étendu
à la plupart des (fonctions) opérateurs prédéfinies.
Þ Signature et surcharge d'une fonction
·
La signature d'une fonction est définie par
sa portée, le nombre et le type de ses arguments ainsi que par le type
de l'objet retourné. Elle est
représentée par le prototype de la
fonction.
·
La surcharge consiste à définir une fonction avec plusieurs signatures différentes.
Þ Choix de la fonction à l'exécution
Il n'est pas nécessaire de définir un
identificateur spécifique à chacune des différentes variantes de la fonction le
"bon choix" étant effectué à l'exécution selon sa signature en trois étapes :
·
recherche d'une correspondance exacte entre les paramètres formels et
les arguments d'appel.
·
recherche d'une correspondance en utilisant les conversions de type prédéfinis.
·
recherche d'une correspondance en utilisant les conversions définies par
l'utilisateur et s'il n'en n'existe qu'une l'appliquer, sinon problème d'ambiguïté.
!
Exercice et
exemple 1 : analyser le programme suivant
#include
<iostream.h>
int
saisir(char * texte)
{cout
<< texte ;
int
a;
cin
>> a;
return
a;
}
int
additionner(int a, int b)
{return
(a+b);}
void
afficher(char *texte , int a)
{cout
<< texte << a << endl;}
int
main()
{int
a, b;
int
saisir (char *);
void
afficher(char * , int) ;
void
afficher(char *, float);
void
afficher(char *, double) ;
int
additionner(int, int) ;
float
additionner(float, float) ;
double
additionner(double, double) ;
a
= saisir("a = ");
b
= saisir("b = ");
afficher("a
= ",a);
afficher("b
= ", b);
afficher("c
=", additionner(a,b));
}
!
Exemple 2
#include
<iostream.h>
int
main()
{//
prototypes divers de la fonction test surchargée
float
test(float, float);
float
test(float, int);
double
test(double, double);
float
x, x2;
double
y, z;
int
n;
cout
<< "Test (float, int) " << endl ;
cout
<<"saisir x et n : " ;
cin
>> x;
cin
>> n;
cout
<< "test("<< x << "," << n <<
")=" << test(x,n) << endl ;
cout
<< "Test (float, float) " << endl ;
cout
<<"saisir x et x2 : " ;
cin
>> x;
cin
>> x2;
cout
<< "test("<< x << "," << x2
<< ")=" << test(x,x2) << endl ;
cout
<< "Test (double, double) " << endl ;
cout
<<"saisir y et z : " ;
cin
>> y;
cin
>> z;
cout
<< "test("<< y << "," << z <<
")=" << test(y, z) << endl ;
return
1;
}
float
test(float x, int n)
{if
(n <0)
{cout
<< "erreur exposant négatif" << endl ; return -1;}
switch(n)
{case
0 : return 1;
case
1 : return x;
default
: return x*test(x,n-1);
}
}
float
test (float x, float n)
{cout
<< "float test (float x, float n)" << endl ;
cout
<< "x= " << x << "\tn = " << n
<< endl ;
return
(x*n);}
double
test (double x, double n)
{cout
<< "double test (double x, double n)" << endl ;
cout << "x= " << x
<< "\tn = " << n << endl ;
return (x*n);}
//
resultat
Test
(float, int)
saisir
x et n : 3 2 // flottant puis réel
test(3,2)=9
Test
(float, float)
saisir
x et x2 : 2 3 // deux flottants
float
test (float x, float n)
x=
2 n = 3
test(2,3)=6
Test
(double, double)
saisir
y et z : 2 3 // deux doubles
double
test (double x, double n)
x=
2 n = 3
test(2,3)=6
Þ Exercice
Ecrire une fonction surchargée de
multiplication de 3 nombres entiers puis flottant.
Þ Syntaxe
En langage C++, les prototypes de fonction permettent de définir des valeurs par défaut de certains paramètres,
obligatoirement les "plus à droite" de la liste.
!
Exemple
int
calcul( int, int =5, int =0);
·
Dans cet exemple, tout appel de la forme calcul(x,y,z) ou calcul(x,y) ou calcul(x)
est licite. Ainsi, l'appel calcul(x,y)
se traduit par calcul(x,y,0) et calcul(x) se traduit par calcul(x, 5, 0).
·
Une nouvelle définition ne peut pas
modifier la valeur par défaut d'un argument mais peut en augmenter le nombre.
!
Exemple
#include
<iostream.h> // fonctions avec 3
valeurs par défaut
int
main()
{int
somme(int =0, int=2, int =-3);
int a,b,c;
cout << "saisir a, b ,c"
<< endl;
cin >> a >> b >> c;
float t;
cout <<" a = "<< a
<< " b = " << b << " c = " << c
<< endl;
cout << "somme(a,b,c) ="
<< somme(a,b,c) << endl << "somme(a,b) =" <<
somme(a,b) << endl;
cout << "somme(a) =" <<
somme(a) << endl;
cout << "somme() =" <<
somme()<< endl ;
}
int somme(int x, int y ,int z)
{return x+y+z;}
//
résultat
saisir
a, b ,c
5 -5
-10
a = 5 b = -5 c = -10
somme(a,b,c) = -10 //somme
des 3 valeurs saisies
somme(a,b) = -3 //
5 + (-5) + -3
somme(a)=4 //
5 + 2 + -3
somme() = -1 //0
+ 2 + -3
!
Exemple 2
#include
<iostream.h>
int
main()
{int
somme(int =0, int=2, int =-3);
float somme(int, int, int, float); // surcharge
int a,b,c;
float t;
cout << "saisir a, b ,c"
<< endl;
cin >> a >> b >> c;
cout <<" a = "<< a
<< " b = " << b << " c = " << c
<< endl;
cout << "somme(a,b,c) ="
<< somme(a,b,c) << endl << "somme(a,b) =" <<
somme(a,b) << endl;
cout << "somme(a) =" <<
somme(a) << endl;
cout << "somme() =" <<
somme()<< endl ;
cout << "saisir a, b ,c, t"
<< endl;
cin >> a >> b >> c >>
t ;
cout <<" a = "<< a
<< " b = " << b << " c = " << c
<< "t = " << t << endl;
cout << "somme(a,b,c,t) ="
<< somme(a,b,c,t) << endl << "somme(a,b) ="
<< somme(a,b) << endl;
cout << "somme(a,t) ="
<< somme(a,t) << endl;
cout << "somme() =" <<
somme()<< endl ;
}
int somme(int x, int y ,int z)
{return x+y+z;
}
float somme (int x, int y, int z, float t)
{return x + y + z +t;
}
//
résultat
saisir
a, b ,c
5 -5
-10
a = 5 b = -5 c = -10
somme(a,b,c) = -10 //
somme des 3 valeurs saisies
somme(a,b) = -3 //
5 + (-5) + -3
somme(a)=4 //
5 + 2 + -3
somme() = -1 //
0 + 2 + -3
saisir
a, b ,c, t
5 -5
-10 3.14
a = 5 b = -5 c = -10 t = 3.14
somme(a,b,c, t) = -6.86 //
somme des 4 valeurs saisies
somme(a,b) = -3 //
5 + (-5) + -3
somme(a,t)=5 //
erreur sur plusieurs compilateurs
somme() = -1 //
0 + 2 + -3
Þ Définitions
·
Le type référence n'existe pas en langage C.
·
Une référence
est un
nom synonyme d'un identificateur de
variable existante.
·
Son utilisation permet de simplifier
l'écriture et la compréhension des mécanismes de transmission d'arguments entre
les fonctions en évitant l'utilisation délicate des pointeurs du langage C.
·
L'opérateur & est l'opérateur de référence, appelé aussi opérateur d'adresse.
·
L'opérateur * est l'opérateur de déréférenciation (d'un pointeur), appelé aussi opérateur
d'indirection.
Þ Initialisation
Une référence
est initialisée en ce sens qu'il doit
toujours exister un objet de référence sur lequel les opérateurs opèrent
par l'intermédiaire de ladite référence.
Þ Implémentation
Une référence est implémentée sous la forme d'un pointeur
constant déréférencé.
!
Exemple
#include
<iostream.h>
int main()
{int i = 1;
int & r1 = i,
& r2 = i; // r1, r2 sont des références à i
int x = r1; // x = i
r1 += 2; // i=3
cout << "
i = " << i << " r1 = " << r1 << "
r2 =" << r2 << " x = " << x << endl;
}
// Résultat
i = 3 r1 = 3 r2 = 3
x = 1
!
Exercice : analyser le programme
suivant.
#include
<iostream.h>
int
main(void)
{int
i =1;
int
&r =i; // r est une référence
à i
r++;
cout
<< "\nr = " << r << "\ti = " << i;
i++;
cout
<< "\nr = " << r << "\ti = " << i;
// i est r
cout
<< "\nLe résultat qui suit est étrange. Pourquoi ? ";
cout
<< "\nr = " << r << "\ti = " <<
i++;
cout
<< "\nr = " << r << "\ti = " << i;
cout
<< "\nLe résultat qui suit est attendu. Pourquoi ? ";
cout
<< "\nr = " << r++ << "\ti = " <<
i;
cout
<< "\nr = " << r << "\ti = " << i;
}
//
résultat
r
= 2 i = 2
r
= 3 i = 3
Le
résultat qui suit est étrange. Pourquoi ?
r
= 4 i = 3
r
= 4 i = 4
Le
résultat qui suit est attendu. Pourquoi ?
r
= 4 i = 4
r
= 5 i = 5
·
En langage C, deux modes de transmission
des arguments sont implémentés : la transmission par valeur et la transmission par adresse. Rappelons que ce dernier mode est délicat à programmer les objets
concernés étant représentés sous la forme de variables référencées dans
la fonction appelante et de pointeurs
déréférencés dans la fonction appelée.
·
Le langage C++ introduit la transmission des arguments par référence qui évite l'utilisation explicite des pointeurs déréférencés
dans la fonction appelée tout en permettant l'accès et la modification de
l'objet depuis la fonction appelante.
Þ Syntaxe
·
Dans la fonction appelante :
à
l'appel
est identique à celui de la transmission par valeur,
à
le prototype indique le mode de transmission
des variables par référence.
·
Dans la fonction appelée, il faut introduire l'opérateur de référence dans les paramètres formels. Le corps de la
fonction est identique à celui de la transmission par valeur.
!
Exemple 1
#include
<iostream.h>
int main() // Exemple de
transmission par référence
{void swap(int &, int &); // prototype de l'appel par référence,
optionnel si fonction définie
//
avant la fonction main
int a =2, b=3;
swap(a,b);
cout << "a= "
<< a << "\tb = " << b << endl ;
}
void
swap(int &x, int &y) //
transmission par référence
{int aux;
aux =x; x = y; y = aux;
}
// résultat
a=
3 b = 2
!
Exemple 2
#include
<iostream.h>
int
main()
{void swap_valeur(int, int);
void
swap_reference(int&,int&);
void
swap_adresse(int*, int*);
int a = 2 , b =3;
swap_valeur(a,b);
cout << "swap_valeur "
<< endl;
cout << "a = " << a
<< " b = " << b << endl;
swap_reference(a,b);
cout << "swap_reference "
<< endl;
cout << "a = " << a
<< " b = " << b << endl ;
swap_adresse(&a,&b);
cout << "swap_adresse "
<< endl;
cout << "a = " << a << " b =
" << b << endl;
}
void swap_valeur(int x,
int y)
{int aux;
aux =x; x= y ; y = aux;
}
void swap_reference(int
& x, int & y)
{int aux;
aux =x; x= y ; y = aux;
}
void
swap_adresse(int *x, int *y)
{int aux;
aux = *x; *x = *y ; *y = aux;}
Þ Inconvénient de la transmission par valeur
Toutes variable transmise par valeur est
sauvegardée dans la pile d'exécution. La fonction appelée s'exécute avec une
copie des arguments effectifs transmis ce qui est pénalisant quand la mémoire nécessaire pour l'argument effectif est
importante.
Þ Inconvénient de la transmission par référence ou par adresse
La transmission par référence permet à la fonction
où la procédure appelée de modifier les arguments transmis, même quand le
programmeur ne le souhaite pas.
Þ L'art du compromis
L'utilisation du spécificateur const permet une transmission par adresse ou par référence en garantissant au programmeur que la variable
transmise ne puisse être modifiée par la fonction ou la procédure appelée ce
qui permet un gain d'espace mémoire tout en garantissant le niveau de sécurité
convenable.
extern char*
strcpy(const char*, char*);
!
Exercice
Comment une variable, transmise par référence
et qualifiée constante est‑elle (re)transmise à une fonction appelée
encapsulée ?
#include
<iostream.h>
void
f1(const int &a)
{void
f2( int &);
cout << "a =" << a
<< endl;
int b =a ;
f2(b);
}
void f2(
int & a)
{a++;
cout << "f2 : a =" <<
a << endl;
}
int main()
{void f1(const int &);
int a =1;
f1(a);
a++;
f1(a);
}
Une fonction peut retourner une référence
qui, rappelons le, est un pointeur déréferencé
donc une Lvaleur. D'où la conséquence très importante : l'appel de
fonction peut devenir une Lvaleur quand la fonction retourne une
référence et figurer à gauche
de l'opérateur d'affectation.
Þ Syntaxe
type_résultat &
identificateur_de_fonction(....){corps_de_la_fonction}
!
Exemple
Nous anticipons ici sur l'utilisation des
notions de classe et de constructeur.
#include
<iostream.h>
#include
<stdlib.h>
#define TAILLE 80
class Ligne // une instance de cette classe est une ligne de TAILLE
caractères
{private:
char t[TAILLE + 1];
public:
//
appel explicite du constructeur
Ligne(char
C = ' '); // construction d'une
ligne vide par défaut
//
fonction (membre inline) retournant le caractère de la position d'un caractère donné
char
& Pos(int Position)
{if
(Position < 1 || Position > TAILLE) {cerr << "Position
inacceptable" << endl ; exit(1);}
return
t[Position-1];
}
};
Ligne::Ligne(char
C) // constructeur d'une ligne de C
caractères identiques
{for (int
k=0; k<TAILLE; k++) t[k]=C; t[TAILLE]='\0'; }
int
main()
{Ligne
L, La('A');
cout
<< "La.Pos(3) = " << La.Pos(3) << endl ;
// La
fonction-membre peut modifier une position quand le résultat est transmis par
référence
La.Pos(3)
= 'Z';
cout
<< "La.Pos(3) = " << La.Pos(3) << endl ;
La.Pos(2)
= La.Pos(3); // erreur de
compilation en C Ansi : Lvalue required
cout
<< "La.Pos(2) = " << La.Pos(2) << endl ;
return
1;
}
//
résultat
La.Pos(3)
= A
La.Pos(3)
= Z
La.Pos(2)
= Z
Une variable
statique a des propriétés similaires à
celles du langage C : rémanence et confidentialité.
·
elle n'est accessible que dans le fichier
où elle est définie.
·
elle n'est pas détruite en sortie de bloc
comme les variables dont la classe d'allocation est automatique.
·
elle est donc accessible dans une
fonction, même après un retour d'appel.
!
Exemple : anayser les résultats
du programme suivant :
#include <iostream.h>
int main()
{int f(int); //
prototype
for(int
j=0; j<3; j++)
{cout
<< "fonction main()" << endl;
cout
<< " j = " << j << " f(j) = " <<
f(j) << endl;
cout
<< "**********************" << endl;
}
}
int f(int i)
{static int s=0 ; s++;
cout
<< " fonction f " << endl;
cout
<< " i = " << i << " s = " << s
<< endl ;
return
i+1;}
// résultats
fonction main()
fonction
f
i = 0 s
= 1
j = 0 f(j) = 1
**********************
fonction main()
fonction
f
i = 1 s
= 2
j = 1
f(j) = 2
**********************
fonction main()
fonction
f
i = 2 s
= 3
j = 2
f(j) = 3
**********************
Þ Fonctions externes
Par défaut, une
fonction définie dans un fichier peut être utilisée dans un autre à condition
d'être préalablement déclarée. La fonction est alors dite externe.
Þ
Fonctions
statiques
·
Il peut
être nécessaire de définir des fonctions locales à un fichier pour résoudre des
conflits d'identificateur (deux fonctions de même nom, même signature, dans
deux fichiers différents) ou parce que la fonction est uniquement d'intérêt
local.
·
Les
langages C et C++ utilisent le qualificatif
static, qui, en précédant la définition et les
éventuelles déclarations d'une fonction, la rend visible exclusivement dans ce fichier.
·
Les
fonctions qualifiées static sont
d'utilisation identique aux fonctions traditionnelles.
!
Exemple
static int locale1(void); // déclaration d'une fonction statique
/* définition d'une autre fonction statique : */
static int locale2(int i, float j)
{return i*i+j;}
·
Le spécificateur inline pour une fonction est similaire
dans sa philosophie au qualificatif register
pour une variable.
·
C'est une directive de compilation qui spécifie le remplacement de l'appel
traditionnel par l'intégration immédiate du corps de la fonction dans le programme.
L'espace occupé par le programme est plus important mais ce dernier est plus
rapide.
·
Son utilisation est une bonne alternative
à l'emploi de la directive du préprocesseur #define qui en présente les mêmes avantages et limites (liés à la
substitution du corps de la fonction à l'appel) car le parenthésage est parfait
ce qui limite les effets de bord et offre une plus grande clarté au lecteur.
·
Une fonction spécifiée inline n'a pas d'adresse, ne peut être
ni récursive ni exportée.
·
Les
fonctions spécifiées inline
étant insérées à l'instruction d'appel
doivent être définies préalablement.
·
Contrairement
aux fonctions traditionnelles, il n'est pas possible de les déclarer pour les
appeler, et de fournir leur définition dans un fichier séparé car l'éditeur de
lien ne les gère pas.
!
Exemple
inline void bonjour()
{cout << "bonjour" <<
endl;}
·
La classe en langage C++ est une généralisation des structures
traditionnelles du langage C constituée :
à
des champs,
à
de fonctions
internes opérants sur les objets de
la classe,
à
de mécanismes
de protection des données.
·
La classe permet d'implémenter un type d'objet abstrait dont la définition comprend :
à
une partie privée ou publique selon les besoins, contenant la représentation des données, réservée au développeur,
à
une partie publique
constituant l'interface d'appel pour
les utilisateurs des objets du type concerné. Elle contient la description de
l'ensemble des opérations (méthodes) autorisées sur ces derniers.
·
Le développeur peut se réserver l'usage
exclusif d'une méthode en la
déclarant privée ou permettre à
l'utilisateur d'accéder à un champ en
le déclarant public.
·
L'utilisateur ne peut que manipuler les
objets (champs ou méthodes) définis dans la partie publique (garanti par le langage car
contrôle à la compilation).
·
Une classe est la représentation abstraite d'un ensemble d'objets dotés
de propriétés identiques.
·
Chaque objet défini dans la classe est appelé instance.
Þ Propriétés
Les propriétés des instances d'une classe sont caractérisées
par :
·
la définition des informations relatives
à l'objet, appelées données membres ou champ,
·
la définition des traitements
autorisés sur ces objets appelés fonctions membres ou méthodes qui peuvent être définies dans la classe (méthodes inline) ou à l'extérieur. Dans ce dernier cas, le spécificateur inline précède la définition, externe à
la classe, de la méthode.
·
Une méthode inline doit être définie dans le fichier source de la classe
associée.
Þ Mots clés
Les spécificateurs struct et class permettent de définir des classes
d'objets.
Þ Opérateur de résolution de portée
L'opérateur
de résolution de portée (scope) :: permet de définir ou
d'accéder à des méthodes d'une classe
à l'extérieur de celle‑ci selon la syntaxe :
Type_résultat
identificateur_de_la_classe::identificateur_méthode(liste_des_paramètres_formels_typés)
{corps_de_la_méthode}
Þ Accès aux données membres
L'accès aux données membres est réalisé à
partir de l'opérateur de sélection de membre ., comme en langage C, pour accéder aux champs
d'une structure.
Þ Traitement d'une instance par une méthode
Le traitement d'une instance par une méthode
s'écrit, d'une façon analogue :
instance.methode(argument(s));
!
Exemple
#include <string.h>
#include <iostream.h>
const int NbMaxCarac = 25;
struct Produit { //
Définition de la classe Produit
// définition
des données-membres pour chaque
instance
char Nom[NbMaxCarac+1]; //
nom du produit
float PrixHT; //
prix HT
float TauxTVA; //
Taux de TVA
// définition
et prototypes des méthodes
float PrixTTC() {return PrixHT *
(1+TauxTVA);} // définition d'une
méthode inline
int FixeNom (const char *); // prototype de la méthode FixeNom
}; // fin de
la définition de la classe Produit
int
Produit::FixeNom (const char * Texte) // la
fonction membre FixeNom
{// recopie au
plus les NbMaxCarac premiers caractères de l'argument Texte
// dans la
donnée membre Nom.
strncpy (Nom,
Texte, NbMaxCarac);
Nom[NbMaxCarac]
= '\0'; //
chaîne à copier trop longue
return
strlen(Nom);
}
int main()
{Produit P1; //
une instance de la classe Produit
Produit
TabProduits[50]; //
un tableau de 50 instances
P1.FixeNom("Chocolat
Meunier 500g"); //
Appel de la méthode FixeNom
TabProduits[3]
= P1; //
affectation (surchargée) entre instances
TabProduits[5].FixeNom("Baril
5kg Lessive économique");
TabProduits[5].PrixHT
= 45;
TabProduits[5].TauxTVA
= 0.196;
cout << TabProduits[5].Nom
<<": " << TabProduits[5].PrixTTC();
// Problème de
débordement de chaîne de caractères avec
// strcpy
(TabProduits[2].Nom,"Baril 5kg Lessive économique");
return (1);
}
// résultat
Baril 5kg
Lessive économi: 53.82
Þ Remarque
Le résultat semble satisfaisant sauf pour les
débordements de chaînes de caractères (à priori limité par NbMaxCarac).
L'accès à un membre d'une classe peut être qualifié
privé, protégé (classe dérivée), ou public.
Þ Accès privé
L'accès à une donnée membre privée n'est autorisé que pour les fonctions membres et amies de la
classe où elle est déclarée.
Þ Accès public
L'accès à une donnée membre publique est autorisé pour n'importe quelle méthode,
fonction, ou opérateur.
Þ Qualification d'accès par défaut
Par défaut, les données et fonctions membres
des structures définies à partir du mot clé struct sont d'accès public. Celles des classes définies à partir du mot clé class sont d'accès privés.
Les mode d'accès par défaut des données et
fonctions membres peuvent être requalifiés
à partir des spécificateurs d'accès public, private, protected.
Þ Accès protégé pour les classes dérivées
L'accès à une donnée membre protégée n'est autorisé que pour les fonctions membres et amies de la
classe où elle est déclarée ainsi que celles des classes dérivées par héritage.
Þ Portée d'un spécificateur
Un spécificateur
d'accès définit les règles d'accès pour
les membres de la classe qui le suivent jusqu'à la fin de la classe ou jusqu'à
un autre spécificateur d'accès.
Synopsis
spécificateur_d'accès : liste_des_membres
Þ Retour sur les types struct et union
En langage C++, les structures et les unions
sont des classes où toutes les données membres sont par défaut publiques et où
il est possible de définir une partie privée. Ainsi, la séquence :
struct pile {int taille, *base,
*top, pile(int); }
équivaut à
class pile {public : int taille,
*base, *top, pile(int); };
Cette
définition des mots clés struct et union est compatible ascendante avec
celle du langage C ANSI.
!
Exemple
// deuxième version de la classe Produit
#include <iostream.h>
#include <string.h>
const int NbMaxCarac = 25;
// par défaut, les accès des données membres
d'une classe sont privées
class Produit
{char
nom[NbMaxCarac+1]; // données
membre qualifiée d'accès privé
float
prixHT;
float
tauxTVA;
public:
//
méthodes inline
float
PrixTTC() {return prixHT * (1+tauxTVA);}
const char * Nom() {return nom;} // la donnée membre nom reste constante
int
FixeNom (const char *); // prototype d'une méthode
définie à l'extérieur de la classe
}; //
fin de la définition de la classe Produit
int Produit::FixeNom (const char * Texte) //
la méthode FixeNom
{// copie au maximum les NbMaxCarac premiers
caractères de Texte dans le membre nom
strncpy (nom, Texte, NbMaxCarac);
nom[NbMaxCarac] = '\0'; // chaîne à copier trop
longue
return strlen(nom);
}
int main()
{ Produit
P1;
P1.FixeNom("Chocolat
économique Meunier par emballage de 100g");
cout
<< "P1 : " <<
P1.Nom() << endl ;
P1.FixeNom("Baril
5kg Lessive Paic économique");
cout
<< "P1 : " <<
P1.Nom() << endl ;
//
La protection du membre privé nom est assurée :
//
cout << "P1 : "
<< P1.nom << endl ;
//
erreur de compilation : Produit::nom is not accessible
//
strcpy (P1.Nom(),"Baril 5kg Lessive Paic économique");
//
erreur de compilation : cannot convert 'const
char *' to 'char *'
return
(1);
}
// résultat
P1 : Chocolat économique Meuni
P1 : Baril 5kg Lessive Paic éc
Þ Règles d'utilisation
Une
méthode peut :
·
accéder et opérer sur toutes les données membres de la classe,
·
appeler toute méthode de la classe,
y compris elle même si elle n’est pas qualifiée inline,
·
être d'accès public, privé ou protégé (héritage).
·
Le type d'accès de toute donnée membre
est vérifié à l'exécution lors de l'appel de la méthode.
Þ Méthode définie dans sa classe (inline)
Une méthode définie à l'intérieur d'une classe
est qualifiée inline.
Þ Méthode définie à l'extérieur de sa classe
·
Une méthode, définie à l'extérieur d'une classe doit :
à
comporter la définition explicite de sa portée,
à
être déclarée dans la
classe.
·
Elle ne peut y être définie en ligne que si sa définition comporte
le spécificateur inline.
Þ Définition
·
Dans le corps d'une méthode non qualifiée statique, le mot clé this représente un pointeur constant
contenant l'adresse de l'instance par l'intermédiaire duquel elle a été
invoquée, accessible par déréférenciation à partir de l'expression *this.
·
Le pointeur this est inaccessible à
l'extérieur de la méthode.
!
Exemple
#include <iostream.h>
class Entiers
{public:
int i;
void affiche(char * chaine){cout
<< chaine << "
this=" << this << " i=" <<this->i << endl;};
};
int
main()
{Entiers
k,l;
k.affiche("k : ");
l.affiche("l : ");
Entiers
p;
p.affiche("p : ");
}
// résultats
k : this =0x50771c24 i=0
l : this
=0x50771c22 i=0
p : this =0x50771c20 i=9615
Le lecteur peut constater qu'une des
initialisations est fantaisiste.
Þ Définition
·
Une méthode spécifiée constante ne peut modifier l'instance par
laquelle elle a été invoquée.
·
Elle ne peut être utilisée qu'avec des
instances qualifiées constantes.
·
Tout
argument qualifié const perd cette
qualification dans l'interprétation de sa signature sauf l'instance pointé par this. Deux méthodes avec des paramètres
identiques dont une qualifiée const peuvent
donc être définies.
Synopsis
type_résultat
identificateur_de_méthode(....) const {corps de la méthode}
!
Exemple
// troisième version de la classe Produit
#include <iostream.h>
#include <string.h>
const int NbMaxCarac = 25;
enum {Taux1, Taux2}; // entiers caractérisant les taux de TVA applicables
class Produit
{private: //
ici facultatif
char
nom[NbMaxCarac+1];
float tauxTVA;
public: //
données membres publiques
float PrixHT;
float PrixTTC() const {return PrixHT * (1+tauxTVA);} // méthode en ligne spécifiée
constante
void MemeTVAque (Produit P)
{tauxTVA = P.tauxTVA; } // Le taux de l'objet P est associé à l'instance courante
// prototypes
const char * Nom() const;
int FixeNom(const
char *);
void TVA(int);
};
// La fonction
membre Nom() est définie à l'extérieur de la classe et qualifiée explicitement inline
inline const char * Produit::Nom() const {return nom;}
void Produit::TVA(int Taux) //
validation du taux et affectation au membre de tauxTVA
{switch (Taux)
{case
Taux1 : tauxTVA = 0.055; break;
case
Taux2 : tauxTVA = 0.196; break;
default : cerr << "TVA
inacceptable" << endl ; exit (1);
}
}
int Produit::FixeNom (const char * Texte)
{// copie au maximum les NbMaxCarac premiers
caractères de Texte dans le membre nom
strncpy (nom, Texte, NbMaxCarac);
nom[NbMaxCarac] = '\0'; // chaîne copiée trop
longue
return strlen(nom);
}
int main()
{Produit P1;
P1.FixeNom("Chocolat Meunier 100g");
P1.PrixHT = 9;
cout << "Prix HT de l'instance P1 :
" << P1.PrixHT <<endl ;
P1.TVA(Taux2);
cout << "Prix TTC de l'instance P1 :
" << P1.PrixTTC() <<endl ;
P1.TVA(0);
cout << "Prix TTC de l'instance P1 :
" << P1.PrixTTC() <<endl ;
Produit P2;
P2.MemeTVAque (P1);
P2.PrixHT = 18;
cout << "Prix HT de l'instance P2 :
" << P2.PrixHT <<endl ;
cout << "Prix TTC de l'instance P2 :
" << P2.PrixTTC() <<endl ;
P2.TVA(4); //
message d'erreur à l'exécution (contrôle du taux)
return(1);
}
// résultat
Prix HT de l'instance P1 : 9
Prix TTC de l'instance P1 : 10.764
Prix TTC de l'instance P1 : 9.495
Prix HT de l'instance P2 : 18
Prix TTC de l'instance P2 : 18.99
TVA inacceptable
·
Une classe
peut contenir des objets statiques qui peuvent être des données
membres ou définies dans une de ses méthodes, ou encore des méthodes
statiques.
·
Elles sont définies et qualifiées static.
Une donnée
membre qualifiée static :
·
caractérise
la classe et non ses instances,
·
est accessible par tous ses objets,
·
a des propriétés de rémanence et de
protection identiques à celles d'une variable qualifiée statique en langage C.
Þ
Constructeur
et données statiques
Les données statiques d'une classe n’étant pas
spécifiques à une instance donnée, il est interdit de les initialiser dans un
constructeur dont le rôle est l'initialisation dynamique des nouvelles instances.
Þ
Initialisation
L'initialisation des données statiques est réalisée à leur définition, toujours externe à la classe spécifiée avec l'opérateur de
résolution de portée (::).
!
Exemple
class test
{static int
i; // Déclaration dans la classe.
…
};
int
test::i=3; // Initialisation
externe à la classe.
·
Les
variables statiques des méthodes doivent y être initialisées.
·
Leur portée
est réduite à celle du bloc dans lequel elles ont été définies.
·
Elles
caractérisent la classe, pas ses instances.
!
Exemple
#include
<iostream.h>
class test
{public:
int n(void);
};
int test::n(void)
{static int compte=0;
compte++; return compte;
}
int main(void)
{test objet1,
objet2;
cout << objet1.n() <<
endl; // Affiche 1
cout << objet2.n() <<
endl; // Affiche 2
return 0;
}
!
Exercice : analyser le
programme suivant
#include <iostream.h>
class Entiers
{public:
int i;
Entiers() {i=0; cout << "this ="
<< this << endl; }; //
un constructeur
void incremente() {i++; cout
<< "this =" << this << endl;};
void affiche(char * chaine ){cout << chaine << i <<
endl;};
};
int
main()
{void f();
f();
f();
}
void f()
{static Entiers k,l;
k.affiche("k = ");
k.incremente();
k.affiche("k = ");
l.affiche("l = ");
Entiers
p;
p.affiche("p = ");
}
// résultat
this =0x6db70642
this =0x6db70644
k = 0
this =0x6db70642
k = 1
l = 0
this =0x6db71c30
p = 0
k = 1
this =0x6db70642
k = 2
l = 0
this =0x6db71c30
p = 0
Þ Définition
·
L'appel d'une méthode qualifiée
static est identique à celui d'une méthode non statique.
·
Une méthode qualifiée
static n'est pas une caractéristique
de la classe.
·
Une méthode qualifiée
static pouvant opérer sur des objets peut être invoquée avec ou sans référence à l'un d'entre eux. Dans le premier cas, la partie
gauche de l'expression objet.methode()
n'est pas évaluée car dans une fonction membre qualifiée static, le pointeur this n'a pas de sens.
!
Exemple 1
#include <iostream.h>
class Entier
{static int j;
public:
static
int get_value(void);
};
int Entier::j=10;
int Entier::get_value(void)
{j++;
// Légal.
return
j;
}
int main()
{cout << Entier::get_value() <<
endl;
cout
<< Entier::get_value() << endl;
cout
<< Entier::get_value() << endl;
}
// résultat
11
12
13
!
Exemple 2
#include
<iostream.h>
class Entier
{static int i;
public:
static int get_value(void);
};
int Entier::i=3; // initialisation externe à la classe
int
Entier::get_value(void)
{return i; }
int main(void)
{int
resultat=Entier::get_value();
cout << resultat << endl; // resultat = 3
return 0;
}
Les membres d'une classe (données ou méthodes) sont
accessibles par leur adresse.
!
Exemple
#include
<iostream.h>
class Classe
{public: void methode(int a){cout << a
<< endl ;};};
void f()
{Classe c,
*pc=&c;
void
(Classe::*Pointeur_Methode)(int) =&Classe::methode;
//
quatre écritures pour un même résultat
int
i =3;
c.methode(i);
pc->methode(++i);
(c.*Pointeur_Methode)(++i)
;
(pc->*Pointeur_Methode)(++i);
}
int
main()
{void f();
f();}
// résultats
3
4
5
6
En langage C++, deux méthodes permettent
respectivement d'allouer et d'initialiser la mémoire puis d'en récupérer
l'espace.
·
Le constructeur est une méthode appelée pour
en définir et initialiser (implicitement ou explicitement) les données membres
de chaque instance.
·
Le destructeur définit les opérations à
effectuer lors de la disparition d'une instance de la classe.
Contrairement au langage C, la fonction main n'est pas la première à s'exécuter,
les constructeurs des objets globaux
devant être exécutés préalablement.
·
Le langage C++ fournit un constructeur par défaut appelé constructeur implicite.
·
Les données membres sont initialisées à une valeur indéterminée.
!
Exemple
// quatrième version de la classe
Produit : utilisation du constructeur
par défaut
#include <iostream.h>
enum {Taux1, Taux2}; // taux de TVA utilisables
class Produit {private:
float
tauxTVA;
public:
float
PrixHT; // seul
le prix HT d'un produit peut varier
float
PrixTTC() const {return PrixHT *
(1+tauxTVA);} // méthode inline
};
int main()
{Produit P1; //
L'instance P1 est initialisée avec le constructeur par défaut :
P1.PrixHT = 10.5; // PrixHT est la seule donnée-membre publique initialisée
explicitement.
cout << "PrixHT = " <<
P1.PrixHT << "\tPrix TTC = " << P1.PrixTTC() <<
endl ;
}
// résultat
PrixHT = 10.5 Prix
TTC = 10.5 // Taux=0 !!
Þ Définition
·
Un constructeur
explicite est une méthode dont
l'identificateur est celui de la classe.
·
Il ne peut comporter aucune indication de
type de l'objet renvoyé.
·
La définition explicite d'un constructeur se substitue à celle du constructeur implicite.
Þ Synopsis
Soit la classe C. Alors:
[C::]C(...){corps_de_la_méthode}
est une fonction
constructeur de la classe.
Þ Redéfinition du constructeur par défaut
Un constructeur
sans argument surcharge le constructeur
par défaut. Il doit bien évidemment être cohérent avec l'objet à construire sur le plan sémantique.
!
Exercice et exemple
On considère la classe Produit. On souhaite
exécuter la fonction main()
suivante :
int main()
{Produit P1("SAVON", 10, Taux2);
Produit P2("LIVRE DE POCHE", 25);
cout << "Article P1 : Nom = "
<< P1.Nom() << " Prix HT = " << P1.PrixHT()
<<
" Taux = " << P1.Taux() << " Prix TTC = "
<< P1.PrixTTC() ;
cout << "\nArticle P2 : Nom = "
<< P2.Nom() << " Prix HT = " << P2.PrixHT()
<<
" Taux = " << P2.Taux() << " Prix TTC = "
<< P2.PrixTTC() << endl;
// Produit P2;
// erreur de compilation : could not find a
match for 'Produit::Produit()
}
// résultat
Article P1 : Nom = SAVON Prix HT = 10 Taux =
0.196 Prix TTC = 11.96
Article P2 : Nom = LIVRE DE POCHE Prix HT = 25
Taux = 0.055 Prix TTC = 26.375
1°) Ecrire les méthodes
void fixeNom(float), void prix(float), void tva(int)
ainsi que les méthodes inline
float
PrixTTC() const
const char * Nom() const
const float PrixHT()
const float Taux()
2°) Ecrire un constructeur de la classe
Produit qui fixe le taux de TVA par défaut à 5.5%
// Cinquième version de la classe
Produit : constructeur explicite
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
const int NbMaxCarac = 25;
enum {Taux1, Taux2};
class Produit
{private:
char
nom[NbMaxCarac+1]; //
Nom de l’instance
float tauxTVA; // Taux
de TVA
float prixHT; //
Prix HT
// prototypes des méthodes extérieures à la
classe
void fixeNom(const char *);
void prix(float); // affecte une valeur valide à
la donnée membre prixHT
void tva(int); //
affecte une valeur valide à la donnée membre tauxTVA
public: // méthodes inline
float PrixTTC() const {return prixHT * (1+tauxTVA); }
const char * Nom() const {return
nom;}
const float PrixHT() const {return
prixHT;}
const float Taux() const {return
tauxTVA;}
// Constructeur inline
Produit(const
char * Nom, float Prix, int TVA = Taux1)
{fixeNom(Nom); prix(Prix); tva(TVA);}
}; // fin de la classe Produit
// autres méthodes
void Produit::fixeNom (const char
* Texte)
{strncpy (nom, Texte, NbMaxCarac);
nom[NbMaxCarac] = '\0';
}
void Produit::prix(float Prix) //
affectation d'une valeur valide au membre prixHT
{if (Prix < 1 || Prix > 1000) {cerr
<< "prix HT inacceptable" << endl ; exit(1);}
prixHT = Prix;
}
void Produit::tva(int Taux) // validation du taux de
TVA
{switch (Taux)
{case
Taux1 : tauxTVA = 0.055; break;
case Taux2 : tauxTVA = 0.196; break;
default
: cerr << "\nTVA inacceptable" << endl ; exit (1);
}
}
Plusieurs constructeurs peuvent être définis
dans une classe à condition que leurs signatures
respectives soient distinctes, le constructeur utilisé à l'exécution étant
celui dont la signature est la plus
adaptée.
!
Exemple
On considère la classe Produit. On souhaite
exécuter la fonction main()
suivante :
int main()
{ Produit P1("SAVON", 7.5,
Taux2); // 1er
constructeur
Produit P2("LIVRE DE POCHE 1
VOL",25); // 1er
constructeur avec taux par défaut
Produit Base; // 2ième
constructeur
Produit P3 ("LESSIVE
PROMO"); // 3ième
constructeur
Produit P4; // 2ième
constructeur
P4 = "NOUVEAUTE"; // 3ième
constructeur avec copie membre à membre
cout
<< "\nArticle\tNom\t\t\tPrix HT\tTaux\tPrix TTC" ;
cout
<< "\nP1\t" << P1.Nom() << "\t" <<
P1.PrixHT()
<< "\t" << P1.Taux()
<< "\t" << P1.PrixTTC() ;
cout
<< "\nP2\t" << P2.Nom() << "\t" <<
P2.PrixHT()
<< "\t" << P2.Taux()
<< "\t" << P2.PrixTTC() ;
cout
<< "\nP3\t" << P3.Nom() << "\t" <<
P3.PrixHT()
<< "\t" << P3.Taux()
<< "\t" << P3.PrixTTC() ;
cout
<< "\nP4\t" << P4.Nom() << "\t" <<
P4.PrixHT()
<< "\t" << P4.Taux()
<< "\t" << P4.PrixTTC() ;
cout
<< "\nBase\t" << Base.Nom() << "\t"
<< Base.PrixHT()
<< "\t" << Base.Taux()
<< "\t" << Base.PrixTTC() ;}
// résultat
Article Nom Prix
HT Taux Prix TTC
P1 SAVON 7.5 0.196 8.97
P2 LIVRE DE POCHE 1
VOL 25 0.055 26.375
P3 LESSIVE PROMO 8.36 0.196 10
P4 NOUVEAUTE 8.36 0.196 10
Base TEMOIN 83.60 0.196 100
1°) Ecrire les méthodes
void fixeNom(float), void prix(float), void tva(int)
ainsi que les méthodes inline
float
PrixTTC() const
const char * Nom() const
const float PrixHT()
const float Taux()
2°) Ecrire un constructeur de la classe
Produit qui fixe le taux de TVA par défaut à 5.5%
3°) Ecrire un constructeur de la classe
Produit qui fixe le nom d’un produit témoin, son prix TTC à 100 Euro pour un
taux de TVA de 19.6%.
4°) Ecrire un constructeur de la classe
Produit qui fixe par défaut le prix TTC de tout produit à 10 Euro avec un taux
de TVA à 19.6%.
// sixième version de la classe Produit
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
const int NbMaxCarac = 25;
enum {Taux1, Taux2};
class Produit
{private: //
données membres
char
nom[NbMaxCarac+1];
float
tauxTVA;
float
prixHT;
//
prototypes des méthodes
void fixeNom(const char *);
void prix(float);
void tva(int);
public: //
méthodes inline
float
PrixTTC() const {return prixHT *
(1+tauxTVA); }
const char * Nom() const {return nom;}
const float PrixHT() const {return prixHT;}
const float Taux() const {return tauxTVA;}
Produit(const char * Nom, float Prix, int TVA =
Taux1) // 1 : premier constructeur
{fixeNom(Nom);
prix(Prix); tva(TVA);}
Produit() //
2 : constructeur par défaut
{fixeNom
("TEMOIN"); prixHT = 100/1.196; tva(Taux2);}
Produit(const
char * Nom) //
3 : produit à 10 Euro
{fixeNom(Nom);
prixHT = 10/1.196; tva(Taux2); }
};
// méthodes
void Produit::fixeNom (const char * Texte)
{strncpy (nom,
Texte, NbMaxCarac);
nom[NbMaxCarac] =
'\0';
}
void Produit::prix(float Prix)
{if (Prix < 1 || Prix > 1000) {cerr
<< "prix HT inacceptable" << endl ; exit(1);}
prixHT
= Prix;
}
void Produit::tva(int Taux)
{switch (Taux) {
case
Taux1 : tauxTVA = 0.055; break;
case
Taux2 : tauxTVA = 0.196; break;
default : cerr <<
"\nTVA inacceptable" << endl ; exit (1); }
}
En langage C++, deux opérations de transtypages
explicites sont définies : la forme traditionnelle du
langage C et le transtypage fonctionnel du langage C++.
Þ Synopsis du transtypage fonctionnel
·
Un nom de type suivi d'une expression
entre parenthèses convertit l’expression conformément au type de retour
spécifié par l’appel du constructeur implicite associé.
·
Quand expression
est une liste, le transtypage s'effectue par l'appel d’un
constructeur, l'objet devant être membre d'une classe dotée du constructeur
adéquat.
!
Exemple 1
float f;
long i = (long) f; //
forme traditionnelle
i = long(f); //
forme fonctionnelle par appel du constructeur implicite d’une instance
// de la classe long
!
Exemple 2
// Transtypage
fonctionnel par appel explicite du constructeur par défaut de la classe int
#include
<iostream.h>
int
main()
{int i = int(1.2); cout << " i
= " << i << endl ;
i
= int(); cout << " i
= " << i << endl ;
int
j = int(); cout << " j =
" << j <<endl;
return(1);
}
// résultat
i = 1
i = 0
j = 0
Þ
Conversions
implicites
Les conversions implicites sont
exécutées dès qu'existe un constructeur dont le premier argument est du même type
que l'objet source. Dans l'exemple ci‑dessous, le nombre entier situé à
la droite de l'affectation est convertie en un objet de la classe Entier.
!
Exemple
Soit la classe
Entier
#include <iostream.h>
class Entier
{public :
int i;
Entier(int j) {i=j;} //
constructeur de transtypage des nombres entiers
};
int main()
{int j=2;
Entier e1(j);
Entier e2=j;
Entier
e3(5) ;
cout <<
" e1 = " << e1.i << " e2 = " << e2.i << " e3 = " << e3.i
<< endl;
}
Þ Le mot clé explicit
Le mot-clé explicit utilisé
avant la déclaration du constructeur force la conversion explicite à partir
d'un transtypage fonctionnel.
!
Exemple
#include
<iostream.h>
class Entier
{public : int i;
public:
explicit Entier(int j)
{i=j; return ;}
};
// la conversion
d'un entier en objet de classe Entier nécessite un transtypage explicite
int main()
{
int j=6;
// Entier e1; // ereur
Entier e1=(Entier)
j; // e1.i=6
Entier
e2=Entier(j); // e2.i=6
Entier
e3=Entier(5); // e3.i=5
cout <<
" e1.i = " << e1.i << endl;
cout << "
e2.i = " << e2.i << endl;
cout <<
" e3.i = " << e3.i << endl;
}
Þ Remarque
Le type d'un objet ne peut pas être composé
dans la forme fonctionnelle; la restriction est syntaxique, non sémantique.
!
Exemple
#include
<iostream.h>
int main()
{char c = 'a', * p_c
= &c;
typedef int* p_int;
p_int p_i;
p_i = p_int(p_c); // OK
// p_i = int*(p_c); // KO
cout << "
c = " << c << " *p_c = " << *p_c <<
" *p_i = " << *p_i << endl;
}
// résultat
c = a *p_c = a *p_i
= 97
Þ Exercice 1
1°) Créer une classe de nombres complexes
avec un constructeur devant prendre en compte toutes les situations possibles
d'initialisation de ses instances.
2°) Instancier quatre objets, dans des
situations d'initialisation différentes, de telle sorte que ce constructeur
soit appelé avec un transtypage fonctionnel. On constatera que la situation
peut être ambigüe.
#include
<iostream.h>
class complexe
{public:
float reel; float imaginaire;
complexe(double x=0, double y=0){reel = x;
imaginaire =y;} // constructeur inline
};
int
main() // initialisation avec
appel du constructeur et transtypage fonctionnel
{//
complexe z0 = {1,10}; //
initialisation traditionnelle interdite si constructeur défini
complexe
z1(1.5, -10.78); // 2
flottants
complexe
z2(-1,3); //
2 entiers et transtypage fonctionnel, identique à
//
complexe z2= complexe(-1,3);
complexe
z3 = complexe(); //
valeur par défaut, mais
// complexe
z3(); est interdit
complexe
z4 = complexe(-5); // un seul argument
identique à
// complexe z4(-5, 0);
complexe
z5(0,-5);
cout
<< "z1.reel = " << z1.reel << "\tz1.imaginaire
= " << z1.imaginaire << endl ;
cout
<< "z1.reel = " << z1.reel << "\tz1.imaginaire
= " << z1.imaginaire << endl ;
cout
<< "z2.reel = " << z2.reel << "\tz2.imaginaire
= " << z2.imaginaire << endl ;
cout
<< "z3.reel = " << z3.reel << "\tz3.imaginaire
= " << z3.imaginaire << endl ;
cout
<< "z4.reel = " << z4.reel << "\tz4.imaginaire
= " << z4.imaginaire << endl ;
cout << "z5.reel = "
<< z5.reel << "\tz5.imaginaire = " << z5.imaginaire
<< endl ;
}
// résultat
z1.reel = 1.5 z1.imaginaire = -10.78
z2.reel
= -1 z2.imaginaire = 3
z3.reel
= 0 z3.imaginaire = 0
z4.reel
= -5 z4.imaginaire = 0
z5.reel
= 0 z4.imaginaire = -5
Þ Exercice 2
1°) Créer une classe de nombres complexes
avec deux constructeurs. Il faudra redéfinir le constructeur par défaut pour
éviter l'ambiguïté de l'exemple précédent.
2°) Instancier cinq objets de telle sorte
que ces constructeurs soient appelés suite à un transtypage fonctionnel dans
cinq situations d'initialisation différentes de telle sorte qu'une situation
ambiguë soit impossible.
#include
<iostream.h>
class complexe
{public:
float reel; float imaginaire;
//constructeurs
complexe() {reel =0; imaginaire = 0;} // constructeur par défaut
complexe(double x, // x = 0 impossible car ambiguité avec le constructeur par défaut
double y=0 /* nécessaire pour z4 */)
{reel = x; imaginaire =y;}
};
int
main()
{//
initialisation avec appel des constructeurs et transtypage fonctionnel
complexe
z1(1,10), z2= complexe(-1,3), z3 = complexe(), z4(-5) , z5(0,-5);
cout
<< "z1.reel = " << z1.reel << "\tz1.imaginaire
= " << z1.imaginaire << endl ;
cout
<< "z2.reel = " << z2.reel << "\tz3.imaginaire
= " << z2.imaginaire << endl ;
cout
<< "z3.reel = " << z3.reel << "\tz3.imaginaire
= " << z3.imaginaire << endl ;
cout
<< "z4.reel = " << z4.reel << "\tz4.imaginaire
= " << z4.imaginaire << endl ;
cout
<< "z5.reel = " << z5.reel << "\tz5.imaginaire
= " << z5.imaginaire << endl ;
return(1);
}
//
résultat
z1.reel
= 1 z1.imaginaire = 10
z2.reel
= -1 z2.imaginaire = 3
z3.reel
= 0 z3.imaginaire = 0
z4.reel
= -5 z4.imaginaire = 0
z5.reel
= 0 z5.imaginaire = -5
Þ Destructeurs implicite et explicite
·
Le destructeur est une méthode appelée
implicitement quand une instance sort de la portée
de la classe.
·
Le destructeur
par défaut libère l'espace mémoire de chacune des données membres de l'instance.
·
Le destructeur
explicite de la classe C est défini à partir de l'opérateur ~ selon la syntaxe :
[C::]~C(argument(s)){....}
·
Un destructeur ne peut être surchargé car
son contexte d'utilisation est inconnu. Il est donc unique.
·
Le langage C++ définit l'opérateur new de gestion de l'allocation
dynamique qu'il est préférable d'utiliser à la place des fonctions
correspondantes traditionnelles de la bibliothèque C (malloc, calloc, realloc, etc...).
·
La fonction de la bibliothèque C de
restitution de l’espace alloué free est réalisée par
l'opérateur conjugué delete.
·
Ces deux opérateurs sont appelés implicitement ou explicitement par les constructeurs et destructeurs.
·
L'opérateur new effectue l'allocation mémoire sans initialisation et appelle si
nécessaire un constructeur. Il renvoie la constante NULL en cas d'échec.
·
La définition d'un objet se distingue de
la définition d'une instance qui
provoque toujours l'appel d'un constructeur.
·
La définition du constructeur par défaut est nécessaire pour initialiser chaque
composante d'un tableau d'instances.
·
La définition de la taille du tableau
n'est pas obligatoire pour l'utilisation standard mais peut le devenir pour une
surcharge.
Þ Synopsis
new déclaration_de_type; // un objet
new classe; //
une instance de la classe
new classe[Taille_du_Tableau]; // un tableau d'instances d'une classe
new classe(valeur); // initialisation d'une instance par
transtypage fonctionnel
L'opérateur delete libère l'espace mémoire alloué par l'opérateur new selon la syntaxe :
delete
0; //
autorisé et sans effet.
delete
P //
libération de l'espace alloué à l'instance pointée par P
delete
[] P //
libération de l'espace alloué pour le tableau d'instances pointé par P
·
Les opérateurs new et delete
d'allocation et de désallocation de la mémoire doivent être utilisés de préférence
aux fonctions malloc et free car ils garantissent un meilleur
contrôle des types ainsi qu'une une initialisation correcte de ceux qui sont
définis par l'utilisateur.
·
Il ne faut pas mélanger les fonctions et
opérateurs d'allocation mémoire des langages C et C++, la gestion de la mémoire
étant différente.
·
Les opérateurs delete et delete[] ne doivent pas :
à
générer d'erreur lorsqu'on leur transmet
en argument un pointeur nul,
à
être utilisés sur un pointeur de type void.
·
Il est essentiel d'utiliser
respectivement l'opérateur delete
avec les pointeurs retournés par l'opérateur new et l'opérateur delete[]
avec ceux qui sont retournés par l'opérateur new[].
·
L'opérateur new[] alloue la mémoire et crée les objets dans l'ordre croissant
des adresses. Inversement, l'opérateur delete[]
détruit les objets du tableau dans un ordre décroissant des adresses.
!
Exemple 1
Soit le constructeur de la classe entier qui
initialise tout entier à 0. Définir
a) un pointeur initialisé sur un entier (int) indéfini,
b) un pointeur initialisé sur un entier (int) défini,
c) un pointeur sur un tabeau de la classe entier initialisé à 0,
d) un pointeur sur un tableau d’entier non initialisé.
#include <iostream.h>
#define Taille 10
class entier {
public:
int nombre ;
int *ptnombre;
entier(){nombre=0; ptnombre=(int *) NULL; } //
constructeur par défaut
~entier(){cout << "destructeur"
<< endl; delete []
ptnombre ; }
};
int main()
{int *pi = new
int; // initialisé mais indéfini
cout
<< "*pi=" << *pi << endl ;
delete pi;
int a =
25;
int *pl
= &a;
cout
<< "*pl=" << *pl << endl ;
int *pj
= new int(543); // initialisation d'un pointeur sur
la constante entière 543
cout
<< "*pj=" << *pj << endl ;
delete pj;
int
*tableau = new int[Taille];
int i;
cout
<< "tableau :" << endl;
for(i=0;i<Taille;i++) cout << tableau[i] << "
";
cout
<< endl;
delete [] tableau;
entier
*ptab= new entier [Taille]; // appel du constructeur explicite
cout
<< "tableau ptab : constructeur explicite" << endl;
for(i=0;
i<Taille; i++) cout << (*ptab++).nombre << " ";
entier
Tab[Taille]; // appel du
constructeur explicite
cout
<< "\ntableau Tab : constructeur explicite" << endl;
for(i=0;
i<Taille; i++) cout << Tab[i].nombre << " "; cout
<< endl ;
cout
<< "tableau pk : constructeur int implicite" << endl;
int *pk
= new int [Taille] ; // création d'un tableau d'entiers non
initialisés
for(i=0; i< Taille;i++) cout << *pk++ << " ";
cout <<endl ;
}
// résultat
*pi=0
*pl=25
*pj=543
tableau :
543 0 0 3369 0 0 0 0 0 0
tableau ptab : constructeur explicite
0 0 0 0 0 0 0 0 0 0
tableau Tab : constructeur explicite
0 0 0 0 0 0 0 0 0 0
tableau pk : constructeur int implicite
0 0 0 0 0 0 0 0 0 0
destructeur
destructeur
destructeur
destructeur
destructeur
destructeur
destructeur
destructeur
destructeur
destructeur
!
Exemple 2
1°) Définir un constructeur explicite des
données membres de la classe Produit.
2°) Utiliser le constructeur par défaut
implicite. Conclusion.
// Classe Produit :
allocation dynamique pour la donnée
membre Nom avec l’opérateur new
#include <iostream.h>
#include <string.h>
#include <stdlib.h> // pour exit()
class Produit
{char
* nom; float prix;
public:
Produit
(const char * Nom, float Valeur) // constructeur
{nom
= new char[strlen(Nom)+1];
if
(nom == NULL) {cerr << "allocation impossible" << endl ;
exit (1);}
strcpy
(nom, Nom);
prix
= Valeur;
}
void AfficheToi() const
{cout
<< "Produit " <<
nom << " de prix " << prix << endl ;}
};
int
main()
{ Produit
P1("SAVON",7.5);
Produit
* Ptr = &P1;
Ptr->AfficheToi();
Ptr
= new Produit("FARINE 1KG",
15.5);
Ptr->AfficheToi();
//
L'instruction :
//
Produit * Ptr2 = new Produit[100];
//
provoque l'erreur de compilation :
//
Cannot find default constructor to initialize array element of type 'Produit'
return
1;
}
// résultat
Produit SAVON de prix 7.5
Produit FARINE 1KG de prix 15.5
Dans l'exemple ci‑après, la chaîne de
caractères doit être initialisée avec un caractère au moins.
!
Exemple 3
// Classe Produit : version avec les opérateurs new et delete
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
class Produit {private:
char
* nom;
float
prix;
char
* alloue(int LgrMem)
{//
fonction membre privée d'allocation pour la donnée membre nom
char
* Ptr = new char[LgrMem];
if
(Ptr == NULL) {cerr << "plus de place en mémoire" << endl
; exit (1); }
return
Ptr;
}
public:
Produit( const char * Nom, float Valeur) //
un constructeur
{nom
= alloue(strlen(Nom)+1);
strcpy
(nom, Nom);
prix
= Valeur;
}
Produit() //
le constructeur par défaut
{nom
= alloue(1); nom[0] = '\0';
prix
= 0;
cout
<< "constructeur par défaut" << endl ;
}
void AfficheToi() const
{cout
<< "Produit " <<
nom << " de prix " << prix << endl ; }
};
int main()
{ Produit
P1("SAVON",7.5); //
appel du constructeur
P1.AfficheToi();
Produit
*Ptr = new Produit[2]; // 2 instances et appel du
constructeur par défaut
for (int
k=0; k<2; k++) Ptr[k].AfficheToi();
Produit
TabProd[2]; //
Idem cas précédent
}
// résultat
Produit SAVON de prix 7.5
constructeur par défaut
constructeur par défaut
Produit
de prix 0
Produit
de prix 0
constructeur par défaut
constructeur par défaut
!
Remarque
Le traitement commun exécuté par les deux
constructeurs est implémenté sous la forme d'une fonction membre privée,
appelable par chacun.
Un opérateur est
implémenté sous la forme d'une fonction appelée fonction opérateur ce qui permet de définir des
opérateurs pour les classes. La surcharge des fonctions étant autorisée, il est
licite de surcharger certains opérateurs prédéfinis, par
exemple l'opérateur +, pour additionner deux nombres complexes.
!
Règles générale de syntaxe
·
Un opérateur
(prédéfini) surchargé est défini comme une fonction dont la signature est constituée du mot clé opérator suivi de son
identificateur :
type_resultat operator opérateur_surchargé(type
argument,…)
·
La définition originelle des opérateurs
sur les types de base ne peut pas être modifiée.
·
Il est interdit de définir de nouveaux
symboles d'opérateur (par exemple **).
·
Un opérateur
surchargé est un méthode définie dans ou
à l'extérieur de la classe.
à
La syntaxe d'utilisation est différente
dans chaque cas.
à
La version membre impose que l'argument
de gauche soit une instance de la classe de l'opérateur.
·
La précédence
et l'arité (nombre d'opérandes) de
l'opérateur restent celles définies à l'origine, quelle que soit la syntaxe
utilisée.
·
Les opérateurs =, [], () et -> sont
toujours membres de la classe où ils sont surchargés.
Þ Maximes associées à la surcharge des opérateurs
·
Ne jamais surcharger un opérateur dont le
sens est "intuitif" pour la classe concernée dans un sens différent.
·
Surcharger l'opérateur d'affectation en
priorité.
·
Vérifier que la sémantique de la version
surchargée est compatible avec les types de base des opérandes.
·
Un opérateur surchargé ne modifiant pas
ses opérandes doit retourner une instance, pas une référence.
Þ Opérateurs autorisés
Tous les opérateurs du langage C++ peuvent
être surchargés à l'exception des opérateurs ::, .*, ?:, sizeof, typeid, static_cast, dynamic_cast,
const_cast, reinterpret_cast.
Þ Définition des opérateurs internes
Une première
technique de surcharge des opérateurs consiste à les considérer comme des
méthodes internes de la classe sur laquelle ils opèrent. Soit Operator l'opérateur surchargé,
l'instruction
A
Operator B
se traduit
par :
A. Operator (B)
où Operator représente la fonction
opérateur associée. On en déduit que dans
une classe, la fonction opérateur
surchargée comporte toujours un argument de moins (le plus à gauche) que
l'opérateur non surchargé, l'objet qui traite le message étant un paramètre
implicite de l'appel.
Þ
Type de
retour
La fonction
opérateur retourne un objet temporaire de la fonction opérateur ou l'objet
lui-même (pointeur this).
!
Exemple 1
#include
<iostream.h> // addition surchargée
pour des complexes
//
surcharge de l'opérateur +
class complexe
{public:
float reel; float im;
complexe operator + (complexe z)
{complexe
aux;
aux.reel =reel+z.reel; aux.im =im+z.im;
return aux;
}
};
int
main()
{complexe
z1 = {1,10}, z2 = {3,-1}, z;
z = z1+z2; //
en fait z1.+(z2)
cout << "z.reel = " <<
z.reel << "\tz.im = " << z.im << endl ;
return(1);
}
!
Exemple 2
Même cas que précédemment, la fonction
surchargée étant ici définie comme une fonction inline, définie à l'extérieur de la classe.
#include
<iostream.h>
//
surcharge de l'opérateur définie à l'extérieur de la classe, dans une fonction
qui peut être inline
class complexe
{public:
float reel; float im;
complexe operator + (complexe z);
};
inline
complexe complexe::operator + (complexe z)
{complexe
aux; aux.reel =reel+z.reel; aux.im =im+z.im; return aux; }
int
main()
{complexe
z1 = {1,10}, z2 = {3,-1}, z;
z = z1+z2;
cout << "z.reel = " <<
z.reel << "\tz.im = " << z.im;
return(1);
}
Þ Règle complémentaire
Un des arguments d'un opérateur surchargé non membre d'une classe doit en être une
donnée membre d'accès public.
Þ Syntaxe
Type_résultat operator
<symbole_associé_à_l'opérateur>
(liste_des_paramètres_formels)
{corps de la méthode associée à
l'opérateur surchargé}
!
Exemple
#include <iostream.h> // surcharge de l'opérateur + pour des
instances de la classe complexe
class complexe {public : float reel; float im;
complexe(float,float);
};
complexe::complexe(float x=0 , float y = 0)
{reel=x; im=y;}
const complexe operator + (const complexe
z1, const complexe z2)
{complexe aux;
aux.reel
=z1.reel+z2.reel; aux.im =z1.im+z2.im;
return
aux;
}
int main()
{complexe z1(1,10), z2(3,-1), z;
z =
z1+z2; // les données membres d'accès public sont accessibles par l'opérateur
surchargé.
cout
<< "z.reel = " << z.reel << "\tz.im = "
<< z.im << endl;
return(1);
}
// résultat
z.reel = 4 z.im
= 9
La surcharge d'un opérateur non membre d'une
classe nécessite l'accès à certaines données membre de la classe donc la levée (partielle ou totale) de
l'encapsulation des données privées.
Þ Définition
·
Une fonction,
une (toutes les) méthode(s) d'une classe peu(ven)t être autorisée(s) à accéder
à la partie privée d'une autre classe (donnée ou méthode) si elle y est (sont)
déclarée(s) amie(s) par le qualificatif friend.
·
Leur syntaxe d'utilisation est inchangée.
·
Une fonction peut être amie de plusieurs
classes.
·
La relation d'amitié n'est pas transitive : les amies de mes
amies ne sont, par défaut, pas mes amies,.
Þ Synopsis
friend
type_retour fonction_amie(liste
type et arguments);
friend
type_retour
identificateur_de_la_classe::méthode_amie(liste type et arguments);
friend
type_retour
[identificateur_de_la_classe_amie];
!
Exemple
class X {
// liste des
fonctions amies des objets de la classe X
friend void f(int, float); // la fonction f
friend void Y::g(char*, int); // la méthode g de la classe Y
friend class Z; //
toutes les méthodes de la classe Z
};
class matrice {
friend vecteur
mult(matrice&, vecteur&); //
la fonction mult est amie de la classe matrice
...
};
class vecteur {
{friend vecteur
matrice::mult(vecteur&);
// la méthode mult
de la classe matrice est amie de la classe vecteur
...
};
!
Exercice
Surcharger l'opérateur + pour des nombres
complexes, la fonction surchargée étant externe
et amie de la classe complexe.
#include
<iostream.h>
class complexe
{private:
float reel; float
im;
friend complexe
operator + (complexe, complexe);
public :
complexe(double,
double); // constructeur
void affiche(char *);
};
complexe::complexe(double
x=0, double y =0)
{reel =x; im=y;}
void complexe::affiche(char *
Texte)
{cout << Texte
;
cout <<
"partie réelle = " << reel << "\tpartie imaginaire =
" << im << endl;}
complexe operator + (complexe z1, complexe
z2)
{complexe aux;
aux.reel =z1.reel+z2.reel;
aux.im =z1.im+z2.im;
return aux;
}
int main()
{complexe z1(1,10),
z2(3,-1), z;
z1.affiche("z1 :\t\t");
z2.affiche("z2 :\t\t");
z = z1+z2;
z.affiche("z=z1 + z2 :\t");
return(1);
}
// résultat
z1 : partie réelle = 1 partie imaginaire = 10
z2 : partie réelle = 3 partie imaginaire = -1
z=z1 + z2 partie réelle = 4 partie imaginaire = 9
La surcharge de l'opérateur < permet de
définir une relation d'ordre entre instances d'une classe
donnée.
!
Exemple
La comparaison du prix de deux instances de la
classe Produit conduit à surcharger l'opérateur <.
//
Classe Produit : surcharge de l'opérateur <
#include
<iostream.h>
#include <string.h>
#include
<stdlib.h>
class Produit {
private: char * nom; float prix;
public:
Produit (const char * Nom, float Valeur) //
constructeur
{nom = new char[strlen(Nom)+1];
if (nom == NULL) {cerr <<
"allocation impossible" << endl ; exit (1); }
strcpy (nom, Nom);
prix = Valeur;
}
~Produit() {delete nom;} //
destructeur
// surcharge de l'opérateur <
int operator < (const Produit & P) const {return (prix < P.prix);}
}; // fin de la définition de la
classe Produit
int main()
{Produit P1("SAVON
PROMO",7.5);
Produit P2("SAVON
MARSEILLE", 9.3);
if (P1 < P2) // inférieur équivalent à "moins cher
que"
cout << "PROMO BON
MARCHE" << endl ;
// if (P1 < 5.5) cout << "vraiment pas cher"
<< endl ;
// erreur de compilation : Illegal
structure operation
}
//
résultat
PROMO
BON MARCHE
!
Remarque
Le programme ci‑dessus ne permet pas de
comparer directement une instance de la classe Produit à un argument flottant
le compilateur ne disposant pas de règles implicites de conversion d'un
flottant en une instance de la classe Produit.
La règle du transtypage d'un objet d'un type donné vers un type classe va
apporter une solution à ce problème.
!
Syntaxe
Un constructeur
de la classe C avec un argument
unique d'un type donné T définit une règle
de transtypage de l'objet de type T
en une instance de la classe C.
!
Exemple
//
Classe Produit : version pour l'étude de la surcharge d'opérateurs
#include
<iostream.h>
#include
<string.h>
#include
<stdlib.h>
class Produit {
private:
char
* nom;
float
prix;
void fixeNom (const char * Chaine)
{nom
= new char[strlen(Chaine)+1];
if
(nom == NULL) {cerr << "allocation impossible" << endl ;
exit (1); }
strcpy
(nom, Chaine);
}
public:
//
constructeurs
Produit
(const char * Nom, float Valeur)
{fixeNom
(Nom); prix = Valeur; }
Produit
(float Montant) // conversion d'un flottant en une instance de la classe
Produit
{fixeNom
("PRODUIT TEMOIN"); prix = Montant; }
//
destructeur
~Produit()
{delete nom; }
//
surcharge de l'opérateur <
int
operator < (const Produit & P)
const {return (prix < P.prix);}
};
// fin de la définition de la classe Produit
int
main()
{Produit P1("SAVON
PROMO",7.5);
Produit P2("SAVON
MARSEILLE", 9.3);
if (P1 < P2) cout <<
"PROMO TRES BON MARCHE" << endl ;
// appel du constructeur
Produit(float)
if (P1 < 5.5) cout <<
"VRAIMENT PAS CHER" << endl ;
else cout << "PRIX
NORMAL" << endl ;
// if (10.5 < P1) cout <<
"PROMO TROP CHERE" << endl ; // illegal structure operation
// if (Produit(10.5) < P1) cout
<< "PROMO TROP CHERE" << endl ; // OK
}
//
résultat
PROMO
BON MARCHE
PRIX
NORMAL
·
La méthode précédente permet de comparer
une instance de la classe produit à un nombre flottant. La fonction surchargée utilisant un argument implicite,
l'opération réciproque n'est pas possible pour des raisons syntaxiques.
·
L'utilisation de fonctions amies permet de résoudre ce problème de
syntaxe l'opérateur surchargé n'utilisant alors pas d'argument implicite.
!
Exemple
#include
<iostream.h>
#include
<string.h>
#include
<stdlib.h>
class Produit {private:
char
* nom;
float
prix;
void fixeNom (const char * Chaine)
{nom
= new char[strlen(Chaine)+1];
if
(nom == NULL) {cerr << "allocation impossible" << endl ;
exit (1); }
strcpy
(nom, Chaine);
}
friend
int operator < (const Produit
& , const Produit &);
public:
// constructeurs
Produit
(const char * Nom, float Valeur)
{fixeNom
(Nom); prix = Valeur; }
Produit
(float Valeur) // conversion
d'un float en une instance de la classe Produit
{fixeNom
("PRODUIT TEMOIN"); prix =
Valeur; }
//
destructeur
~Produit()
{delete nom;}
};
// fin de la définition de la classe Produit
// surcharge de l'opérateur <
int
operator < (const Produit & P, const
Produit & Q)
{return
(P.prix < Q.prix);}
int
main()
{Produit
P1("SAVON PROMO",20.5);
Produit
P2("SAVON MARSEILLE", 2.3);
if
(P2 < P1) cout << "PROMO
PAS BON MARCHE" << endl ;
if
(P2 < 5.5) cout << "P2 PAS CHER" << endl ;// appel du
constructeur Produit(float)
if
(1.5 < P2) cout << "PROMO TROP CHERE" << endl ;
return(1);
}
//
résultat
PROMO
PAS BON MARCHE
P2
PAS CHER
PROMO
TROP CHERE
La surcharge de l'opérateur [] est licite comme l'illustre l'exemple ci‑dessous
où l'opérateur surchargé [] fournit l'indice du caractère recherché.
!
Exemple
1°) Définir une classe Ligne constituée
d’instance de ligne de 80 caractères avec un constructeur qui initialise une
ligne avec un unique caractère donné.
2°) Surcharger l’opérateur crochet de
telle sorte que l’utilisateur puisse directement modifier une composante
(Lvalue).
Version 1
#define TAILLE 80
#include
<iostream.h>
#include
<stdlib.h>
class Ligne // une instance est une ligne de TAILLE
caractères
{private:
char
t[TAILLE+1];
public:
//
appel du constructeur
Ligne(char
C = ' '); // ligne vide
par défaut
//
position d'un caractère de la ligne rang de 1 à TAILLE
char
& operator [](int Rang)
{if
(Rang < 1 || Rang > TAILLE)
{cerr
<< "rang inacceptable pour une position de Ligne" << endl
; exit(1);}
return t[Rang-1];
}
};
Ligne::Ligne(char
C)
{for (int
k=0; k<TAILLE; k++) t[k]=C; t[TAILLE]='\0'; }
int
main()
{Ligne
L, La('A');
cout
<< "La[3] = " << La[3] << endl ;
//
modification possible de la position puisque l'opérateur surchargé retourne une
référence.
La[3]
= 'Z';
cout
<< "La[3] = " << La[3] << endl ;
La[2]
= La[3];
cout
<< "La[2] = " << La[2] << endl ;
return
1;
}
//
résultat
La[3]
= A
La[3]
= Z
La[2]
= Z
Version 2
#define TAILLE 80
#include <iostream.h>
#include <stdlib.h>
class Ligne //
une instance est une ligne de TAILLE caractères
{private:char t[TAILLE+1];public:Ligne(); //
constructeur par défaut
Ligne(char);// constructeur en général
// position d'un caractère de la ligne rang de 1
à TAILLE
char & operator [](int Indice)
{cout << "Opérateur surchargé "
<< endl;
if (Indice < 1 || Indice > TAILLE)
{cerr <<"rang inacceptable pour une
position de Ligne"<< endl; exit(1);}
return
t[Indice-1];
}
};
Ligne::Ligne()
{cout << "Constructeur par défaut :
" << endl;
for(int
k=0; k < TAILLE; k++) t[k]=' ';t[TAILLE]='\0';}
Ligne::Ligne(char C)
{cout << "Constructeur "
<< endl;
for (int
k=0; k<TAILLE; k++) t[k]=C; t[TAILLE]='\0';}
int main()
{Ligne L, La('A');
cout << "La[3] = " <<
La[3] << endl ;
// modification possible de la position puisque
l'opérateur surchargé retourne une référence.
La[3] = 'Z';
cout << "La[3] = " <<
La[3] << endl ;
La[2] = La[3];
cout << "La[2] = " <<
La[2] << endl ;
char toto = La[3];
cout << "toto = " << toto
<< endl;
char chaine[TAILLE];
chaine[5] = 'x';
cout << "chaine[5]=" <<
chaine[5] << endl;
return 1;
}
// résultat
Constructeur par défaut :
Constructeur
Opérateur surchargé
La[3] = A
Opérateur surchargé
Opérateur surchargé
La[3] = Z
Opérateur surchargé
Opérateur surchargé
Opérateur surchargé
La[2] = Z
Opérateur surchargé
toto = Z
chaine[5]=x
Supposons que l’on puisse surcharger
l’opérateur d’affectation. L’instruction
Class Essai {…}
Essai A, B ;
A=B ;…
provoque l’affectation (surchargée) de A par B
donc la copie membre à membre de l’instance B dans A. Il est donc nécessaire de
copier les instances membre à membre.
Þ Définition
·
Le constructeur
copie crée, implicitement ou explicitement, une instance d'une classe
identique à une autre, préexistante.
·
Il est appelé dans toute instanciation avec initialisation.
·
L’utilisation du constructeur copie implicite peut poser des problèmes comme
l'illustre l'exemple ci‑dessous.
!
Exemple
#include
<iostream.h>
#include
<string.h>
#include
<stdlib.h>
class Produit {
private:
char
* nom; float prix;
public: //
constructeur
Produit
(const char * Nom, float Valeur)
{nom
= new char[strlen(Nom)+1];
if
(nom == NULL) {cerr << "allocation impossible" << endl ;
exit (1); }
strcpy
(nom, Nom);
prix
= Valeur;
}
~Produit()
{delete nom;} // destructeur
//
Classe Produit : un bug du constructeur copie implicite avec la transmission
par valeur
//
Une solution : transmission par référence
int
operator < (const Produit &P) const //
surcharge de l'opérateur <
{return
(prix < P.prix);}
void AfficheToi(char * Titre) const
{cout
<< Titre << ": " << nom << ", "
<< prix <<endl ;}
};
// fin de la définition de la classe Produit
int
main()
{Produit
P1("SAVON PROMO",7.5);
Produit
P2("SAVON MARSEILLE", 9.3);
P2.AfficheToi("P2");
if
(P1 < P2) cout << "PROMO BON MARCHE" << endl ;
Produit
P3("YAOURT",7.6);
P3.AfficheToi("P3");
P2.AfficheToi("P2");
}
//résultat
P2:
SAVON MARSEILLE, 9.3
PROMO
BON MARCHE
P3:
YAOURT, 7.6
P2:
SAVON MARSEILLE, 9.3
//
résultat sans passage par référence
P2:
SAVON MARSEILLE, 9.3
PROMO
BON MARCHE
P3:
YAOURT, 7.6
P2:
YAOURT, 9.3
Le deuxième résultat d'exécution est faux car
lors de l'exécution de l'appel de l'opérateur surchargé, le mécanisme de
transmission par valeur nécessite la création d'une instance temporaire, locale
à la fonction, copie de l'instance P2. Le constructeur par défaut recopie
membre à membre les données membres prix
et nom. Or, la dernière donnée membre
copiée pointe sur la région de mémoire allouée pour P2 et est restituée à la
fin de l'exécution de la fonction. L'instance P2 ne dispose plus alors de
l'espace nécessaire. C'est un bug connu du langage.
Þ Constructeur copie par défaut, constructeur copie explicite
·
Une simple copie des champs d'une
instance vers une autre ne copie que les pointeurs.
·
Il est préférable :
à
d'éviter l'utilisation du constructeur
copie implicite en le déclarant d'accès privé,
à
d'utiliser la transmission par référence.
à
de réécrire le code du constructeur
copie.
Þ Synopsis
Identificateur_de_la_classe(type_retourné argument_formel)
Le lecteur pourra s'assurer que le programme
ci‑dessous fonctionne correctement, et que l'opérateur surchargé
s'exécute sans problème avec des arguments transmis par valeur ou par
référence.
!
Exemple
#include <iostream.h>
#include
<string.h>
#include
<stdlib.h>
class Produit
{private: char *
nom; float prix;
friend int operator < (const Produit &, const Produit&);
public:
//
constructeur
Produit
(const char * Nom, float Valeur)
{nom
= new char[strlen(Nom)+1];
if (nom == (char *) NULL) {cerr <<
"allocation impossible" << endl ; exit (1); }
strcpy (nom, Nom);
prix = Valeur;
}
//
constructeur copie
Produit
(const Produit & Source)
{nom
= new char[strlen(Source.nom)+1];
if (nom == (char *) NULL) {cerr <<
"allocation impossible" << endl ; exit (1);}
strcpy (nom, Source.nom);
prix = Source.prix;
cout << "constructeur copie"
<< endl;
}
~Produit()
{delete nom;}
void AfficheToi(char * Titre) const
{cout
<< Titre << ": " << nom << ", "
<< prix <<endl ;}
};
// fin de la définition de la classe Produit
//
surcharge de l'opérateur <
int
operator < (const Produit &P, const Produit & Q)
{cout
<< "appel de l'opérateur surchargé" << endl; return
(P.prix < Q.prix);}
int
main()
{Produit
P1("SAVON PROMO",7.5);
Produit
Double1(P1);
Produit
P2("SAVON MARSEILLE", 9.3);
Produit
Double2 = P2; // l'affectation appelle le
constructeur copie
P2.AfficheToi("P2");
if
(P1 < P2) cout << "PROMO BON MARCHE" << endl ;
Produit
P3("YAOURT",7.6);
P3.AfficheToi("P3");
P2.AfficheToi("P2");
Double2.AfficheToi("Double2");
}
//
résultat
P1:
SAVON PROMO, 7.5
constructeur
copie
constructeur
copie
P2:
SAVON MARSEILLE, 9.3
appel
de l'opérateur surchargé
PROMO
BON MARCHE
P3:
YAOURT, 7.6
P2:
SAVON MARSEILLE, 9.3
Double2:
SAVON MARSEILLE, 9.3
L'opérateur d'affectation non
surchargé entre deux instances d'une même classe effectue l'opération
membre à membre ce qui conduit à des problèmes d'allocation mémoire similaires
à ceux rencontrés avec le constructeur
copie par défaut comme l'illustre le programme ci‑dessous :
!
Exemple
//
Classe Produit : opérateur d'affectation surchargé utilisant le constructeur
copie par défaut
#include
<iostream.h>
#include
<string.h>
#include
<stdlib.h>
class Produit {
private:
char
* nom; float prix;
public:
//
constructeur
Produit
(const char * Nom, float Valeur = 10)
{nom
= new char[strlen(Nom)+1];
if
(nom == (char *) NULL) {cerr << "allocation impossible"
<< endl ; exit (1);}
strcpy
(nom, Nom);
prix
= Valeur;
}
//
constructeur copie
Produit
(const Produit & Source)
{cout
<<"constructeur copie"<<endl;
nom = new char[strlen(Source.nom)+1];
if
(nom == (char *) NULL) {cerr << "allocation impossible"
<< endl ; exit (1);}
strcpy
(nom, Source.nom);
prix
= Source.prix;
}
~Produit()
{delete nom;}
void AfficheToi(char * Titre) const
{cout
<< Titre << ": " << nom << ", "
<< prix <<endl ;}
};
// fin de la définition de la classe Produit
int
main()
{Produit
P1("YAOURT", 8.3);
Produit
P2("SAVON PROMO",7.5);
Produit
P3("CUVETTE",23);
Produit
P4("DISQUE COMPACT",120);
P1.AfficheToi("produit
P1");
P2.AfficheToi("produit
P2");
P1
= P2;
P1.AfficheToi("produit
P1 après exécution de P1=P2");
P1
= P3 = P4;
P1.AfficheToi("produit
P1 après exécution de P1=P3=P4");
P3.AfficheToi("produit
P3 après exécution de P1=P3=P4");
Produit
P5 = "CAHIER"; //constructeur
Produit("CAHIER",10)
P5.AfficheToi("P5");
P5
= "SUCRE 1 KG"; // utilisation
du constructeur copie par défaut par l'opérateur
P5.AfficheToi("P5"); // d'affectation non surchargé
P6=P5; // Appel du
constructeur copie
P6.AfficheToi("P6");
}
// fin de main
//
résultat
produit P1: YAOURT,
8.3
produit P2: SAVON
PROMO, 7.5
produit P1 après
exécution de P1=P2: SAVON PROMO, 7.5
produit P1 après
exécution de P1=P3=P4: DISQUE COMPACT, 120
produit P3 après
exécution de P1=P3=P4: DISQUE COMPACT, 120
P5: CAHIER, 10
P5: SUCRE 1 KG, 10
constructeur copie
P6: SUCRE 1 KG, 10
Segmentation Fault
(core dumped) // selon
l'implémentation
Þ Surcharge de l'opérateur d'affectation
La fonction
opérateur d'affectation surchargée doit retourner une référence car c'est
une Lvaleur. Elle s'écrit dans l’exemple précédent :
Produit
& operator = (const Produit &
Source) // surcharge de
l'opérateur =
{delete nom; // la
mémoire doit être réinitialisée
nom
= new char[strlen(Source.nom)+1];
if
(nom == (char *) NULL) {cerr << "allocation impossible"
<< endl ; exit (1);}
strcpy
(nom, Source.nom);
prix
= Source.prix;
return
* this; //
pointeur sur l'instance de l'appel.
}
//
résultat
produit
P2: SAVON PROMO, 7.5
produit
P1: YAOURT, 8.3
produit
P1 après exécution de P1=P2: SAVON PROMO, 7.5
P5:
CAHIER, 10
P5:
SUCRE 1 KG, 10
Ces deux
opérateurs ont une sémantique
différente selon leur utilisation en notation pré ou post fixée. En
notation préfixée, l'incrémentation
est effectuée avant l'affectation; en
notation postfixée, après.
·
En
sémantique préfixée, la fonction
surchargée n'a pas d'argument et retourne une référence sur l'objet lui-même.
·
En
sémantique postfixée, la fonction
surchargée utilise un argument fictif
entier (type int) et retourne la valeur (entière) de l'objet modifié.
!
Exemple
#include
<iostream.h>
class Entier
{public:
int i;
Entier(int j){i=j; return;} // constructeur
Entier operator++(int) //
Post incrémentation (affectation puis incrémentation)
{Entier tmp(i); //
instanciation et appel du constructeur
i++;
return tmp;
}
Entier &operator++(void) // Pré incrémentation (incrémentation puis affectation)
{i++; return *this;}
};
int main()
{Entier i(1),j=i;
cout << "i = " << i.i << " j = " <<
j.i<< endl;
i=++j; cout
<< "i = " << i.i << " j = " <<
j.i<< endl;
i=j++; cout
<< "i = " << i.i << " j = " <<
j.i<< endl;
}
// Résultat
i = 1 j = 1
i = 2 j = 2
i = 2 j = 3
L'opérateur fonctionnel d'appel de fonctions () peut être surchargé ce qui est très utile en
raison de sa n-arité (il peut avoir n opérandes). Il peut être utilisé dans des
classes de matrices pour permettre d'écrire matrice(i,j,k).
!
Exercice : analyser le programme
suivant
#include <iostream.h>
class matrice
{typedef double
*ligne;
ligne *lignes;
unsigned short int n; // Nombre de lignes (1er paramètre).
unsigned short int m; // Nombre de colonnes (2ème paramètre).
public:
// constructeurs et destructeurs
matrice(unsigned short int, unsigned short
int);
matrice(const matrice &);
~matrice(void);
// opérateurs surchargés
matrice &operator=(const matrice
&);
double &operator()(unsigned short int ,
unsigned short int);
matrice operator+(const matrice &)
const;
matrice operator-(const matrice &)
const;
matrice operator*(const matrice &)
const;
};
// constructeur
matrice::matrice(unsigned
short int nl, unsigned short int nc)
{n = nl;
m = nc;
lignes = new ligne[n];
for (unsigned short int i=0; i<n;
i++)lignes[i] = new double[m];
return;
}
// constructeur
copie
matrice::matrice(const
matrice &source)
{m = source.m;
n = source.n;
lignes = new ligne[n];
for (unsigned short int i=0; i<n; i++)
{lignes[i] = new double[m];
for (unsigned short int j=0; j<m;
j++)lignes[i][j] = source.lignes[i][j]; // Copie
}
return;
}
// destructeur
matrice::~matrice(void)
{unsigned short
int i;
for (i=0; i<n; i++) delete[] lignes[i];
delete[]
lignes;
return;
}
// Affectation de
matrice
matrice
&matrice::operator=(const matrice &source)
{if (source.n!=n
|| source.m!=m) // Vérifie les
dimensions.
{unsigned short int i;for (i=0; i<n;
i++) delete[] lignes[i];
delete[]
lignes; // Détruit…
m = source.m;
n = source.n;
lignes = new ligne[n]; // et
réalloue.
for (i=0; i<n; i++) lignes[i] = new double[m];
}
for (unsigned short int i=0; i<n; i++)
// Copie
for (unsigned short int j=0; j<m;
j++)lignes[i][j] = source.lignes[i][j];
return *this;
}
// Surcharge de
l'opérateur ()
double &matrice::operator()(unsigned
short int i,unsigned short int j)
{return
lignes[i][j];}
// Addition de
matrices
matrice
matrice::operator+(const matrice &m1) const
{matrice tmp(n,m);
for (unsigned short int i=0; i<n;
i++) // Double boucle.
for (unsigned short int j=0; j<m;
j++)
tmp.lignes[i][j] =
lignes[i][j]+m1.lignes[i][j];
return tmp;
}
// Soustraction de
matrices
matrice
matrice::operator-(const matrice &m1) const
{matrice tmp(n,m);
for (unsigned short int i=0; i<n;
i++) // Double boucle.
for (unsigned short int j=0; j<m;
j++)
tmp.lignes[i][j]=lignes[i][j]-m1.lignes[i][j];
return tmp;
}
// Multiplication
de matrices
matrice
matrice::operator*(const matrice &m1) const
{matrice
tmp(n,m1.m);
for (unsigned short int i=0; i<n;
i++) // Double boucle.
for (unsigned short int j=0; j<m1.m;
j++)
{tmp.lignes[i][j]=0.; // Produit scalaire.
for (unsigned short int k=0; k<m; k++)
tmp.lignes[i][j] +=
lignes[i][k]*m1.lignes[k][j];
}
return tmp;
}
void imprimer(matrice m, const char * chaine,const int ligne, const int
colonne)
{cout <<
"matrice " << chaine << endl;
for(int i = 0; i < ligne; i++)
{for(int j =0; j < colonne; j++) cout
<< m(i,j) << " "
;
cout << endl;
}
}
int main()
{int ligne,
colonne;
cout << "lignes : " ;
cin >> ligne ;
cout << endl;
cout << "colonnes : ";
cin >> colonne ;
cout << endl;
matrice m(ligne,colonne),n(ligne,colonne),
p(ligne,colonne);
for(int i=0;i<ligne;i++) for(int
j=0;j<colonne;j++) m(i,j)=n(i,j)=i+j;
p = m+n;
imprimer(m,"m , n",ligne,colonne);
imprimer(m-n,"m-n",ligne,colonne);
imprimer (p,"m+n",ligne,colonne);
imprimer(m*n,"m*n",ligne,colonne);
}
La surcharge de l'opérateur de transtypage
permet des conversions entre des classes différentes de même sémantique.
!
Exemple
Une chaîne de caractères de longueur variable d'une classe peut être convertie en une chaîne de caractère de
longueur fixe (un tableau de caractères) par surcharge de l'opérateur char const *:
Chaine::operator char const * (void)
const;
Cet opérateur
opère sur l'instance qui l'invoque.
9.13
Opérateurs de comparaison
Les opérateurs de comparaison doivent
toujours retourner une valeur booléenne.
Ainsi, dans la classe Chaine, les opérateurs de test d'identité et de
comparaison de deux chaînes de caractères peuvent être surchargés comme
suit :
bool Chaine::operator==(const Chaine &) const;
bool Chaine::operator<(const Chaine &) const;
Þ Définitions
·
L'opérateur
de déréférenciation * permet de
définir des classes sur les objets desquelles des pointeurs peuvent opérer.
·
L'opérateur
de référence & retourne une référence de l'objet sur lequel il s'applique.
·
L'opérateur
de sélection de membre ->
permet de définir des classes qui en encapsulent d'autres.
Þ
Type de
retour
·
Les
opérateurs de référence et d'indirection & et * retournent des
informations relatives à un objet d'un type quelconque.
·
L'opérateur
de sélection de membre -> retourne
un objet d'un type sur lequel il doit pouvoir à nouveau être appliqué (pointeur
sur structure, union ou classe, etc).
!
Exemple
#include <iostream.h>
struct Encapsulee
{int i;} objet;
// Classe
Surcharge_op des opérateurs surchargés
struct
Surcharge_op
{Encapsulee *
operator-> (void) const {return &objet;}
Encapsulee * operator & (void) const {return &objet;}
Encapsulee & operator * (void) const
{return objet;}
};
// Utilisation
void f(int i)
{Surcharge_op
entree;
entree->i=20; // Enregistre 20 dans objet.i
cout << "i = " << i
<<"\n" << " entree->i=" <<entree->i
<< endl;
(*entree).i = 30; // Enregistre 30 dans objet.i.
cout << " (*entree).i=" <<(*entree).i << endl;
Encapsulee *p = &entree;
p->i = 40; // Enregistre 40 dans objet.i.
cout << " p->i=" <<p->i << endl;
return ;
}
int main()
{void f(int);
int a=1, b=200;
f(a); f(b);}
// résultat
i = 1
entree->i=20
(*entree).i=30
p->i=40
i = 200
entree->i=20
(*entree).i=30
p->i=40
Les opérateurs
d'allocation dynamique de mémoire new
et new[], pouvant être surchargés,
peuvent opérer sur un nombre variable d'arguments dont le premier définit
l'adresse initiale de la zone de mémoire allouée.
Les opérateurs
conjugués delete et delete[] peuvent opérer sur un ou deux
arguments, le premier étant un pointeur générique (void*) sur l'objet à détruire, le deuxième s'il existe, de type size_t, contenant la taille de la zone
de mémoire à restituer.
·
Pour les
opérateurs new et delete, pas de problème la taille de
cette zone étant déterminée par le type de l'objet.
·
Pour un
tableau, sa taille doit être stockée avec ce dernier, souvent dans son en-tête.
On ne peut donc pas faire d'hypothèse sur la structure de la mémoire allouée.
Si l'opérateur delete[] est utilisé
avec comme unique argument l'adresse du tableau, la mémorisation de sa taille
est à la charge du programmeur. Dans ce cas, le compilateur transmet à
l'opérateur new[] la taille d'un objet multipliée
par leur nombre.
!
Exemple : détermination de la
taille de l'en-tête des tableaux
#include <iostream.h>
#define TAILLE 512
// surcharge des operateurs d'allocation
dynamique new[] et delete[]
int tampon[TAILLE]; // Buffer de stockage du tableau.
class Temp
{char i[17]; // indice nombre premier.
public:
//opérateur
new[] surchargé
static
void * operator new[](size_t taille)
{cout
<< "operateur new[] surchargé" << endl;return tampon;}
//opérateur delete surchargé
static
void operator delete[](void *p, size_t taille)
{cout
<< "Taille de l'en-tete : " ;
cout
<< taille-(taille/sizeof(Temp))*sizeof(Temp)<< endl;
return ;
}
};
int main(void)
{delete[] new Temp[10];
// void* adresse; adresse= new Temp [10]; delete
[] adresse;
return
0;
}
//
résultat
operateur new[] surchargé
Taille de l'en-tete : 8
Þ
Remarque
Le pointeur this n'est pas transmis aux opérateurs new, delete,
new[] et delete[] puisque lorsqu'ils s'exécutent, l'objet n'est pas encore
créé ou est déjà détruit.
Une classe peut référencer des données membres
ou des méthodes d'une autre classe, d'une façon similaire au langage C pour les
champs d'une structure.
!
Exemple
class
C {
private: IMBRIQUEE1 {int a;}; // le champ a privé dérive de IMBRIQUEE1
public:
IMBRIQUEE2 {int b;}; // le
champ b public dérive de IMBRIQUEE2
IMBRIQUEE1
f(lMBRIQUEE2);
…
}
Les classes IMBRIQUEE1 et IMBRIQUEE2 sont
définies à l'extérieur de la classe C.
Une donnée membre d'une classe imbriquée est par défaut cachée de la portée de la
classe englobante le contrôle d'accès s'y appliquant normalement.
!
Exemple
IMBRIQUEE1
C::f(IMBRIQUEE2 z) {...} //
KO : IMBRIQUEE1 hors de visibilité
C::IMBRIQUEE1
C::f(IMBRIQUEE2 z) {...} // OK,
C::IMBRIQUEE2 inutile
Pour la lecture, il est préférable de déclarer
la classe imbriquée à l'extérieur et utiliser les mots clés private et friend pour définir l'utilisation de ses données membres.
·
La liste des arguments des fonctions
membres, séparés par des virgules, est introduite par le délimiteur : .
·
L'ordre dans la liste est sans
importance.
·
Les arguments des constructeurs des
instances des classes membres sont spécifiés dans la définition du constructeur de la classe englobante, pas dans les
déclarations.
·
Le constructeur d'une instance de la classe
externe est appelé après ceux des instances membres, dans l'ordre de définition
dans la classe. L'ordre inverse est appliqué à la destruction.
·
Il peut être parfois nécessaire de
définir un constructeur pour la classe englobante dont le rôle est seulement
d'assurer la transmission des arguments aux classes membres.
!
Exemple 1
Dans la classe Interne, définir une fonction
constructeur ainsi qu'une fonction d'affichage, en ligne.
Dans la classe Externe, définir une donnée
membre locale et deux données imbriquées définies dans la classe Interne. Le
constructeur de la classe Externe devra, dans chacune des classes, appeler
celui de la classe Interne. La méthode afficher() sera définie.
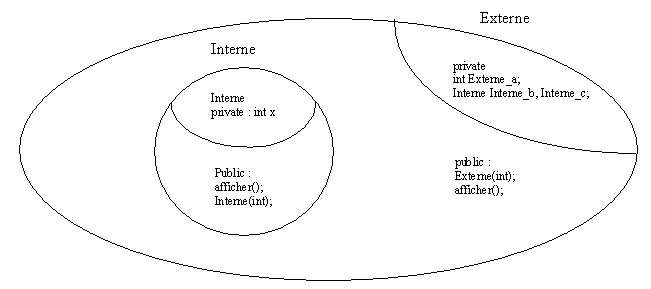
#include
<iostream.h>
class Interne
{int
x;
public:
Interne(int x) {Interne::x=x;} // classe Interne :
constructeur inline
void
afficher() {cout <<
"constructeur de la classe Interne = " << x << endl ;}
};
class Externe
{int
Externe_a;
// donnée membre définie dans la classe
Interne Interne_b, Interne_c; //
données membres imbriquées
public:
// prototypes
Externe(int); //
constructeur de la classe Externe
void
afficher();
};
// Le constructeur de la classe
Externe appelle celui de la classe Interne.
//
Interne_b, Interne_c initialisés par le constructeur Interne()
Externe::Externe(int
v) : Interne_b(10), Interne_c(v/2)
{Externe_a=v;}
//
initialisation de la donnée membre Externe_a.
void Externe::afficher()
{cout
<< "constructeur de la classe Externe = " << Externe_a
<<endl ;
Interne_b.afficher();
Interne_c.afficher();}
int
main()
{Externe
e(17); e.afficher();
Interne f(-10); f.afficher(); // transtypage fonctionnel
Externe g(28); g.afficher();
}
//
résultat
constructeur
de la classe Externe = 17
constructeur
de la classe Interne = 10
constructeur
de la classe Interne = 8
constructeur
de la classe Interne = -10
constructeur
de la classe Externe = 28
constructeur
de la classe Interne = 10
constructeur
de la classe Interne = 14
On considère des vecteurs et des matrices.
1°) Définir une classe complexe, un
constructeur de la classe et un opérateur surchargé de multiplication de nombres
complexes.
2°) Définir une classe matrice et une classe
vecteur dotées des constructeurs adéquats. Bien sûr, le constructeur de la
classe matrice appelle celui de la classe vecteur.
3°) Ecrire un opérateur surchargé de
multiplication qui permette :
a) de multiplier un vecteur par un scalaire
b) de multiplier deux vecteurs entre eux.
c) de multiplier une matrice par un scalaire.
d) de multiplier une matrice par un vecteur ou
un vecteur par une matrice.
e) de multiplier deux matrice s entre elles.
// Surcharge de l'opérateur * sur des complexes
après initialisation par différents constructeurs.
// Définition de 2 classes : 1 classe vecteur, 1
classe matrice, et
// la multiplication d'un vecteur par un nombre,
et d'un vecteur
// par un vecteur, la multiplication d'un
vecteur par une matrice,
// d'une matrice par un vecteur, et d'une
matrice par un nombre.
// Avec les constructeurs adéquats.
#include <iostream.h>
#define COLONNES 3
#define LIGNES 3
class Complexe
{public:
float
re; float im;
Complexe(float
x=0, float y=0)
{re=x;im=y;}
Complexe operator * (Complexe z)
{Complexe aux;
aux.re
= re*z.re - im*z.im;
aux.im
= re*z.im + im*z.re;
return
aux;
}
};
class Vecteur
{public:
float
*x;
unsigned int Taille;
Vecteur(){}
Vecteur(unsigned
int a)
{ if(a!=0)
{ x=
new float[a];
for(unsigned
int i=0;i<a;i++) *(x+i)=0;
Taille
= a;
}
else
cout << "Problème de taille (0 non permis)"<< endl;
}
Vecteur
operator * (float a)
{ Vecteur aux(Taille);
for(unsigned
int i=0;i<Taille;i++) aux.x[i]=a*x[i];
return
aux;
}
Vecteur
operator * (Vecteur A)
{ Vecteur aux(Taille);
for(unsigned
int i=0;i<Taille;i++) aux.x[i]=x[i]*(A.x[i]);
return
aux;
}
};
class Matrice:public Vecteur
{ public:
Vecteur
*M;
unsigned
int nbLignes;
unsigned
int nbCol;
Matrice(unsigned
int a,unsigned int b)
{ if ((a!=0) && (b!=0))
{M=new Vecteur[b]; for(unsigned int
i=0;i<b;i++) *(M+i)=Vecteur(a);}
else
cout << "Problème de taille" << endl;
nbLignes
= a;
nbCol
= b;
}
Matrice
operator * (Vecteur A)
{ Matrice aux(A.Taille,1);
if
(A.Taille == nbCol)
{ unsigned int i,j;
for (i=0;i<nbLignes;i++)
{float temp=0;
for (j=0;j<nbCol;j++)
temp+=M[j].x[i]*A.x[j];
aux.M[0].x[i]=temp;
}
return
aux;
}
else
{cout
<< "Multiplication impossible : taille incompatible !\n";
return aux;
}
}
};
int main()
{ int
i,j,l;
Complexe
z1(1,10);
Complexe
z2(5,-2), z;
cout
<< "z : " << z.re << " " << z.im
<< endl;
cout
<< "z1 : " << z1.re << " " << z1.im
<< endl;
cout
<< "z2 : " << z2.re << " " << z2.im
<< endl;
cout
<< "z1*z2 = " << (z1*z2).re << " "
<< (z1*z2).im << endl;
Vecteur
A(5);
for(i=0;
i<5;i++) A.x[i]=(float)i+1;
Vecteur
B(5);
for(j=0;
j<5;j++) B.x[j]=(float)10*j-2;
cout
<< "A" << "
B" << endl;
for(int
k=0;k<5;k++) cout << A.x[k] << " " << B.x[k] << endl;
cout
<< endl;
cout
<< "A*B" << endl;
for(l=0;l<5;l++)
cout << (A*B).x[l] << endl;
cout
<< endl;
cout
<< "10*A" <<
endl;
for(int
f=0;f<5;f++) cout << (A*10).x[f] << endl;
cout
<< endl;
Matrice
M(LIGNES,COLONNES);
//
L'écriture n'est pas intuitive puisque les lignes viennent APRES les
colonnes...
M.M[0].x[0]
= 2;
M.M[1].x[0]
= -2;
M.M[2].x[0]
= 8;
M.M[0].x[1]
= 1;
M.M[1].x[1]
= -15;
M.M[2].x[1]
= 24;
M.M[0].x[2]
= 10;
M.M[1].x[2]
= -5;
M.M[2].x[2]
= 1;
Vecteur
C(3);
for(i=0;
i<3;i++) C.x[i]=2+(float)i;
cout
<< "Matrice M:\n";
for(i=0;i<LIGNES;i++){for(j=0;j<COLONNES;j++)
cout << (M.M[j]).x[i] << " "; cout << endl;}
cout
<< endl;
cout
<< "Vecteur C :" << endl;
for(l=0;l<3;l++)
cout << C.x[l] << endl;
cout
<< endl;
cout
<< "M*C = \n";
for(i=0;i<LIGNES;i++)
{cout
<< ((M*C).M[0]).x[i]; cout
<< endl; }
return
1;}
·
L'héritage permet de transmettre à une classe, appelée classe fille, classe
dérivée ou classe descendante, des caractéristiques d'une
ou de plusieurs autres classes, appelées classes mères, classes
de base ou classes antécédentes. Il
représente une relation d'inclusion
entre classes.
·
Une classe dérivée hérite de certains champs et méthodes de sa classe de base selon
les qualifications d'accès aux objets et la qualification de l’héritage.
·
Une classe de base unique définit un héritage
simple dont
le graphe, représentant la hiérarchie de classes, est un arbre.
·
Plusieurs classes de base définissent un héritage
multiple dont la
représentation est un graphe sans cycle.
En langage C++,
la définition de la classe fille est constituée par la liste de(s) la(es) classe(s) mère(s) avec leur qualification d'héritage respectives
selon la syntaxe (identique avec les mots clés struct et union)
suivante :
Þ Syntaxe
Classe_dérivée : [qualification_de_l’héritage]
classe(s)_de_base {définition de la classe dérivée}
!
Exemple
class Classe_mere1 {/* Contenu de la classe mère 1 */ };
[class Classe_mere2 {/* Contenu de la
classe mère 2 */ };]
[…]
class Classe_fille : public|protected|private Classe_mere1
[,
public|protected|private Classe_mere2 […]]
{/* Définition
de la classe fille */};
La Classe_fille
hérite de la Classe_mere1, et des Classe_mere2, etc… si elles sont définies.
!
Exercice
Définir
a) Une classe de base avec deux données
publiques B_a, B_b, et une méthode publique d'addition
int B_plus(int,int);
b) une classe dérivée qui hérite des
données et méthodes de la classe de base pour définir un champ D_c entier, une
méthode D_plus qui additionne le champ D_c aux champs B_a et B_b par appel de
la méthode B_plus().
c) une fonction f, externe aux classes de
base et dérivée qui appelle les méthodes B_plus() et D_plus().
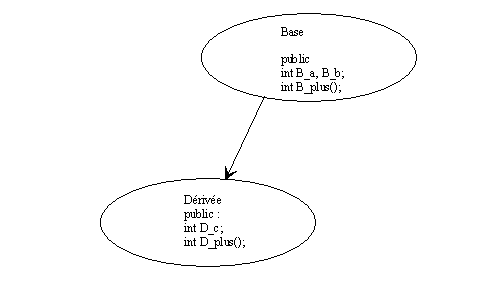
#include
<iostream.h>
class Base {
public:
int
B_a, B_b;
int
B_plus() {return B_a+B_b;}
}; //
Fin classe de base
class Derivee : public Base // héritage qualifié public
{public:
int
D_c;
int
D_plus() {return D_c+B_plus();}
}; // Fin classe Dérivée
int
f()
{Derivee
d;
// Initialisation
d.B_a=d.B_b=d.D_c=2;
//
accès aux méthodes dérivée et de base
return
d.D_plus()*d.B_plus();
}
int
main()
{cout
<< "f=" << f() << endl ;
}
//
résultat
f()=24
Une classe dérivée peut redéfinir certaines
méthodes de la classe de base comme l'illustre l'exemple ci‑dessous.
!
Exemple
#include <iostream.h>
class Base
{public:
int
B_a, B_b;
int
plus() {return B_a+B_b;}
};
class Derivee : public Base
{public:
int
D_a;
int
plus(Base B_z) {return D_a+B_z.plus();}
};
// int plus() {return a+plus();} provoquerait une récursivité infinie.
int main()
{int plus(Base); //
prototype classe dérivée
int
plus(); // prototype
classe de base
Base
B_x;
B_x.B_a=2; B_x.B_b = 3;
cout <<
"B_x.plus =" << B_x.plus() << endl ;
Derivee
D_y;
D_y.D_a
=15;
cout
<< "D_y.plus=" << D_y.plus(B_x) << endl ;
return
1;
}
// résultat
B_x.plus =5
D_y.plus=20
·
Les droits d'accès aux membres d'une
classe sont spécifiés par trois qualifications
d'accès :
à
Les objets d'accès public, qualifiés public,
sont accessibles à tous.
à
Les objets d'accès privé, qualifiés private, sont réservés exclusivement au
développeur de la classe, inaccessibles aux utilisateurs de la classe et aux
développeurs de classe dérivées.
à
Les objets d'accès protégé, qualifiés
protected, sont réservés aux développeurs
de la classe mère et des classes dérivées, inaccessibles aux utilisateurs.
·
Les différentes définitions peuvent être
morcelées et désordonnées.
·
La qualification
de l’héritage affine ces
propriétés pour les objets dérivés des classes filles.
Þ Définition
L'héritage de la classe de base peut être qualifié public, private ou protected pour définir dans la(es) classe(s) dérivée(s)
les règles d'accès des objets de la classe de base.
Þ Synopsis
class B {...}; //
classe de base
class Dl : public
B {...}; // héritage qualifié public
class D2 : private
B {...}; // héritage qualifié privé
class D3 : protected
B {...}; // héritage qualifié protégé
class D4 : B
{...}; //
héritage qualifié private par défaut
struct D5 : B {...}; //
héritage qualifié public par défaut
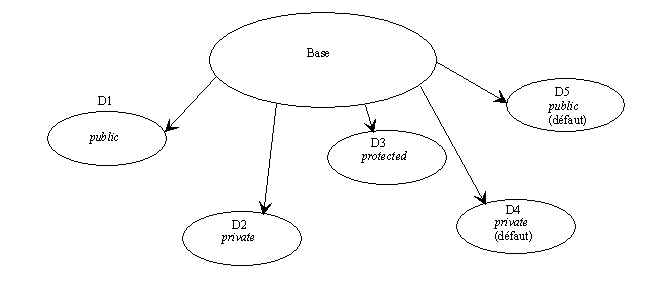
Þ Héritage qualifié public
·
Les objets qualifiés protected et public dans
la classe de base le sont également dans la classe dérivée.
·
Les objets qualifiés private de la classe de base sont inaccessibles dans la classe dérivée.
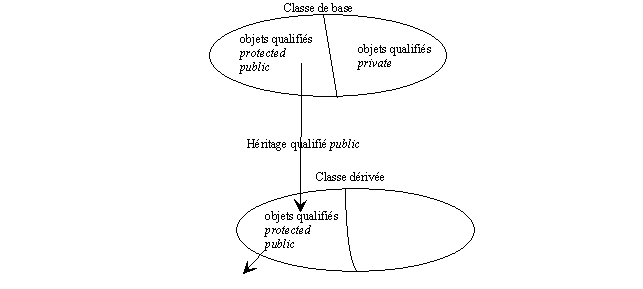
Þ Héritage qualifié private
·
Les objets qualifiés protected et public dans
la classe de base sont qualifiés private
dans la classe dérivée. Seuls les membres
et les fonctions amies de la classe dérivée y ont accès.
·
Les objets qualifiés private de la classe de base sont inaccessibles dans la classe dérivée.
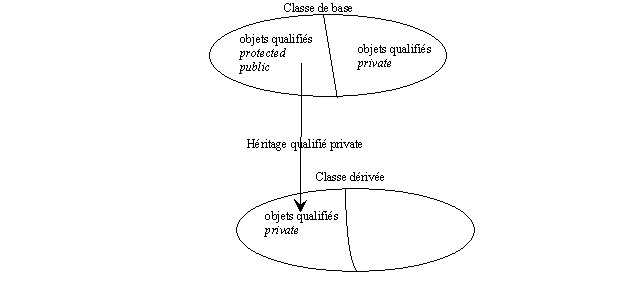
Þ Héritage qualifié protected
·
Les objets qualifiés protected ou public dans
la classe de base sont qualifiés protected
dans la classe dérivée.
·
Les objets qualifiés private de la classe de base sont inaccessibles dans la classe dérivée.
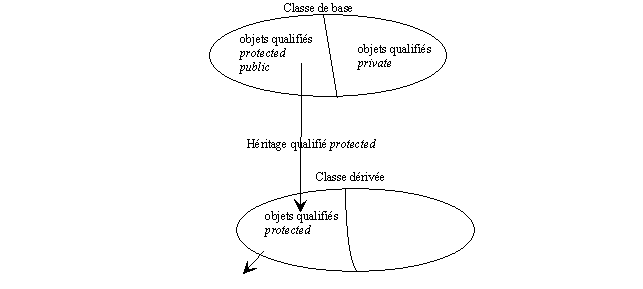
|
accès aux données
(classe mère)
|
accès aux données dans la classe fille selon la
qualification de l'héritage
public
protected private
|
|
|
public
|
public
|
protected
|
private
|
|
|
protected
|
protected
|
protected
|
private
|
|
|
private
|
interdit
|
interdit
|
interdit
|
Tableau récapitulatif des qualifications d'accès
des membres hérités
Þ Sémantique associée
·
La composition
d'une classe implante le concept HAS_A.
·
L'héritage qualifié public implante le concept IS_A.
·
L'héritage qualifié private implante le concept IS_A_KlND_OF.
·
L'héritage qualifié protected permet la transmission des qualifications d'accès des
membres de la classe de base dans les classes dérivées d'ordre deux ou plus.
Quand
l'héritage est qualifié public, toute instance d'une
classe dérivée peut être considérée
comme une instance de la classe de base.
Deux conséquences immédiates :
·
elle est constituée des mêmes champs
d'accès public au moins.
·
La construction d'une instance de la
classe dérivée nécessite celle d'une instance de la classe de base donc l'appel
d'un de ses constructeurs accessibles.
!
Exemple
class Base
{int
Base_a;
public:
Base():Base_a(0)
{...} // constructeur par
défaut
Base
(int A): Base_a(A) {...} //
autre constructeur
};
class Derivee : public Base
{int
Derivee_b;
public:
Derivee() :
Derivee_b(0) {...} // 2
constructeurs de la classe dérivée
Derivee(int i, int
j): Base(i), Derivee_b(j) {...}
// la partie héritée
est anonyme. On utilise donc son nom de type pour l'adresser.
};
Þ Héritage qualifié public
·
La classe dérivée peut être considérée comme sa classe de base si et seulement si l'héritage est qualifié public.
·
Toutes les propriétés des objets accessibles de la classe de base s'appliquent aux objets qui en
sont dérivés dans la classe fille.
!
Corollaire
Quand l'héritage de la classe de base est
qualifiée public, il est licite
d'effectuer un transtypage implicite d'un objet de la classe dérivée vers la classe de base.
Þ Héritage qualifié privé ou protégé
·
Quand l'héritage est qualifié private ou protected, la classe dérivée peut être considérée comme
"presque pareille mais pas tout à fait identique à sa classe de
base".
·
Toutes les propriétés des objets de la
classe de base pouvant ne pas s'appliquer à ceux de la classe dérivée, un
transtypage implicite de la classe
dérivée vers la classe de base ou réciproquement est interdit.
Þ Position du problème
Quand l’héritage de la classe de base est
qualifié private ou protected, le développeur de la classe
dérivée peut souhaiter rendre public
certaines données membres dérivées de la classe de base. Deux solutions :
·
redéfinir une fonction similaire dans la
classe dérivée appelant la méthode correspondante de la classe de base voulue,
·
requalifier l'accès aux objets concernés.
!
Exemple
class list {
// ...
public: void add(int);
void remove(int);
void print();
};
class linkedlist : private list { //
héritage qualifié privé
protected: list::remove; // la méthode (private) remove requalifiée protected
public: list::add; //
la méthode (private) add requalifiée public
}; //
la méthode print reste qualifiée private

Þ Limites à la requalification des qualifications d'accès
La requalification des qualifications d'accès ne peut pas
être utilisé pour :
·
élargir les droits définis dans la classe
de base : private vers protected ou protected vers public,
·
restreindre les droits définis dans la
classe de base en cas de dérivation public.
Þ Conclusion
·
La requalification
des droits permet de modifier les qualifications d'accès de certains
membres des effets d'une dérivation qualifiée private ou protected.
·
La dispense ne porte que sur
l'identificateur.
·
Il est interdit de requalifier les
fonctions et opérateurs surchargés.
!
Exercices : analyser les
programmes suivants
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
const int NbMaxCarac = 25;
class Produit {// version simplifiée pour l'introduction de l'héritage
private:
char nom[NbMaxCarac+1];
float
prix;
void fixeNom (const char * Texte);
public:
Produit
(char * Nom, float Prix) //
constructeur de la classe Produit
{fixeNom(Nom); prix = Prix;}
void AfficheToi()
{cout
<< "Produit " <<
nom <<"\tprix: "
<< prix << endl;}
}; // fin de la définition de la classe Produit
void Produit::fixeNom (const char
* Texte)
{strncpy (nom, Texte, NbMaxCarac);
nom[NbMaxCarac] = '\0';
} // void
fixeNom (const char * Texte)
class ProduitPerissable : public Produit
{private: int nombreDeJours; //
durée de conservation
public:
ProduitPerissable (char * Nom, int Duree, float Prix) : Produit
(Nom, Prix)
// Le constructeur de la classe
ProduitPerissable dérive de celui de la classe Produit
// pour les champs Nom, Prix
{nombreDeJours = Duree;}
}; // fin de la définition de la classe
ProduitPerissable
int main()
{ Produit
P1("SAVON",7.5);
P1.AfficheToi();
ProduitPerissable
P2("YAOURT", 15, 12.5);
P2.AfficheToi(); // P2 est affiché comme un Produit
return
1;
} // fin de main
// résultat
Produit SAVON prix:
7.5
Produit YAOURT prix:
12.5
!
Exercice 2
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
const int NbMaxCarac = 25;
// Dans cet exemple, la classe dérivée redéfinit
la fonction membre AfficheToi
class Produit {// version simplifiée pour l'introduction de l'héritage
private:
char nom[NbMaxCarac+1];
float
prix;
void fixeNom (const char * Texte);
public:
Produit
(char * Nom, float Prix)
{fixeNom(Nom); prix = Prix;}
void AfficheToi()
{cout
<< "Produit " <<
nom <<"\tprix: "
<< prix << endl;}
}; // fin de la définition de la classe Produit
void Produit::fixeNom (const char
* Texte)
{strncpy (nom, Texte, NbMaxCarac);
nom[NbMaxCarac] = '\0';
}
class ProduitPerissable : public Produit {
private:
int
nombreDeJours; // durée de conservation
public:
ProduitPerissable
(char * Nom, int Duree, float Prix): Produit (Nom, Prix)
{nombreDeJours
= Duree;}
void AfficheToi()
{//
on redéfinit la fonction membre AfficheToi
Produit::AfficheToi();
// la fonction membre de la classe de base reste utilisable
cout
<< "\tvalidité: " << nombreDeJours << " jours" << endl ;
}
}; // fin de la définition de la classe
ProduitPerissable
int main()
{ Produit
P1("SAVON",7.5);
P1.AfficheToi();
ProduitPerissable
P2("YAOURT", 15, 12.5);
P2.AfficheToi(); // P2 a un comportement
d'affichage propre à sa classe
P2.Produit::AfficheToi(); // P2 peut toujours avoir un
comportement de Produit
return
1;
} // fin de main
// résultat
Produit SAVON prix:
7.5
Produit YAOURT prix:
12.5
validité:
15 jours
Produit YAOURT prix:
12.5
!
Exercice 3
// Dans cet exemple, la classe dérivée redéfinit
la fonction membre AfficheToi
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
const int NbMaxCarac = 25;
class Produit { // version simplifiée
pour l'introduction de l'héritage
protected:
char nom[NbMaxCarac+1];
float
prix;
void fixeNom (const char * Texte);
public:
Produit
(char * Nom, float Prix)
{fixeNom(Nom); prix = Prix;}
void AfficheToi()
{cout
<< "Produit " <<
nom <<"\tprix: "
<< prix << endl;}
}; // fin de la définition de la classe Produit
void Produit::fixeNom (const char
* Texte)
{strncpy (nom, Texte, NbMaxCarac);
nom[NbMaxCarac] = '\0';
}
class ProduitPerissable : private Produit {
private:
int nombreDeJours; // durée de
conservation
public:
ProduitPerissable (char * Nom, int Duree, float
Prix) : Produit (Nom, Prix)
{nombreDeJours = Duree;}
void AfficheToi() //
redéfinition de la fonction membre AfficheToi
{Produit::AfficheToi(); // la fonction membre de la classe de base
reste utilisable
cout << "\tvalidité: "
<< nombreDeJours << "
jours" << endl ;
}
void PrixEtDuree()
{cout << prix <<"F, "
<< nombreDeJours <<
" jours" << endl ;}
}; // fin de la définition de la classe
ProduitPerissable
int main()
{Produit P1("SAVON",7.5);
P1.AfficheToi();
ProduitPerissable P2("YAOURT", 15,
12.5);
P2.AfficheToi(); //
P2 a un comportement d'affichage propre à sa classe
P2.PrixEtDuree();
return
1;
} // fin de main
// résultat
Produit SAVON prix:
7.5
Produit YAOURT prix:
12.5
validité:
15 jours
12.5F, 15 jours
Þ
Exercice 4
#include <iostream.h>
class mere1
{int m1;
public:
mere1(){}
mere1(int i) {cout << "constructeur
mère 1 "<< endl; m1=i;}
void affiche() {cout<< "m1="
<< m1 << endl;}
};
class mere2
{int m2;
public:
mere2(){}
mere2(int i2) {m2=i2;}
void affiche() {cout<< "m2="
<< m2<< endl;}
};
class fille :
mere1, mere2
{public :
fille(){}
fille(int i1,int i2): mere1(i1),mere2(i2) {cout
<< "constructeur fille" << endl;}
void affiche() {mere1::affiche();
mere2::affiche();}
};
class petitefille : fille
{public:
petitefille(int i1,int i2): fille (i1,i2) {cout << "constructeur
petitefille" << endl;}
public :
fille::affiche;
};
int main()
{fille f(2,3);
f.affiche();
petitefille pf(4,5) ;
pf.affiche();
}
// résultat
constructeur mère 1
constructeur fille
m1=2
m2=3
constructeur mère 1
constructeur fille
constructeur petitefille
m1=4
m2=5
Þ
Ordre
d'exécution des constructeurs
·
Les instances des classes dérivées ne
peuvent être initialisées sans appel préalable
des constructeurs des classes de base. Il faut donc toujours appeler, de
préférence explicitement, le
constructeur de la classe de base avant celui de la classe dérivée en cours
d'instanciation. En cas d'appel implicite, l'ordre d'appel des constructeurs de
la classe de base est le suivant :
à
constructeur implémenté,
à
constructeur par défaut explicite,
à
constructeur par défaut implicite.
Syntaxe
L'opérateur de résolution de visibilité sépare, de
la gauche vers la droite, le constructeur de la classe fille de celui la classe
mère.
Classe_fille::Classe_fille:Classe_mere(arguments_constructeur_classe_fille)
!
Exemple
#include
<iostream.h>
class Mere
{int m_i;
public:
Mere(int); //Constructeur
~Mere(void); //Destructeur
};
Mere::Mere(int i)
{m_i=i;
cout << "Constructeur de la
classe mère : m_i = " << m_i<< endl;
return;
}
Mere::~Mere(void)
{cout <<
"Destructeur de la classe mère" << endl;
return;
}
class Fille : public Mere
{public:
Fille(void);
~Fille(void);
};
// Le constructeur
de la classe fille avec appel du constructeur de la classe mère
Fille::Fille(void) : Mere(2)
{cout <<
"Constructeur de la classe fille" << endl ;
return;
}
// Le destructeur
de la classe fille appelle celui de la classe mère
Fille::~Fille(void)
{cout <<
"Destructeur de la classe fille " << endl;
return;
}
int main()
{Mere A(1);
Fille B;
Mere C(5);
}
// Résultat
Constructeur de la
classe mère : m_i = 1
Constructeur de la
classe mère : m_i = 2
Constructeur de la
classe fille
Constructeur de la
classe mère : m_i = 5
Destructeur de la
classe mère
Destructeur de la
classe fille
Destructeur de la
classe mère
Destructeur de la
classe mère
Þ
Position du
problème
Soit la classe D
héritant de deux classes mères B et C, filles d'une classe mère commune A selon
l'arbre "généalogique" suivant :

Selon les
qualifications des héritages, les classes B et C peuvent hériter des données et
des méthodes publiques et protégées de A, la classe D peut hériter
des données de B et C, donc par transitivité des données héritables de A, l'héritage
étant implémenté par aggrégat de(s)
la structure(s) de données de(s) la classe(s) de base dans celle de la classe
dérivée.
Se pose alors le
problème suivant : dans la classe D, les données utilisées quand les
champs de A sont référencés sont‑elles héritées de B ou de C ?
Le chemin dans la hiérarchie de classe peut être spécifié par l'opérateur de
résolution de portée ce qui n'est ni pratique ni toujours efficace.
Þ
Définition
Le problème est
résolu en déclarant virtuelle la classe de base commune
dans la définition de l'héritage des classes filles avec l'effet
suivant : le compilateur garantissant l'unicité des données
héritées que l'héritage soit simple
ou multiple, les données membres de
la classe de base virtuelle ne
peuvent pas être dupliquées dans les classes dérivées à partir du deuxième
ordre.
Syntaxe
L'identificateur
de la classe mère est précédé du qualificateur virtual dans la définition des classes filles.
!
Exemple
class A
{protected:
int Donnee; // La donnée de la classe de base
};
class B : virtual public A //
Héritage de la classe virtuelle A
{protected:
int Valeur_B;
};
class C : virtual public A // A
est toujours virtuelle
{protected:
int valeur_C; // nouveau champ, Donnee est acquise par héritage.
};
class D : public B, public C // le
champ Donnee est garanti unique.
{}; // La classe D
!
Exercice : analyser le
programme suivant
#include <iostream.h>
class mere1
{int m1;
public:
mere1(){}
mere1(int i) {cout << "constructeur
mère 1 "<< endl; m1=i;}
void affiche() {cout<< "m1="
<< m1 << endl;}
};
class mere2
{int m2;
public:
mere2(){}
mere2(int i) {cout << "constructeur
mère 2 "<< endl; m2=i;}
void affiche() {cout<< "m2="
<< m2<< endl;}
};
class fille1 :
virtual mere1, virtual mere2
{public :
fille1(){}
fille1(int i1,int i2): mere1(i1),mere2(i2) {cout
<< "constructeur fille1" << endl;}
void affiche() {mere1::affiche();
mere2::affiche();}
};
class fille2 :
virtual mere1, virtual mere2
{public :
fille2(){}
fille2(int i1,int i2): mere1(i1),mere2(i2) {cout
<< "constructeur fille2" << endl;}
void affiche() {mere1::affiche();
mere2::affiche();}
};
class petitefille : fille1,fille2
{public:
petitefille(int i1,int i2): mere1(i1),mere2(i2),fille1(i1,i2)
,fille2(i1,i2)
{cout
<< "constructeur petitefille" << endl;}
void
affiche() {fille1::affiche();}
};
int main()
{petitefille pf(4,5) ;
pf.affiche();
}
// résultat
constructeur mère 1
constructeur mère 2
constructeur fille1
constructeur fille2
constructeur petitefille
m1=4
m2=5
!
Exercice : analyser le
programme suivant. Différences avec le précédent
#include <iostream.h>
class mere1
{int m1;
public:
mere1(){}
mere1(int i) {cout << "constructeur
mère 1 "<< endl; m1=i;}
void affiche() {cout<< "m1="
<< m1 << endl;}
};
class mere2
{int m2;
public:
mere2(){}
mere2(int i2) {cout << "constructeur
mère 2 "<< endl; m2=i2;}
void affiche() {cout<< "m2="
<< m2<< endl;}
};
class fille1 :
mere1, mere2
{public :
fille1(){}
fille1(int i1,int i2): mere1(i1),mere2(i2) {cout
<< "constructeur fille1" << endl;}
void affiche() {mere1::affiche();
mere2::affiche();}
};
class fille2 :
virtual mere1, virtual mere2
{public :
fille2(){}
fille2(int i1,int i2): mere1(i1),mere2(i2) {cout
<< "constructeur fille2" << endl;}
void affiche() {mere1::affiche();
mere2::affiche();}
};
class petitefille : fille1,fille2
{public:
petitefille(int i1,int i2): fille1(i1,i2) ,fille2(i1,i2) {cout
<< "constructeur petitefille" << endl;}
void
affiche() {fille1::affiche();}
};
int main()
{petitefille pf(4,5) ;
pf.affiche();
}
// résultat
constructeur mère 1
constructeur mère 2
constructeur fille1
constructeur fille2
constructeur petitefille
m1=4
m2=5
·
L'utilisation
de l'opérateur de transtypage dynamique
dynamic_cast est impérative pour transtyper
un pointeur sur un objet d'une classe de
base virtuelle en un pointeur sur un objet d'une de ses classes dérivées.
·
Les classes
dérivées au deuxième ordre ou plus, pouvant dériver d'une même classe
virtuelle, ne peuvent pas utiliser leur(s) classe(s) mère pour appeler le
constructeur de la classe virtuelle, ce dernier pouvant être appelé plusieurs
fois. Chaque classe dérivée prend donc en charge la
construction des objets des classes
virtuelles dont elle hérite.
·
Un constructeur d'une classe de base
virtuelle
doit être appelés explicitement par
toute classe dérivée quel que soit son ordre, les données de la classe de base
virtuelle y étant garanties uniques.
·
Le constructeur de toute classe dérivée
d'une classe virtuelle, quel que soit son ordre, doit en appeler explicitement le constructeur pour
éviter l'appel du constructeur par défaut
même si un constructeur spécifique est défini dans une autre classe mère
dérivée de la classe de base virtuelle, chacune des classes mère pouvant
initialiser un objet commun hérité de la classe virtuelle. Dans l'exemple ci‑dessus,
si les classes B et C appellent toutes deux le constructeur de la classe
virtuelle A, et que la classe D utilise les constructeurs de B et C, l'objet
hérité de A est construit plusieurs fois. Pour
l'éviter, le compilateur ignore purement et simplement les appels implicites au
constructeur des classes de bases
virtuelles dans les classes de base
dérivées qui doivent donc être systématiquement spécifié, à chaque niveau de la
hiérarchie des classes.
Sur le plan
sémantique, les méthodes virtuelles n'ont
rien à voir avec les classes virtuelles, bien qu'elles utilisent le même
mot-clé virtual.
Þ
Position du
problème
Par défaut,
l'appel d'une méthode est celui la dernière fonction définie dans la hiérarchie des classes. L'appel d'une
méthode redéfinie de niveau supérieur nécessite donc de rappeler le nom de sa
classe avec l'opérateur de résolution de
portée.
Bien que simple,
l'usage de cette règle pose des problèmes. Soit une classe B héritant de la
classe mère A dont la méthode [A::]x appelle la méthode y redéfinie dans sa
classe fille B. Que se passe-t-il lorsqu'un objet de la classe B invoque la
méthode [A::]x ? La méthode appelée étant membre de la classe A appellera
la méthode A::y. Ainsi, la redéfinition de y est inopérante si l'appel s'effectue à partir d'une méthode d'une
classe mère.
Une première
possibilité (inefficace) consiste à redéfinir la méthode x dans la classe
dérivée B.
Þ
Lien
dynamique
La solution est
de forcer le compilateur à ne pas faire de lien systématique entre les méthodes
A::x et A::y. La méthode x doit appeler la méthode A::y quand elle est invoquée
pour un objet de la classe A, la méthode B::y quand elle est invoquée pour un
objet de la classe B, le lien devant être effectué à l'exécution (lien dynamique).
Syntaxe
Il suffit de
déclarer par le mot-clé virtual dans
la classe de base la méthode redéfinie dans la classe fille.
Þ Conclusions
·
Une méthode virtuelle est appelée selon la
classe effective de l'objet qui l'invoque : classe
de base ou classe dérivée, tout en garantissant l'exécution des opérations
adéquates selon sa classe d'appartenance.
·
Un tel
comportement est appelé polymorphisme (l'objet peut avoir plusieurs aspects différents).
·
Une autre
application du polymorphisme est celle des pointeurs
sur les objets.
!
Exemple : surcharge de méthode
dans la classe de base
Analyser le programme suivant.
#include <iostream.h>
class DonneeBase
{protected:
int Numero; //
Les données sont numérotées.
int Valeur; //
et sont constituées d'une valeur entière
public:
virtual void
Entre(void); // méthode de saisie
void
MiseAJour(void); //
méthode de mise à jour
};
void
DonneeBase::Entre(void)
{cout <<
"Numéro : ";
cin >> Numero;
cout << "Numéro : "<<
Numero << endl;
cout << "Valeur : " ;
cin >> Valeur;
cout << "Valeur : "
<< Valeur << endl;
return;
}
void DonneeBase::MiseAJour(void)
{Entre(); return;}
class DonneeDetaillee : public DonneeBase
{int
ValeurEtendue; // Les données
détaillées ont en plus une valeur étendue.
public:
void
Entre(void); // Redéfinition de la méthode de saisie
};
void DonneeDetaillee::Entre(void)
{DonneeBase::Entre(); // Appelle la méthode de base.
cout << "Valeur étendue :
";
cin >> ValeurEtendue; // Entre la valeur étendue.
cout << "Valeur étendue : "
<< ValeurEtendue << endl;
return;
}
int main(void)
{DonneeBase A;
A.Entre();
A.MiseAJour();
DonneeDetaillee B;
B.Entre();
B.MiseAJour();
}
// résultat
Numéro : 5
Numéro : 5
Valeur : 8
Valeur : 8
Numéro : 6
Numéro : 6
Valeur : 2
Valeur : 2
Numéro : 5
Numéro : 5
Valeur : 5
Valeur : 5
Valeur étendue : 6
Valeur étendue : 6
Numéro : 6
Numéro : 6
Valeur : 5
Valeur : 5
Valeur étendue : 6
Valeur étendue : 6
Þ
Remarques
·
L'appel
B.Entre est correct quand B est une instance de la classe DonneeDetaillee.
·
L'appel
B.MiseAJour est faux si la fonction Entre n'est pas déclarée comme une fonction
virtuelle dans la classe de base.
11.8
Règles de dérivation
Les règles générales de dérivation des
objets sont les suivantes :
Þ
Règle 1
Un objet d'une
classe dérivée est utilisable dans toutes les situations où un objet d'une de
ses classes mère l'est. Bien entendu, il faut disposer des qualifications
d'accès sur les membres de la classe de base utilisés.
Þ
Règle
2 : affectation d'instances entre classes fille et mère
·
Une
affectation d'une instance d'une classe dérivée à une instance d'une classe
mère est autorisée les données des champs non définis dans la classe mère étant
perdues.
·
L'inverse
est interdit les données de la classe fille qui n'existent pas dans la classe
mère ne pouvant être ni initialisées ni affectées.
Þ
Règle
3 : affectation de pointeur
·
Les
pointeurs des classes dérivées sont compatibles avec ceux des classes
mères : un pointeur de classe dérivée peut être affecté à un pointeur
d'une de ses classes de base à condition d'être doté des qualifications d'accès
convenables.
·
Un objet
dérivé, pointé par un pointeur d'une de ses classes mères, est considéré comme
un de ses objets. Les données spécifiques à sa classe deviennent momentanément
inaccessibles mais le mécanisme des méthodes virtuelles continue de
fonctionner, le destructeur de la classe de base devant être déclaré virtuel pour garantir l'appel du
destructeur adéquat.
·
Un pointeur
de classe de base peut être converti en un pointeur de classe dérivée même si
la classe de base n'est pas qualifiée virtuelle ce qui est dangereux la classe
dérivée pouvant avoir des membres non définis dans la classe de base. Un transtypage fonctionnel est donc
nécessaire dans ce type de conversion.
!
Exemple
#include
<iostream.h>
class Mere
{public:
Mere(void);
~Mere(void);
};
Mere::Mere(void)
{cout <<
"Constructeur de la classe mère" << endl; return;}
Mere::~Mere(void)
{cout <<
"Destructeur de la classe mère" << endl; return;}
class Fille : public Mere
{public:
Fille(void);
~Fille(void);
};
Fille::Fille(void) : Mere()
{cout <<
"Constructeur de la classe fille" << endl; return;}
Fille::~Fille(void)
{cout <<
"Destructeur de la classe fille" << endl; return;}
Avec ces
définitions, seule la première des deux affectations suivantes est autorisée :
int main()
{Mere m; // Instanciation de deux objets.
Fille f;
m=f;
// f=m; // ERREUR !! (ne compile pas).
}
Les mêmes règles
sont applicables pour les pointeurs.
Mere *pm, m;
Fille *pf, f;
pf=&f; //
Autorisé.
pm=pf; //
Autorisé. Les données et les méthodes de la classe fille ne sont plus
accessibles
//
avec ce pointeur : *pm est un objet de la classe mère.
// pf=&m; //
ILLÉGAL : un transtypage est nécessaire
pf=(Fille *) &m; //
légal, mais DANGEREUX car les méthodes
de la classe filles ne sont pas définies
Þ Règle 4 : non transitivité de
l'amitié par dérivation
Par défaut, les
relations d'amitié ne sont pas héritées. Ainsi, soient une classe A amie d'une
classe B et une classe C fille de la classe B. La classe A n'est pas amie de la
classe C sauf déclaration explicite.
Cette règle
s'applique également aux fonctions et
méthodes amies.
Þ
Règle
5 : méthode virtuelle et constructeur
·
Comme
pendant l'exécution des constructeurs des classes de base, une méthode
virtuelle pourrait utiliser une donnée sur l'objet de la classe dérivée en
cours d'instanciation (non encore initialisé), le mécanisme des méthodes
virtuelles est désactivé dans la
phase de construction pour l'éviter.
·
Une méthode
virtuelle peut être appelée par un constructeur, la méthode effectivement
appelée étant celle de la classe de l'instance en cours de construction. Ainsi,
une classe (petite) fille A héritant d'une classe mère B définissant toutes
deux une méthode f dérivée d'une même méthode virtuelle, son appel par le
constructeur de B utilise B::f, même si l'objet instancié est membre de la
classe A.
Þ
Règle
6 : méthode virtuelle et destructeur
·
L'opérateur
(statique) delete recherchant le
destructeur adéquat dans la classe la plus dérivée, il est fondamental de le
déclarer virtuel.
·
Invoqué
dans une classe dérivée, il restitue la mémoire de l'objet complet.
·
Il est
inutile de préciser la classe du destructeur celui-ci étant unique.
!
Exemple
Dans le programme
précédent, l'utilisation d'un pointeur de la classe de base pour accéder à une
classe dérivée nécessite d'utiliser des méthodes virtuelles, en particulier les destructeurs. Avec la définition
donnée ci-dessus pour les deux classes, le code suivant est faux :
Mere *pm;
Fille *pf = new Fille;
pm = pf;
delete pm; // Appel du destructeur
de la classe mère
Pour résoudre le
problème, le destructeur de la classe mère doit être déclaré virtuel :
class Mere
{public:
Mere(void);
virtual ~Mere(void);
};
11.9
Méthodes virtuelles pures - classes abstraites
·
Une méthode virtuelle pure (pure virtual method) est déclarée
dans sa classe mère, définie dans une
classe dérivée.
·
Une classe abstraite comporte
au moins une méthode virtuelle pure.
Þ
Corollaires
·
Les
méthodes d'une classe abstraite sont accessibles avec des pointeurs.
·
L'utilisation
des méthodes virtuelles pures et des
classes abstraites permet de créer
des classes de base décrivant toutes les caractéristiques d'un ensemble de
classes dérivées dont les instances sont accessibles avec les pointeurs de la classe
de base.
·
Les
méthodes des classes dérivées sont déclarées virtuelles dans la classe de base,
leur accès étant réalisé par un pointeur
de cette dernière, la méthode effective
appelée étant définie dans la classe dérivée.
Syntaxe
Une méthode virtuelle pure dans une classe
voit suivre sa déclaration de « =0 », la méthode étant déclarée virtuelle.
!
Exemple 1
virtual type_resultat
identificateur_méthode_virtuelle_pure (liste_arguments_typés) =0;
// il n'y a pas
d'instance de cette méthode dans cette classe.
Þ
Remarque
L'affectation
nulle doit figurer en fin de déclaration, après le mot-clé const pour les méthodes const
et après la déclaration de la liste des exceptions autorisées.
On appelle conteneur une structure de données pouvant en contenir d'autres, quel que
soit leur type.
!
Exemple : conteneur d'objets
polymorphiques
·
Un sac est un conteneur pouvant contenir
plusieurs objets, non forcément uniques. Un objet peut donc être placé
plusieurs fois dans le sac.
·
On définit
deux fonctions permettant respectivement de mettre et de retirer un objet d'un
sac ainsi qu'une fonction permettant de détecter la présence d'un objet dans le
sac.
·
Une classe
abstraite est la classe mère de tous les objets utilisables.
·
Le
conteneur n'utilise que des pointeurs sur la classe abstraite ce qui permet son
utilisation dans toutes les classes dérivées. Deux objets identiques sont
différenciés par un numéro unique dont le choix est à leur charge. La classe
abstraite dont ils dérivent est donc dotée d'une méthode le retournant.
·
Les objets
sont affichés dans un format spécifique par la fonction print, méthode virtuelle pure de la classe abstraite.
#include <iostream.h>
/*************
LA CLASSE ABSTRAITE DE BASE
*****************/
class Object
{unsigned long int h; // Handle de l'objet.
unsigned long int new_handle(void);
public:
Object(void); // Le constructeur
virtual
~Object(void); // Le destructeur virtuel
virtual
void print(void) =0; // méthode virtuelle pure
unsigned long int handle(void) const; //
Fonction retournant le numéro d'identification de l'objet
};
// Cette fonction n'est appelable que par la
classe Object :
unsigned long int Object::new_handle(void)
{static unsigned long int hc = 0;
hc++;
return hc; //
hc handle courant, incrémenté à chaque appel de
//
new_handle
}
// Le constructeur de la classe Object doit être
appelé par les classes dérivées
Object::Object(void)
{h = new_handle(); //
allocation d'un nouveau handle.
}
Object::~Object(void)
{}
unsigned long int Object::handle(void) const
{return h;} //
Retourne le numéro de l'objet.
/******************** LA CLASSE SAC ******************/
class Bag : public
Object //
La classe sac hérite de la classe Object,
//
car un sac peut en contenir un autre. Le sac
//
est implémenté sous la forme d'une liste chaînée
{typedef struct baglist
{baglist *next;
Object *ptr;
}BagList;
BagList *head; // La tête de liste.
public:
Bag(void); //
constructeur
~Bag(void); //
destructeur
void print(void); //
fonction d'affichage du contenu du sac.
bool has(unsigned long int) const; // booléen vrai
si le sac contient l'objet.
bool is_empty(void) const; //
booléen vrai si le sac est vide.
void add(Object &); //
ajout d'un objet dans le sac
void remove(Object &); //
retrait d'un objet du sac
Bag
(const Bag &Source){}
Bag
& operator = (const Bag &source)
{BagList *tmp = head; // réinitialisation
du pointeur this
while
(tmp != (BagList *) NULL)
{tmp =
tmp->next; delete head; head = tmp; }
BagList *tmp2 = source.head; // copie de
la liste des objets de source
while
(tmp2 != (BagList *) NULL)
{this->add(*(tmp2->ptr)); tmp2 = tmp2->next; }
return
*this;
}
};
Bag::Bag(void) : Object() {}
Bag::~Bag(void)
{BagList *tmp = head; //
destruction de la liste des objets
cout
<<" Destructeur Bag" << endl;
while
(tmp != (BagList *) NULL)
{tmp =
tmp->next; delete head; head = tmp; }
}
void Bag::print(void)
{BagList *tmp = head;
cout
<< "Sac n° " << handle() << ".\n Contenu :
\n";
while
(tmp != (BagList *)NULL)
{cout
<< "\t";
tmp->ptr->print(); //
affichage de la liste des objets.
tmp =
tmp->next;
}
}
bool Bag::has(unsigned long int h) const
{BagList *tmp = head;
while (tmp
!= NULL && tmp->ptr->handle() != h)
tmp =
tmp->next; // Cherche l'objet.
return
(tmp != NULL);
}
bool Bag::is_empty(void) const
{return (head==NULL);}
void Bag::add(Object
&o) //
Ajout d'un objet à la liste
{BagList *tmp = new BagList;
tmp->ptr
= &o;
tmp->next = head;
head =
tmp;
}
void Bag::remove(Object &o)
{BagList *tmp1 = head, *tmp2 = NULL;
while
(tmp1 != NULL && tmp1->ptr->handle() != o.handle())
{tmp2 = tmp1; //
recherche de l'objet
tmp1
= tmp1->next;
}
if (tmp1!=NULL) //
suppression de la liste.
{if
(tmp2!=NULL) tmp2->next = tmp1->next;
else
head = tmp1->next;
delete tmp1;
}
}
class MonObjet : public Object
{public :
int
entier;
MonObjet(){entier=0;}
MonObjet(int donnee){entier=donnee;}
void
print(void);
};
void MonObjet::print(void)
{cout <<entier << endl;}
int main(void)
{Bag *MonSac = new Bag;
Bag *MonSac2 = new Bag;
MonObjet a(1), b(5), c(8), d(10), e(3);
cout
<< "On ajoute a=1 b=5 c=8 b=5 d=10 à sac n°1" << endl;
MonSac->add(a);
MonSac->add(b);
MonSac->add(c);
MonSac->add(b);
MonSac->add(d);
MonSac->print();
cout
<< "On enleve b à sac n°1" << endl;
MonSac->remove(b);
MonSac->print();
//
appel récursif
cout
<< "On copie Sac 1 dans Sac 2 (copie inversée)" << endl;
*MonSac2 = *MonSac;
MonSac2->print(); //
appel récursif
cout
<< "On ajoute Sac 2 à Sac 1" << endl;
MonSac->add(*MonSac2);
MonSac->print(); // appel
récursif
delete
MonSac;
delete
MonSac2;
return
0;
}
// résultat
On ajoute a=1 b=5 c=8 b=5 d=10 à sac n°1
Sac n° 1.
Contenu
:
10
5
8
5
1
On enleve b à sac n°1
Sac n° 1.
Contenu
:
10
8
5
1
On copie Sac 1 dans Sac 2 (copie inversée)
Sac n° 2.
Contenu
:
1
5
8
10
On ajoute Sac 2 à Sac 1
Sac n° 1.
Contenu
:
Sac
n° 2.
Contenu
:
1
5
8
10
10
8
5
1
Destructeur Bag
Destructeur Bag
Þ
Remarques
·
La classe
de base sert de cadre (frame) aux classes dérivées.
·
La classe
Bag permet de stocker des objets dérivant de la classe Object avec les méthodes
add et remove.
·
La faculté
d'interdire à une méthode virtuelle pure définie dans une classe dérivée
d'accéder en écriture aux données de la classe de base et à celles de sa classe
peut faire partie de ses prérogatives par qualification const du pointeur this (pointeur
constant sur un objet constant). Ainsi, dans l'exemple ci‑dessous, la
méthode virtuelle pure print
qualifiée const permet l'accès en
lecture seule à l'objet h.
·
Les autres
méthodes ont un accès total, y compris celles des classes dérivées qui ne
surchargent pas une méthode de la classe de base.
·
Cette
méthode d'encapsulation est coopérative
et permet de détecter des erreurs à la compilation. Elle peut s'appliquer aux méthodes virtuelles non pures ou aux fonctions non virtuelles.
!
Exemple
class Object
{unsigned long int
new_handle(void);
protected: //
Héritage de la classe Object qualifié protected
unsigned long int
h;
public:
Object(void); //
Le constructeur de la classe Object
virtual void print(void) const=0; // Méthode virtuelle
pure qualifiée constante
unsigned long int handle(void); //
Méthode retournant le numéro d'identification de l'objet
};
12.1
Généralités
Les classes abstraites permettent de définir
des structures de données relativement indépendantes de leur classe. Par ailleurs,
les fonctions surchargées peuvent
opérer sur de nombreux types différents. Malheureusement, l'emploi des classes
abstraites est assez fastidieux, et la surcharge ne peut être généralisée à
tous les types de données.
Þ
Définitions
Ces problèmes
sont résolus par les modèles génériques
que sont les paramètres génériques,
les fonctions génériques, les classes génériques, les méthodes génériques appelés souvent objets modèle ou objets template ou encore
simplement modèle ou template.
·
Un paramètre générique est un type générique ou une constante de type intégral.
·
Les classes génériques ont des
membres génériques (paramètres et/ou méthodes).
·
Les fonctions et méthodes génériques opèrent
sur des paramètres génériques.
Þ
Instanciation
des paramètres génériques
·
La
compilation effectue, à la première
utilisation d'une fonction ou d'une classe générique, le remplacement des types génériques par leur type effectif
et celui des constantes de type intégral
par leur valeur.
·
Les types effectifs sont déterminés implicitement
à partir du contexte d'utilisation du paramètre générique ou avec des paramètres explicites.
·
Cette phase
est appelée instanciation des paramètres
génériques.
12.2
Déclaration de type générique
Syntaxe
template <class|typename nom[=type] [, class|typename nom[=type] […]>
où nom est
l'identificateur du type générique.
Þ
Les mots
clés class et typename
Le mot-clé class permet ici de définir un type
générique et peut être remplacé par le mot-clé typename.
Þ
Type
générique par défaut
On déclare des valeurs par défaut d'une liste de types
génériques leurs identificateurs étant alors respectivement suivis d'un signe
égal et du nom d'un type préalablement déclaré.
!
Exemple
// Déclaration de types génériques
template <class T,
typename U, class V=int>
Þ
Interprétation
·
Les mots
clés class
et typename ont même
signification dans ce contexte d'utilisation.
·
Les types génériques T, U,V peuvent être instanciés à partir de n'importe quel
type prédéfini ou préalablement déclaré.
!
Exemple
#include <iostream.h>
template <class U, class V, class W=char>
void f(U valeur1, V valeur2, W valeur3)
{cout << "valeur1 = "<<
valeur1 << " valeur2 = " << valeur2 <<
"valeur3 =" << valeur3 << endl;}
int main(void)
{int a=1;
double
c=3.45;
f(a,c,'c');
f(c,a,12);
}
//résultat
valeur1 = 1 valeur2 =3.45 valeur3 = c
valeur1 =
3.45 valeur2 = 1valeur3 = 12
Þ
Liste de
types génériques par défaut
Un type
générique avec une valeur par défaut impose
d'en définir à tous les types génériques qui le suivent dans la déclaration. La
ligne suivante provoque donc une erreur de compilation :
template <class T=int,
class V>
12.3
Fonction et classe générique
La déclaration
d'un ou plusieurs paramètres génériques
peut suivre la définition d'une fonction
ou d'une classe générique dans laquelle les
types génériques sont utilisés comme des types traditionnels, les constantes
génériques comme des constantes
locales.
12.3.1
Fonctions avec des types
d'arguments génériques
Þ
Déclaration
La déclaration et la définition d'une fonction
générique (fonction modèle) sont similaires à celle d'une fonction
traditionnelle, celles‑ci devant toutefois être précédées de la
déclaration template.
Syntaxe
template <liste_paramètres_génériques>
type_retour fonction(arguments_fonction);
Description
·
liste_paramètre_génériques représente la liste des paramètres génériques. Ceux qui
représentent des types sont décrits
dans la liste des arguments (sauf en cas d'instanciation explicite) ce qui
permet l'identification à la compilation des types génériques et des types effectifs
·
arguments_fonction représente la liste des arguments de la
fonction,
·
type_retour représente le type de l'objet retourné qui peut
être un des types génériques de la liste.
Þ
Définition
·
La
définition d'une fonction générique est
similaire à sa déclaration.
·
On peut y
utiliser les paramètres génériques comme les paramètres traditionnels, des variables
d'un type générique, des constantes génériques comme des variables
locales qualifiées const.
!
Exemple
// Définition de
fonction générique
template <class T>
T Min(T x, T y)
{return x<y ? x
: y;}
La fonction Min
ainsi définie peut être appelée depuis toute classe où l'opérateur < est
surchargé.
!
Exemple
#include <iostream.h>
template <class T>
T Min(T x, T y)
{return x<y ? x : y;}
int main(void)
{int x=1, y=2;
float a=
-6.7, b=5.67;
double
c=4.56, d = 18.23;
cout
<< Min(x,y) << endl;
cout
<< Min(a,b) << endl;
cout
<< Min(c,d) << endl;
}
Þ Surcharge et fonction générique
·
Une fonction générique peut être surchargée par une fonction classique ou générique.
·
L'ambiguïté
entre fonction générique et fonction traditionnelle est résolue par le choix
de la fonction traditionnelle.
Þ Amitié et fonctions génériques
·
Une
fonction générique peut être amie de toute classe non locale,
éventuellement générique.
·
Toutes les
instances générées à partir d'une fonction
générique amie de la classe le sont.
Une classe générique (classe modèle ou classe template) peut être considérée comme un type
générique donc comme une classe de
classes ou métaclasse dont les paramètres
génériques caractérisent la généricité, pas celle d'une méthode
générique d'une classe non générique.
Þ
Déclaration
et définition
La déclaration et la définition d'une classe modèle sont précédées du qualificatif template.
Syntaxe de la
déclaration
template <paramètres_génériques>
class|struct|union identificateur_classe_générique;
où paramètres_ génériques représente la
liste des paramètres génériques utilisés par la classe générique.
Þ
Méthode
définie à l'extérieur d'une classe générique
·
Les
méthodes d'une classe générique
définies à l'extérieur y sont qualifiées template.
·
Les types génériques d'une méthode externe à une classe sont toujours
spécifiés, à sa définition ou déclaration, entre les opérateurs de
comparaison, après l'identificateur de la classe.
Syntaxe
template <paramètres_ génériques>
type identificateur_classe_générique<
paramètres_génériques>::méthode(liste_arguments)
{…}
Þ
Méthode
définie dans une classe générique
Une méthode
définie dans une classe générique peut utiliser ses types génériques dans sa
liste d'arguments sans déclaration, leur type effectif étant déterminé à l'instanciation
de la classe.
Þ Classes génériques et amitié
Les classes génériques peuvent avoir des fonctions amies éventuellement génériques.
!
Exemple de classe générique
// Définition d'une classe modèle de pile
#include
<iostream.h>
template
<class T>
class Stack
{typedef struct stackitem
{T Item; // le type T est utilisé comme un type normal
struct
stackitem *Next;
}
StackItem;
StackItem *Tete;
public:
// Déclaration des méthodes opérant sur la pile
Stack(void); //
les constructeurs
Stack(const Stack<T> &);
// Le
type effectif de la classe peut être référencée entre les opérateurs de
comparaison ("Stack<T>").
~Stack(void); // le
destructeur
Stack<T> &operator=(const Stack<T> &); // surcharge de l'opérateur d'affectation
void
push(T); // empilement
T
pop(void); // dépilement
bool
is_empty(void) const; // test de pile
vide
void
flush(void); // vidage de la pile
};
// Déclaration de type générique pour les méthodes
définies à l'extérieur de la de la classe
// toujours référencée par son type entre les
opérateurs de comparaison <T>
template <class T>
Stack<T>::Stack(void)
{Tete = NULL; return;}
template <class T>
Stack<T>::Stack(const Stack<T>
&Init)
{Tete = NULL;
StackItem *tmp1 = Init.Tete, *tmp2 = NULL;
while
(tmp1!=NULL)
{if
(tmp2==NULL) {Tete= new StackItem;
tmp2 = Tete;}
else
{tmp2->Next = new StackItem; tmp2 = tmp2->Next;}
tmp2->Item
= tmp1->Item;
tmp1
= tmp1->Next;
}
if
(tmp2!=NULL) tmp2->Next = NULL;
return;
}
template <class T>
Stack<T>::~Stack(void)
{flush(); return;}
template <class T>
Stack<T>
&Stack<T>::operator=(const Stack<T> &Init)
{flush();
StackItem *tmp1 = Init.Tete, *tmp2 = NULL;
while
(tmp1!=NULL)
{if
(tmp2==NULL) {Tete = new StackItem;
tmp2 = Tete;}
else
{tmp2->Next = new StackItem; tmp2 = tmp2->Next;}
tmp2->Item = tmp1->Item;
tmp1 =
tmp1->Next;
}
if
(tmp2!=NULL) tmp2->Next = NULL;
return
*this;
}
template <class T>
void Stack<T>::push(T Item)
{StackItem *tmp = new StackItem;
tmp->Item = Item;
tmp->Next = Tete;
Tete =
tmp;
return;
}
template <class T>
T Stack<T>::pop(void)
{T tmp;
StackItem *ptmp = Tete;
if
(Tete!=NULL)
{tmp =
Tete->Item; Tete = Tete->Next;
delete ptmp; }
return
tmp;
}
template <class T>
bool Stack<T>::is_empty(void) const
{return (Tete==NULL);}
template <class T>
void Stack<T>::flush(void)
{while (Tete!=NULL) pop(); return;}
int main(void)
{Stack <int> int_Pile, Pile;
Stack
<float> float_Pile[10];
int k=0;
k=int_Pile.is_empty();
cout
<< "k = " << k << endl;
int_Pile.flush();
k=int_Pile.is_empty();
cout
<< "k = " << k << endl;
Pile=int_Pile;
int i;
for( i =
0; i < 10; i++ )
{int_Pile.push(i);
float_Pile[i].flush();
float_Pile[i].push((float)i);
}
int j=0;
j=int_Pile.is_empty();
cout
<<" j = " << j << endl;
for(i=0;
i < 10;i++)
{j=float_Pile[i].is_empty();
cout
<<" j = " << j << endl;
}
}
12.3.3
Méthodes génériques
Þ Définition
·
Une méthode générique opére sur un argument de type générique au
moins à l'exception des destructeurs, que la classe soit générique ou non.
·
Elle peut
être définie dans la classe ou à l'extérieur.
Þ Classe d'appartenance non générique
La syntaxe d'appel est identique à celle d'une
fonction générique non membre.
! Exemple
#include <iostream.h>
class A
{int i;
public:
//déclaration
template
<class T>
void
add(T);
A(){i=3;}
// constructeur
};
//
Méthode générique définie à l'extérieur de la classe
template
<class T>
void
A::add(T valeur)
{i=i+((int)
valeur);
cout << i << endl;
}
int
main( void)
{A
objet;
objet.add(1);
objet.add(-18.67);
objet.add(1e3);
}
//
résultat
4
-14
-986
Þ Classe d'appartenance générique
·
Deux spécifications
du mot clé template sont
nécessaires : une pour la classe,
une pour la méthode.
·
La
définition d'une méthode générique
dans une classe est identique à celle d'une fonction générique. Il n'est pas
obligatoire d'y indiquer les paramètres génériques de la classe.
! Exemple
// Méthode générique d'une classe générique
template<class
C>
class
string
{public:
// Méthode générique définie à l'extérieur de la classe générique
template<class M> int compare(const M &);
// Constructeur générique définie dans de la classe générique
template<class M>
string(const string<M> &s)
{/* … */}
};
// À l'extérieur de la classe générique,
deux déclarations template (classe
puis méthode générique)
template<class
C> template<class M>
int string<T>::compare(const M
&s)
{/*…*/}
Þ Définitions
·
La
définition d'une méthode et/ou d'une classe générique ne génère aucun code
exécutable tant que tous ses paramètres génériques ne sont pas explicitement initialisés.
·
La définition effective de tous les
paramètres modèles d'une fonction ou d'une classe générique lors de son
utilisation s'appelle l'instanciation des
paramètres génériques.
·
L'instanciation implicite des paramètres génériques est effectuée
à la première utilisation d'une fonction ou d'une classe modèle.
·
Le type effectif d'un paramètre générique est
déterminé par son contexte d'utilisation.
Þ
Situation
non ambiguë
Soit le programme :
#include <iostream.h>
template <class T>
T Min(T x, T y)
{return x<y ? x : y;}
int main(void)
{// instanciation implicite avec des arguments
de type int
int i = Min(2,3);
cout << i << endl;
}
L'appel de la
fonction générique Min avec les arguments entiers 2 et 3, provoque l'instanciation implicite de la
fonction dont l'argument type générique
T est remplacé par le type effectif int.
Þ
Ambiguïté
Quand l'appel
d'une fonction générique provoque une ambiguïté, le compilateur génère une
erreur qui peut être évitée par la surcharge adéquate de la fonction.
!
Exemple
La fonction générique
Min ne peut pas être instanciée dans le cas suivant :
int i=Min(2,3.0);
le compilateur
ne pouvant déterminer le type effectif
des arguments (int ou double).
Þ
Résolution
de l'ambiguïté
Ce problème est
résolu par la spécification explicite
des paramètres génériques de la fonction à l'appel.
Min<int>(2,3.0)
ou mieux
Min<double>(2,3.0)
!
Exemple
#include <iostream.h>
template
<class T>
T Min(T
x, T y)
{return
x<y ? x : y;}
int
main(void)
{cout
<< Min(2,3)<< endl;
cout << Min(4.6,-56.) << endl;
cout << Min<int>(2,3.15) <<
endl; // spécification
explicite
cout << Min<double>(2,3.15)
<< endl; // spécification
explicite
}
Þ Syntaxe simplifiée
La syntaxe peut être simplifiée à condition que
le compilateur puisse déduire l'instanciation de tous les arguments génériques
à partir des définitions de l'objet et du type de ses arguments.
! Exemple
La déclaration
ci‑dessous, extérieure à la fonction main(),
provoque l'instanciation implicite de la fonction générique Min avec le type int :
template int Min(int, int);
Programme
#include <iostream.h>
template
<class T>
T Min(T
x, T y)
{return
x<y ? x : y;}
template
int Min(int, int); //
spécification du type par défaut de l'instanciation
int
main(void)
{cout
<< Min(2,3)<< endl;
cout << Min(4.6,-56.) << endl;
cout << Min<double>(2,3.15)
<< endl;
}
Þ
Définition
La définition explicite de tous les
paramètres génériques est appelée instanciation explicite.
Syntaxe
identificateur_de_l'objet_générique
< type_générique> identificateur_instance
Þ
Valeur par
défaut
Une invocation
avec une liste de valeur vide
(opérateurs de comparaison) provoque l'utilisation des valeurs par défaut à l'instanciation.
!
Exemple
template<class
T = char> // spécification du type
d'instance par défaut (char)
class Chaine <T>{/*définition de la
classe Chaine*/};
…
Chaine<> String; // L'objet String est instancié avec le type par
défaut de la classe Chaine<char>.
!
Exercice
Définir une classe générique pour un objet
Pile constituée :
·
d'un champ Tableau d'un type générique
TYPE et de son pointeur de pile entier,
·
d'un constructeur
et d'un destructeur,
·
de méthodes d'empilement, de dépilement,
et de test de pile vide.
La pile sera instanciée explicitement avec des
objets de type entier (type par défaut), flottant, chaîne de caractères.
#include <stdio.h>
const int MAXSIZE = 128;
template<class TYPE=int> // type de l'instance par défaut
class Pile
{TYPE Tableau[MAXSIZE];
int
Pointeur_Pile;
public:
Pile(void) {Pointeur_Pile = 0;}; //
Constructeur
void
push(TYPE in_dat) {Tableau[Pointeur_Pile++] = in_dat;};
TYPE
pop(void) {return
Tableau[--Pointeur_Pile];};
int
vide(void) {return (Pointeur_Pile
== 0);};
};
char nom[] = "John Lee Hooker";
int main(void)
{int x = 12, y = -7;
float
reel = 3.1415;
Pile<> int_Pile; //
instanciation avec le type int par
défaut
Pile<float> float_Pile; // instanciation
avec le type float
Pile<char *> string_Pile; // instanciation avec
le type char *
int_Pile.push(x);
int_Pile.push(y);
int_Pile.push(77);
float_Pile.push(reel);
float_Pile.push(-12.345);
float_Pile.push(100.01);
string_Pile.push("Première ligne");
string_Pile.push("Deuxième ligne");
string_Pile.push("Troisième ligne");
string_Pile.push(nom);
printf("Pile d'entiers ---> ");
printf("%8d ", int_Pile.pop());
printf("%8d ", int_Pile.pop());
printf("%8d\n", int_Pile.pop());
printf(" Pile de flottants
---> ");
printf("%8.3f ", float_Pile.pop());
printf("%8.3f ", float_Pile.pop());
printf("%8.3f\n", float_Pile.pop());
printf("\n Chaînes de
caractères\n");
do
{printf("%s\n", string_Pile.pop());}
while
(!string_Pile.vide());
return
0;
}
// Résultat
Pile d'entiers ---> 12 -7 77
Pile de flottants ---> 3.141
-12.345 100.010
Chaînes de caractères
John Lee
Hooker
Troisième ligne
Deuxième
ligne
Première
ligne
Þ Efficacité du code généré
·
Le
compilateur crée seulement le code nécessaire à une instanciation des
paramètres génériques.
·
L'instanciation
d'un objet d'une classe générique n'est autorisée que si son type est défini.
Par exemple, l'instanciation ne peut pas s'effectuer par la définition d'un
pointeur sur cette classe. Elle n'est possible que sur le pointeur déréférencé.
·
Seules les
fonctionnalités effectivement utilisées de la classe générique sont générées
dans le programme final.
Þ
Exercice
·
Soit une classe générique A avec deux
méthodes f(char*, T type))et g(void).
·
Définir la classe de telle sorte que
seule la méthode générique f soit instanciée. En déduire que la définition
explicite d'une méthode non instanciée n'est pas nécessaire.
#include <iostream.h>
template <class T=double> // double, type T par défaut
class A
{public:
void
f(char *,T type);
void g(void);
};
// Définition de la méthode A<>::f()
template <class T>
void A<T>::f(char * chaine, T objet)
{cout << "A<T>::f("
<< chaine << ")" << " objet = " <<
objet << endl;}
// Il n'est pas nécessaire que la méthode
A<char>::g(){...} soit définie dans ce cadre
int main(void)
{A<char> a; // Instanciation explicite
par le type char de la classe générique A<char>
char c='c';
a.f("char", c); // Instanciation explicite de la
méthode générique A<char>::f()
int b=25;
A<int> i; // Instanciation explicite par le type int de la
classe générique A<int>
i.f("int",b ); // Instanciation explicite de
la méthode générique A<int>::f()
A<> d; // Instanciation par défaut de la méthode
générique A<double>::f()
d.f("defaut",3.1416e0);
return
0;
}
// Résultat
A<T>::f(char)
objet = c
A<T>::f(int)
objet =25
A<T>::f(défaut)
objet =3.1416
12.4.3
Problèmes soulevés par
l'instanciation des objets génériques
Les objets
génériques devant être définis lors de leur instanciation, les fichiers en-tête
doivent contenir leur déclaration et définition complète.
Þ
Inconvénients
·
Les objets
génériques ne peuvent être traités comme les fonctions et classes
traditionnelles, pour lesquels il est souhaitable de séparer dans des fichiers
les définitions des déclarations.
·
Les
instances des objets génériques sont compilées plusieurs fois donc redéfinies
dans les fichiers objets et accroissent la taille des fichiers exécutables. Ça
n'est pas gênant pour les petits programmes, mais peut devenir rédhibitoire
pour les gros.
Þ
Conséquences
·
Le premier
problème n'est pas trop gênant car il réduit le nombre de fichiers sources.
·
Le deuxième
problème a plusieurs solutions.
à
Certains
compilateurs imposent une instanciation explicite.
à
Des
compilateurs optimisés génèrent des fichiers en-tête précompilés contenant le résultat de l'analyse des fichiers en-tête
déjà traités ce qui peut imposer d'utiliser un unique fichier en‑tête.
à
D'autres
compilateurs gèrent une base de données des instances des objets génériques
utilisées à l'édition de liens pour la résolution des références non
satisfaites de la table des symboles.
à
Une autre
technique nécessite une modification de l'éditeur de liens pour qu'il regroupe
les différentes instances des mêmes objets génériques.
Jusqu'à présent,
les classes et les fonctions génériques sont définis d'une manière unique, pour
tous les types valeurs des paramètres génériques. Cependant, dans certaines
situations, il peut être utile de définir une version spécifique d'une classe
ou d'une fonction pour un jeu donné de paramètres génériques.
!
Exemple
La pile définie
dans les exemples précédents peut être implémentée plus efficacement si elle
stocke des pointeurs. Il suffit que la méthode pop retourne un objet.
Þ
Définition
Une fonction ou une classe générique peut
être spécialisée pour un jeu donné de
paramètres génériques. Deux types de spécialisation sont
définis : les spécialisations
partielles, pour lesquelles quelques
paramètres génériques ont une valeur fixée, et les spécialisations totales pour lesquelles tous les paramètres génériques ont une valeur déterminée.
12.5.1
Spécialisation partielle d'une classe
Þ Objet
Une spécialisation
partielle permet de définir l'implémentation d'une
fonction ou d'une classe générique pour des valeurs fixées de certains de ses paramètres génériques dont la nature
peut varier (par exemple un pointeur) pour imposer au compilateur le choix de
l'implémentation correspondante.
Þ Syntaxe
La liste des paramètres génériques, préalablement
déclarés, est spécifiée entre les opérateurs de comparaison à la définition de
la classe ou de la fonction générique.
! Exemple
#include <iostream.h> //
Exemple de spécialisation partielle
// Définition d'une classe générique
template <class T1, class T2, int I>
class A
{public : T1 champ1;
A(){cout << " 0 " << endl;}
};
template <class T, int I>
class A<T, T*, I> //
Spécialisation 1
{public: A(){cout << " 1 " << endl;}};
template <class T1, class T2, int I>
class A<T1*, T2, I> //
Spécialisation 2
{public: A(){cout << " 2 " << endl;}};
template <class T>
class A<T*, int, 5> //
Spécialisation 3
{public: A(){cout << " 3 " << endl;}};
template <class T1, class T2, int I>
class A<T1, T2*, I> //
Spécialisation 4
{public: A(){cout << " 4 " << endl;}};
template <class T2, int I>
class A<T2, int, I> //
Spécialisation 5
{public: A(){cout << " 5 " << endl;}};
int main(void)
{A<int,float,4> essai;
A<float, int, 6> essai2;
A<int, int*, 2> essai3;
A<char*,double,6> essai4;
A<int,float*, 7> essai5;
A<char*,int,5> essai6;
}
//
résultat
0
5
1
2
4
3
Þ Règles d'utilisation
Les spécialisations
doivent
respecter les règles suivantes :
·
Le nombre
des paramètres génériques déclarés à la suite du mot-clé template peut varier.
·
Le nombre
de valeurs spécialisées doit rester constant (dans l'exemple précédent, il y en
a trois).
·
Un
paramètre ne peut pas être exprimée en fonction d'un autre paramètre générique
de la spécialisation.
·
Le type
d'une des valeurs de la spécialisation ne peut pas dépendre d'un autre
paramètre.
·
La liste
des paramètres de la spécialisation ne doit pas être identique à la liste
implicite de la déclaration template
correspondante.
·
La
déclaration de liste des paramètres template d'une spécialisation ne doit pas contenir des valeurs par
défaut inutilisables.
! Exemple 1
template <int I, int J>
struct B {};
template <int I>
struct B<I, I*2> // Erreur ! Spécialisation incorrecte
{};
! Exemple 2
template <class T, T t>
struct C {};
template <class T>
struct C<T, 1>; // Erreur! Spécialisation incorrecte!
Syntaxe
·
La spécialisation totale impose de
fournir une liste vide de paramètres
génériques entre les opérateurs de comparaison, après l'identificateur de la
fonction ou de la classe générique.
·
La définition de cette fonction ou classe doit
être précédée de l’instruction :
template <>
!
Exemple 1
Soit la fonction
Min définie plus haut, utilisée sur une structure Structure et devant exploiter
un de ses champs pour effectuer les comparaisons. Elle peut être spécialisée de
la manière suivante :
// Spécialisation totale
struct Structure
{int Clef; //
Clef de recherche des données.
void
*pData; //
Pointeur sur les données.
};
template <>
Structure Min<Structure>(Structure s1,
Structure s2)
{if (s1.Clef<s2.Clef) return s1; else return
s2;}
Þ
Remarque
Certains
compilateurs n'acceptent pas la liste vide des paramètres template ce qui n'est pas portable.
12.5.3
Spécialisation d'une méthode
d'une classe générique
La
spécialisation partielle d'une classe peut parfois être assez lourde, en
particulier si la structure de données qu'elle contient est identique dans les
différentes versions spécialisées. Dans ce cas, il peut être plus simple de ne
spécialiser que certaines méthodes ce qui permet d'éviter de redéfinir les
données membres non concernées.
Syntaxe
La méthode est spécialisée par la définition de certains de ses paramètres génériques.
!
Exemple
// méthode spécialisée d’une
classe générique
#include
<iostream.h>
template
<class T>
class
Item
{public
: T item;
public:
Item(){item=(T)0;} // Constructeur par défaut
Item(T);
void set(T);
T get(void) const;
void print(void) const;
};
template
<class T>
Item<T>::Item(T
i) // Constructeur
{item =
i;}
//
Accesseurs
template
<class T>
void
Item<T>::set(T i)
{item =
i;
cout << "set : item = " <<
item << endl;
}
template
<class T>
T
Item<T>::get(void) const
{cout
<< "get : item " << item << endl;return item;}
//
Fonction d'affichage générique :
template
<class T>
void
Item<T>::print(void) const
{cout
<< "print générique : " << item << endl;}
//
Fonction d'affichage spécialisée pour le type int * et la méthode print
template
<>
void
Item<int *>::print(void) const
{cout
<< *item << endl;}
int
main(void)
{int
a=8,b,*pa=&a;
float pi=3.1416;
Item <int> entier;
Item <float> flottant(pi);
Item <int *> pointeur(pa);
entier.set(a);
entier.get();
entier.print();
flottant.get();
flottant.print();
pointeur.get();
pointeur.print();
}
//
résultat
set :
item = 8
get :
item 8
print
générique : 8
get :
item 3.1416
print
générique : 3.1416
get :
item 0xbffff9d4
8
·
Une classe générique peut être interprétée
comme un paramètre décrivant un type
générique d’une autre classe. Elle est alors considérée comme une classe de classes ou métaclasse.
·
Elle est
qualifiée template dans la
déclaration template et est appelée paramètre template template.
·
Une
instanciation par défaut dont le type est une classe générique définie préalablement est autorisée.
Syntaxe
template <template
<class Type> class Classe [,…]>
où Type est le type générique défini dans la déclaration de la classe générique
Classe.
! Exemple
// Déclaration de paramètres template template
template <class T>
class Tableau
{public: T tab[10]; }; //
La classe template Tableau
template <class U, class V, template <class T> class
C=Tableau>
// C : instance de la classe
Tableau par défaut, d'un type générique U ou V
class Dictionnaire //
Définition de la classe Dictionnaire
{public:
C<U> Clef; //
Création de la dépendance : Clef est un tableau de type U
C<V> Valeur; //
Valeur est de type V
};
int main(void)
{Dictionnaire <int, short> Dico; //Clef
de type int, Valeur type short
Dictionnaire <double, char> Dico2;
Tableau <int> liste; //liste,
instancié comme tableau d'entier
Tableau <float> liste_flottant;
int i;
Dico.Clef.tab[5]=2; //
accès au dictionnaire
}
Þ Interprétation
·
La classe générique Dictionnaire permet
d’associer des données membres à une classe générique.
·
Les données
membres sont décrites respectivement par les classes (conteneurs) génériques Clef et Valeur dont le type (classe) générique est
défini par le paramètre template template C.
·
Ce dernier
décrit les types génériques U et V
instanciés par le type générique
Tableau comme conteneur par défaut.
12.7
Déclaration des constantes génériques
Syntaxe
La déclaration de paramètre générique de
type constante est effectuée selon la
syntaxe :
template <type_paramètre_générique
identificateur_paramètre_générique[=valeur_par_défaut][, …]>
Dans une même déclaration, les paramètres génériques peuvent être des types
où des constantes.
Þ Constantes génériques
Le type des constantes
génériques (template)
est l'un des suivants :
·
type
intégral (char, wchar_t, int, long,
short et leurs versions non signées)
ou énuméré.
·
pointeur ou référence
d'objet.
·
pointeur ou référence
de fonctions.
·
pointeur sur membre.
! Exemple
// Déclaration de paramètres de type constante générique
template <class
T, int i, void (*f)(int)>
Cette déclaration template est constituée d'un type générique T, d'une constante
générique i de type int, et d'une constante générique f de type pointeur
sur procédure avec un argument entier.
Þ Remarque
Nous verrons que les paramètres constants de type
référence ne peuvent pas être initialisés avec une donnée (immédiate ou
temporaire) lors de l'instanciation du
paramètre générique.
! Exemple
#include
<iostream.h>
template
<int valeur> void f(void) //
constante générique
{int
aux;
aux=valeur; //affectation possible
cout
<< "valeur = " << aux << endl;
}
int
main(void)
{f<5>(); // affiche 5
const int a=8;
f<a>(); //
affiche 8
}
·
Une méthode virtuelle ne peut être générique.
·
Une méthode générique avec le même
identificateur qu'une méthode virtuelle d'une classe de base ne la surcharge
pas.
·
La méthode
virtuelle peut appeler la méthode générique.
! Exercice et exemple
Ecrire une classe de base avec une méthode
virtuelle f.
Ecrire une classe de dérivée avec une méthode
générique f. La méthode virtuelle appelle la méthode générique et l'appel n'est
pas récursif.
// Méthode générique et méthode virtuelle
#include
<iostream.h>
class B
{public
:
virtual void f(int); // méthode virtuelle
};
void B::f(int entier)
{cout
<< "B::f : " << entier << endl;}
class D
: public B
{public
:
template <class T>
void f(T); //
méthode générique ne surchargeant pas B::f(int)
void f(int i) // surcharge de la méthode virtuelle B::f(int)
{f<>(i);} // Appel (non récursif) de la méthode générique
};
template
<class T >
void
D::f(T type) {cout << "F générique : " << type <<
endl;}
int
main(void)
{B
Base;
Base.f(1);
D Derive;
Derive.f(2);
}
//
résultat
B::f :
1
F
générique : 2
Þ Méthodes génériques et classiques
Soient une méthode générique et une méthode non
générique avec une même signature. Cette dernière est toujours appelée sauf
spécification explicite des paramètres génériques entre les opérateurs de
comparaison.
! Exemple 1
//
Méthode générique d'une classe générique
//
Surcharge de méthode classique par une méthode générique
#include
<iostream.h>
struct
A //prototypes
{void
f(int); // méthode non générique
template <class T>
void f(T);
};
// Définition de la méthode classique
void
A::f(int entier)
{cout
<< "A::f(int) = " << entier << endl;}
//
Définition de la méthode générique
template
<>
void
A::f<int>(int entier)
{cout
<< "A::f<int>(int) = " << entier << endl;}
int
main(void)
{A a;
a.f(1);
// Appel de la version classique
a.f<>(2); // Appel de la version générique spécialisée
}
//
résultat
A::f(int)
= 1
A::f<int>(int)
= 2
! Exemple 2
//
Surcharge d’une méthode non générique par une méthode générique
#include
<iostream.h>
struct
A
{void
f(int);
template <class T>
void f(T);
};
//
Méthode classique
void
A::f(int entier)
{cout
<< "A::f(int) = " << entier << endl;}
//
Méthode générique
template
<class T>
void
A::f(T valeur)
{cout
<< "A::f(T) = " << valeur << endl;}
int
main(void)
{A a;
a.f(1); // Appel de
la méthode classique
a.f<char>('c'); // Appel de la méthode
générique instanciée
a.f<>('c'); // Appel de la
méthode générique spécialisée
a.f<>(2); // Appel de la
méthode générique spécialisée
}
//
résultat
A::f(int)
= 1
A::f(T)
= c
A::f(T)
= c
A::f(T)
= 2
Nous avons vu que
le mot-clé typename peut être utilisé pour introduire les types génériques dans les
déclarations template.
Le mot-clé typename indique également qu'un
identificateur inconnu est un type
utilisable dans la définition des objets génériques.
Syntaxe
typename identificateur
!
Exemple
//
Utilisation spécifique du mot-clé typename
#include <iostream.h>
class A
{public:
typedef int Y; // Y est un type défini dans
la classe A
};
template <class T>
class X
{public:
typename T::Y i; }; //
La classe template X suppose que le type générique T définit un type Y
int main()
{
X<A> x; //
La classe A permet d'instancier à partir de la classe générique X
x.i=3;
cout << "x.i=" << x.i << endl;
}
·
Les effets
de la programmation des objets génériques sont différents de ceux de la
programmation traditionnelle car une instanciation est nécessaire pour générer
le code exécutable associé à l’objet modèle.
·
D'un point
de vue commercial, des bibliothèques d’objets génériques peuvent ne pas être fournies
par des sociétés soucieuses de conserver leur savoir‑faire.
·
Pour
résoudre ce problème, la norme actuelle permet de les compiler séparément et d'exporter les définitions des objets
génériques dans des fichiers et d'éviter ainsi l'inclusion de leur définition
dans les fichiers sources.
Syntaxe
Les fonctions et
les classes génériques concernées sont exportées à partir du mot clé export.
Þ
Description
·
Les
définitions des fonctions et des classes exportées
doivent être qualifiées export.
·
L'exportation d'une classe générique exporte toutes ses
méthodes non qualifiées inline,
toutes ses données statiques, toutes ses classes membres et toutes ses méthodes
génériques non statiques.
·
Une
fonction générique qualifiée inline,
les fonctions et les classes génériques définies dans un espace de nommage
anonyme ne peuvent pas être exportées.
!
Exemple
// Mot-clé export
export template <class T>
void f(T); // Fonction dont
le code n'est pas fourni
// Code exporté de f
export template <class T>
void f(T p)
{…} // Corps de la fonction.
Þ
Remarque
Aucun compilateur ne gère le mot clé export actuellement.
Les espaces de nommage sont des zones de déclaration permettant de
délimiter la recherche des identificateurs. Ils regroupent des identificateurs
pour éviter les conflits entre des parties d'un même projet. Par exemple, deux
programmeurs définissant un même identificateur de structure dans deux fichiers
différents provoquent un conflit à l'édition de lien, et dans le pire des cas
lors de l'utilisation commune des fichiers sources.
La source de ce
type de conflit est due à l'unicité de l'espace de nommage de portée globale du
langage C++, dans lequel aucun conflit d'identificateur n'est autorisé.
Ce problème peut
être contourné par utilisation des espaces
de nommage non globaux.
13.1
Espace nommé et anonyme
Lorsque le
programmeur donne un identificateur à un espace
de nommage, ce dernier est appelé espace
de nommage nommé ou plus simplement espace
de nommage, espace nommé, ou espace.
Syntaxe
namespace identificateur_espace_nommage
{déclarations |
définitions}
identificateur_espace_nommage
est le nom de l'espace de nommage, déclarations
et définitions contiennent la liste
des identificateurs le constituant.
Contrairement
aux régions déclaratives classiques du langage (par exemple les classes), un
espace de nommage peut être découpé en plusieurs parties, la première étant
utilisée pour les déclarations, les suivantes pour les extensions.
La syntaxe pour
une extension d'un espace de nommage
est identique à celle de la partie déclaration.
!
Exemple
namespace A // L'espace de nommage A
{int i;}
…
namespace B // L'espace de nommage B
{int i;}
…
namespace A // Extension de l'espace de nommage A
{int j;}
·
Les
identificateurs déclarés ou définis à l'intérieur d'un espace ne doivent pas
entrer en conflit sauf s'ils sont surchargés.
·
L'opérateur de résolution de portée permet
l'accès aux identificateurs des espaces de nommage.
!
Exemple
#include
<iostream.h>
int i=1; // i est global
namespace A
{int i=2; //
i défini dans l'espace de nommage A.
int j=i; //
Utilise A::i.
}
int main(void)
{cout << "i = " << i << endl; // Utilise ::i
cout <<
"A::i = " << A::i << endl; // Utilise A::i
A::i=3; //
Utilise A::i
cout <<
"A::i = " << A::i << endl;
return 0;
}
// résultat
i=1
A::i=2
A::i=3
Þ
Définition
Les fonctions
d'un espace de nommage peuvent y être définies comme les méthodes. Elles
peuvent être définies en dehors de l'espace avec utilisation de l'opérateur de
résolution de portée et déclaration préalable dans l'espace de nommage.
!
Exemple
namespace A
{int f(void); } // déclaration de A::f
int
A::f(void) // définition externe de
A::f
{return 0;}
Þ
Définition
récursive d'espace
Un espace de
nommage peut être défini dans un autre.
Cette
déclaration apparaît au niveau le plus externe de l'espace de nommage le
contenant. On ne peut donc pas déclarer d'espace de nommage à l'intérieur d'une
fonction ou d'une classe.
!
Exemple
namespace Conteneur // un namespace dans un autre
{int i; //
Conteneur::i.
namespace Contenu {int j;} //
Conteneur::Contenu::j
}
13.1.2
Espace anonyme
Þ
Définition
Un espace anonyme est caractérisé par
l'absence d'identificateur à sa déclaration.
Þ
Utilisations
Ce type d'espace
garantissant comme les autres l'unicité de ses identificateurs, il peut être
utilisé à la place du mot-clé static
pour garantir l'unicité des objets d'un fichier. La directive using (cf. plus loin)
permet d'accéder à ses identificateurs sans nécessité d'utiliser l'opérateur de
résolution de portée.
Un espace
anonyme peut être déclaré dans un autre espace de nommage.
!
Exemple
namespace // espace
anonyme
{int i;} // ::i est unique;
Þ
Portée d'un
identificateur global
·
Un identificateur global est masqué par un
identificateur identique local.
·
Dans le cas
des espaces nommés, l'accès est
réalisé à partir de l'opérateur de
résolution de portée.
·
Il est
impossible d'y accéder dans un espace anonyme.
!
Exemple
#include <iostream.h>
namespace //
ambiguïtés entre espaces à résoudre
{int i = 10;} //
Déclare::i
void f(void)
{i++;
cout
<< " f()::i = " << i << endl;
} //
Utilise::i
namespace A
{namespace
{int i; int j;} // Définitions de
A::i , A::j et initialisation implicite à 0
void g(void)
{cout << "fonction g" <<
endl;
i++; //
résolution de l'ambiguïté entre ::i et A::i
cout
<< " i = " << i << endl;
A::i++;
cout
<< " A::i = " << A::i << endl;
cout
<< " j = " << j << endl;
} //fin
de l'espace de nommage A
} // fin de l'espace de
nommage global
int main(void)
{f();
A::g();
}
// résultat
f()::i =
11
fonction g
i = 1
A::i = 2
j = 0
Lorsque la
dénomination d'un espace de nommage est complexe, ce dernier peut être
accessible à partir d'un alias.
Syntaxe : namespace
identificateur_alias = identificateur_espace_nommage;
Les
identificateurs des alias d'espaces de nommage ne doivent pas entrer en conflit
avec les noms d'autres identificateurs du même espace de nommage, quelle que
soit sa portée.
13.3
Déclaration et directive using
Þ
Déclaration
using
La déclaration using permet d'utiliser
l'identificateur d'un objet d'un espace
de nommage sans nécessité ultérieure de spécifier ce dernier.
Þ Syntaxe
using identificateur;
où
identificateur est le chemin complet de l'identificateur à utiliser, avec
dénomination de l'espace de nommage et résolution de portée.
!
Exemple
// déclaration using
namespace A
{int i , j;} // Déclare A::i, A::j.
void f(void)
{using A::i; // A::i est accessible par l'identificateur alias i.
i=1; // équivalent à A::i=1
j=1; // Erreur car l'alias j n'est pas
défini !
return ;
}
·
Les
déclarations using permettent de
déclarer des alias d'identificateurs utilisables comme des déclarations
usuelles.
·
Ils ne
peuvent être déclarés plusieurs fois que lorsque les déclarations multiples
sont autorisées (déclarations de variables ou de fonctions en dehors des
classes).
·
Ils
appartiennent à l'espace dans lequel ils sont définis.
!
Exemple
namespace A //
déclarations using multiples
{int i;
void f(void);
void f(void){}
}
namespace B
{using A::i; //
Déclaration de l'alias B::i, identique à
A::i.
using A::i; //
Légal : double alias de A::i.
using A::f; //
Déclare void B::f(void), fonction alias à A::f
}
int main(void)
{B::f(); //
Appelle A::f.
return 0;
}
L'alias créé par une déclaration using permet de référencer uniquement
les identificateurs visibles à la déclaration.
Si l'espace
concerné par la déclaration using est
étendu après cette dernière, les nouveaux identificateurs identiques à celui de
l'alias ne sont pas pris en compte.
!
Exemple
namespace A //
Extension d'espace par une déclaration using
{void f(int);}
using A::f; //
f est alias de A::f(int).
namespace A
{void f(char); } //
f est toujours alias de A::f(int), pas de A::f(char)
void g()
{f('a'); } //
Appelle A::f(int), même si A::f(char) existe
Þ
Conflit
entre déclarations using et identificateurs locaux
Si plusieurs
déclarations (locales et using)
déclarent des identificateurs identiques, ces derniers doivent tous se
rapporter à un unique objet ou représenter des fonctions surchargées.
Dans le cas contraire,
des ambiguïtés peuvent provoquer des erreurs de compilation. Ce comportement
diffère de celui des directives using qui diffèrent la détection des
erreurs à la première utilisation des identificateurs ambigus.
!
Exemple
namespace A
{int i;
void f(int);
}
void g(void)
{int i; //
Déclaration locale de i.
using A::i; //
Erreur : i est déjà déclaré.
void f(char); //
Déclaration locale de f(char).
using A::f; //
Pas d'erreur, il y a surcharge de f.
return ;
}
13.3.1
Déclaration using
·
Une déclaration using peut être utilisée dans la définition de membre d'une classe.
·
Elle doit
alors se rapporter à une classe de base de sa classe d'utilisation. De plus,
l'identificateur associé doit être accessible
dans la classe de base.
!
Exemple
namespace A
{float f;}
class Base
{int i;
public:
int j;
};
class Derivee :
public Base
{// using A::f; // Illégal : f n'est pas membre de la classe de base
// using Base::i; // Interdit : Base::i est
d'accès privé
public:
using Base::j; // Légal.
};
Le membre j est
un synonyme de Base::j dans la classe Derivee.
Þ
Requalification
des droits
La déclaration using dans les classes dérivées
peut être utilisée pour rétablir des qualifications d'accès, modifiés par un
héritage, à des membres de la classe de base.
La déclaration using doit porter sur une zone de
déclaration de la classe de base où les qualifications d'accès sont qualifiés public.
!
Exemple
class Base
{public:
int i;
int j;
};
class Derivee :
private Base
{public:
using Base::i; // Rétablit
l'accessibilité sur Base::i, qui de private redevient public
protected:
// using Base::i; // Interdit si requalification public préalable
};
Þ
Remarques
Certains
compilateurs interprètent différemment l'accessibilité des membres introduits
avec une déclaration using qui selon
eux permettent de restreindre l'accessibilité des droits et non pas de les
rétablir ce qui implique l'impossibilité de requalifier l'accessibilité à des
données restreintes par une qualification d'héritage. Par conséquent,
l'héritage doit être défini de manière plus permissive, et les accès ajustés au
cas par cas. Bien que cette interprétation soit licite sur le plan sémantique,
les exemples des projets de norme semblent indiquer qu'elle n'est pas correcte.
Quand une
fonction d'une classe de base est introduite dans une classe dérivée à l'aide
d'une déclaration using, et qu'une
fonction de même nom et de même signature est définie dans la classe dérivée,
cette dernière fonction surcharge la fonction de la classe de base. Il n'y a
pas d'ambiguïté dans ce cas.
13.3.2
Directive using
La directive using permet d'utiliser tous
les identificateurs d'un espace de nommage sans nécessité de le spécifier.
Syntaxe
using namespace identificateur_espace_nommage;
!
Exemple
namespace A
{int i; // Déclare A::i.
int j; // Déclare A::j.
}
void f(void)
{using namespace A; // les
identificateurs de A sont accessibles
i=1; // Équivalent à A::i=1.
j=1; // Équivalent à A::j=1.
return ;
}
Les directives using sont valides à partir de la ligne
où elles sont déclarées jusqu'à la fin du bloc de portée courante. Un espace de
nommage étendu après une directive using
permet d'utiliser les identificateurs définis dans l'extension comme ceux qui
sont définis avant cette dernière.
!
Exemple
namespace A
{int i;}
using namespace A; // extension de
l'espace de nommage
namespace A
{int j;}
void f(void)
{i=0; // Initialise A::i.
j=0; // Initialise A::j.
return ;
}
La définition
d'identificateurs d'un espace par une directive using peut provoquer des conflits d'identificateur. Dans ce cas,
aucune erreur n'est signalée sauf si un des identificateurs cause d'un conflit
est utilisé.
!
Exemple
namespace A
{int i; // Définit A::i.
}
namespace B
{int i; // Définit B::i.
using namespace A; // A::i et B::i
sont en conflit. // Cependant, aucune erreur n'apparaît
}
void f(void)
{using namespace B;
i=2; // Erreur : il y a ambiguïté.
return ;
}
Þ
Définitions
·
En langage
C++, une exception représente une
interruption de l'exécution du programme résultant d'un événement spécifique dont le but est l'activation d'un traitement
permettant de rétablir un mode de
fonctionnement correct du programme.
·
En cas
d'erreur, le programme génère une
exception qui en stoppe l'exécution et en transmet le contrôle à un gestionnaire d'exception qui l'attrape.
Þ
Remarques
·
L'utilisation des exceptions simplifie la programmation de la gestion des erreurs car
elle en diffère le traitement, leur prise en compte et celle des cas
particuliers étant réalisée par le(s) gestionnaire(s) d'exception.
·
Une fonction qui détecte une erreur
d'exécution ne peut se terminer normalement ce qui provoque également la
terminaison anormale de la fonction appelante. L'erreur est ainsi transmise, en
chaîne, dans la pile des fonctions appelantes jusqu'à ce qu'elle soit
complètement gérée ou jusqu'à la terminaison correcte du programme.
Þ
Traitement
traditionnel
Dans le langage
C traditionnel, ce mécanisme est implémenté à partir du code de retour de
chaque fonction, retourné à la fin de son exécution, et indiquant si elle s'est
correctement déroulée. Ce dernier est ensuite utilisé par la fonction appelante
pour déterminer le traitement ultérieur.
Cette technique
nécessite de tester les codes de retour de chaque fonction appelée et la
gestion des erreurs devient très lourde. En outre, le traitement des erreurs
est intégré à l'algorithme et peut devenir délicat lorsque qu'il faut traiter
plusieurs valeurs du code de retour.
Certains
programmes déportent le traitement des erreurs à l'extérieur de l'algorithme.
Le code de nettoyage, écrit une seule fois, est exécuté complètement si tout se
déroule correctement.
La solution
précédente rend le programme moins structuré, car toutes les variables doivent
être accessibles depuis le code de traitement des erreurs ce qui nécessite une
portée globale. De plus, le traitement de code d'erreur à valeurs multiples
reste posé.
Þ
Algorithme
de recherche du gestionnaire d'exception approprié
L'utilisation
des exceptions est plus simple que le
traitement classique puisqu'une fonction qui détecte une erreur peut lancer une
exception qui en interrompt
l'exécution et recherche le
gestionnaire approprié.
Cette dernière
suit un parcourt identique à celui utilisé lors de la remontée des
erreurs : la première des fonctions appelantes de la pile contenant
un gestionnaire d'exception approprié
prend le contrôle et effectue le traitement. S'il est complet, le programme
reprend son exécution normale. Dans le cas contraire, le gestionnaire d'exception peut terminer le programme ou
relancer l'exception pour rechercher
dans la pile des fonctions appelantes le prochain gestionnaire d'exception approprié. L'algorithme est
récursif.
Þ
Gestion des
variables automatiques
Le mécanisme des
exceptions du C++ garantit que tous
les objets de classe de mémorisation automatique sont détruits lorsque l'exception qui remonte sort de leur
portée.
Þ
Corollaires
·
Quand les ressources sont encapsulées
dans des classes avec un destructeur, la remontée des exceptions provoque le nettoyage.
·
Les exceptions
peuvent être typées pour
caractériser l'erreur ce qui est équivalent à la gestion traditionnelle des codes
d'erreurs.
·
La programmation est simplifiée la
gestion des erreurs étant prise en charge par le langage.
Les mécanismes
syntaxiques de gestion des exceptions du
C++ sont décrits dans les paragraphes ci‑dessous.
14.3
Génération et traitement d'une exception
Þ
Génération
d'une exception
En langage C++,
la génération d'une exception crée un
objet dont la classe la caractérise
par utilisation de la méthode throw.
Synopsis
throw (objet);
Description
objet est d'un type caractéristique de l'exception.
Toute exception doit être traitée par la
procédure de traitement correspondante dont la portée est définie par une
zone de code protégée des erreurs
d'exécution.
Le bloc d'instructions
la constituant est introduit avec la méthode try et est délimité par des accolades ouvrantes et
fermantes.
Syntaxe
try // délimitation d'une zone protégée.
{/* Code
susceptible de générer des exceptions */ }
·
Tout gestionnaire d'exception doit suivre le bloc try
associé.
·
Il est introduit par la méthode catch.
Syntaxe
catch (type [&][temp])
{/* Traitement de
l'exception associée à la classe */ }
Þ
Gestion des
exceptions et constructeur copie
Les objets de
classe de mémorisation automatique définis dans le bloc try et l'objet construit pour générer une exception étant détruit quand une exception provoque la sortie du bloc, le compilateur en effectue
préalablement une copie pour le transférer au premier bloc catch susceptible de le recevoir ce qui peut nécessiter la définition d'un constructeur copie.
Þ
Transmission
par valeur et par référence
·
La méthode catch peut transmettre ses arguments par valeur ou par référence.
·
L'utilisation d'une référence évite une
nouvelle copie de l'objet généré par l'exception.
Les modifications effectuées alors sur ce paramètre sont visibles dans les blocs catch des fonctions appelantes ou de portée
supérieure, quand l'exception est relancée après traitement.
Þ
Liste de
gestionnaires d'exception
·
Plusieurs gestionnaires d'exceptions peuvent être définis.
·
Chacun traite les exceptions générées depuis le bloc try dont l'objet est du type indiquée par son argument.
·
Il n'est pas obligatoire de spécifier un
identificateur à l'objet (temp) dans l'expression catch sauf pour la transmission d'informations sur la nature de
l'erreur.
Þ Gestionnaire universel
·
Le gestionnaire
d'exceptions universel peut gérer tous types d'exception.
à
Il est
décrit par trois points de suspension dans sa clause catch.
à
Il est
alors impossible de spécifier une variable associée à l'exception son type étant indéfini.
! Exemple
#include <iostream.h> //
utilisation des exceptions
class erreur // exception associée à l'objet erreur
{public:
int cause; // Entier spécifiant
la cause de l'exception
erreur(int c) : cause(c) {}
erreur(const erreur &source) : cause(source.cause) {}// constructeur
copie
};
class other {}; //
Objet correspondant à toute autre exception
int main(void)
{int i; //
type de l'exception à générer.
cout << "Tapez 0 pour générer une exception Erreur, 1 pour une Entière :";
cin >> i; //
Génération d'une exception
cout << endl;
try // bloc de prise en charge des exceptions
{switch (i)
{case 0: {erreur a(0); throw (a);}
// génération de l'objet (ici, de classe erreur) qui interrompt le code.
case 1: {int a=1; throw (a);} // exception de type entier.
default: {other c; throw (c);} // c créé
(exception other) puis lancé
}
} //
fin du bloc try.
// blocs de réception
catch (erreur &tmp)
{cout << "Erreur erreur ! (cause " << tmp.cause
<< ")" << endl;}
catch (int tmp) //
traitement de l'exception int
{cout << "Erreur int ! (cause " << tmp <<
")" << endl;}
catch (...) //
traitement des autres exceptions
{cout << "Exception inattendue
!" << endl; } //
On ne peut pas récupérer l'objet ici.
return 0;
}
14.4
Remontée des exceptions
Þ Relance d'une exception
·
La fonction de traitement des erreurs
résultant d'une génération d'exception
doit rétablir un état cohérent des données sur lesquelles elle opère.
·
Elle libère les ressources non
encapsulées dans des objets de classe de mémorisation automatique (fichiers ouverts, connexions réseau, etc.).
·
Elle peut ensuite relancer l'exception
(dont le parcours s'arrête dès le traitement effectif de l'erreur) pour
l'exécution d'un traitement ultérieur par la fonction appelante.
·
Une exception
différente de celle qui a été reçue peut être générée comme dans le cas où
le traitement de l'erreur provoquerait lui-même une erreur.
·
La méthode throw relance l'exception en
cours de traitement.
Syntaxe
throw ;
Description
L'exception relancée a comme argument
l'objet construit à la précédente génération d'exception.
Þ
Gestion des
erreurs dans un bloc try
·
L'absence
du bloc catch associé à la classe
d'une exception d'un bloc try provoque une erreur d'exécution qui
appelle la méthode std::terminate
qui, par défaut, appelle la fonction abort
de la bibliothèque C. Cette dernière génère une faute d'exécution, ne libère
pas les ressources allouées, et peut provoquer des pertes de données.
·
La méthode std::set_terminate permet de masquer cet
appel.
Synopsis
set_terminate(void(*)(void));
!
Exemple
// Installation
d'un gestionnaire d'exception avec
set_terminate
#include
<iostream.h>
#include
<exception>
using namespace
std;
void
mon_gestionnaire(void)
{cout <<
"Exception non gérée reçue
!" << endl;
cout <<
"Je termine le programme proprement..."<< endl;
exit(-1);
}
int
lance_exception(void)
{throw 2;}
int main(void)
{set_terminate(&mon_gestionnaire);
try {lance_exception();}
catch (double d) {cout << "Exception de type double reçue : " <<d << endl;}
return 0;
}
14.5
Liste des exceptions autorisées
pour une fonction
·
La méthode throw spécifie la liste des exceptions
qu'une fonction peut lancer, après son en-tête.
·
Ses arguments définissent la liste des
types d'exceptions autorisées.
!
Exemple
int fonction_sensible(void)
throw (int, double, erreur) // exceptions d'un des types int, double ou erreur.
{/* corps de la fonction sensible */}
·
Une exception différente provoque une erreur d'exécution qui génère l'appel de la méthode std::unexpected, dont le comportement par défaut (terminaison
impropre du programme) est similaire à celui de la méthode std::terminate.
·
Ce
dernier peut être modifié par le masquage de la fonction appelée par
défaut par la méthode std::set_unexpected, dont
l'argument est un pointeur sur la procédure de traitement d'erreur adéquate.
·
Une exception différente peut être relancée par la fonction de traitement
d'erreur. Si cette dernière est
dans la liste des exceptions autorisées,
le programme reprend son cours normal à partir du gestionnaire
correspondant qui peut également terminer
le programme en générant une exception de type std::bad_exception, déclarée comme suit dans le fichier en-tête
correspondant :
class bad_exception : public exception
{public:
bad_exception(void) throw();
bad_exception(const bad_exception &) throw();
bad_exception &operator=(const bad_exception &) throw();
virtual ~bad_exception(void) throw();
virtual const char *what(void) const
throw();
};
·
Le gestionnaire des exceptions non autorisées peut terminer l'exécution du programme
en appelant la méthode std::terminate.
!
Exemple
// Gestion de la liste des
exceptions autorisées
#include <iostream>
#include <exception>
using namespace std;
void mon_gestionnaire(void)
{cout << "exception illégale lancée." << endl;
cout << "Relance d'une
exception de type int." <<
endl;
throw
2;
}
int f(void)
throw (int)
{throw
"5.35";}
int main(void)
{set_unexpected(&mon_gestionnaire);
try
{f();}
catch
(int i)
{cout << "Exception de type int reçue : " << i
<< endl;}
return 0;
}
·
La
génération d'une exception nécessitant
la construction d'un objet typé la
caractérisant, ce dernier contient des informations typées sur la nature des erreurs. Il est donc licite de lancer une exception dans un constructeur. C'est
même la solution à adopter pour
traiter une erreur de construction d'un objet les constructeurs n'ayant pas de
valeur de retour.
·
La
génération d'une exception par un
constructeur interrompt la construction de l'objet donc l'appel de son
destructeur, d'où la nécessité d'intégrer la destruction des objets
partiellement initialisés suite à son lancement.
·
Cette règle
est valide pour des objets alloués dynamiquement, le comportement de
l'opérateur delete étant modifié
quand l'exception est générée dans un
constructeur.
Þ
Syntaxe
·
Un bloc try est intégré au corps du constructeur lui permettant de gérer le lancement d'exception.
·
Les blocs catch suivent sa définition et libèrent
les ressources allouées par le constructeur préalablement au lancement de l'exception.
Þ
Règles
d'utilisation
·
L'exception doit être captée par le programme qui a provoqué la création de l'objet.
·
Un
constructeur constitué d'un bloc catch
puis d'un bloc try provoque la
relance de l'exception, le bloc catch associé détruisant les objets partiellement construits.
·
Ce
traitement est différent de celui d'un bloc catch
classique où les exceptions ne
sont pas relancées après traitement sauf utilisation explicite de la méthode throw. Un programme déclarant des objets
globaux dont le constructeur peut lancer une exception à leur initialisation risque de mal se terminer quand
aucun gestionnaire d'exception ne
peut la capter lors de la relance par la méthode catch.
·
Lorsqu'un
objet est construit par une allocation dynamique, l'opérateur delete procède implicitement à sa désallocation.
Son appel explicite lors du traitement de l'exception
est donc inutile.
! Exemple
La création
dynamique d'un objet A provoque une erreur d'initialisation et la génération
d'une exception, traitée dans le bloc catch qui suit la définition du constructeur. L'opérateur delete est appelé explicitement et le
destructeur de A jamais.
#include
<iostream>
#include
<stdlib.h>
using namespace
std;
class A
{char *pBuffer;
int *pData;
public:
A() throw (int);
~A()
{cout <<
"A::~A()" << endl;}
static void *operator
new(size_t taille)
{cout <<
"new()" << endl; return
malloc(taille);}
static void
operator delete(void *p)
{cout <<
"delete" << endl; free(p);}
};
// Constructeur
susceptible de lancer une exception :
A::A() throw (int)
try // bloc try
{pBuffer = NULL;
pData = NULL;
cout <<
"Début du constructeur" << endl;
pBuffer = new
char[256];
cout <<
"Lancement de l'exception" << endl;
throw 2; // Code inaccessible :
pData = new int;
}
catch (int) // bloc catch
{cout <<
"Je fais le ménage..." << endl;
delete[] pBuffer;
delete pData;
}
int main(void)
{try
{A *a = new A;}
catch (...)
{cout <<
"Aïe, même pas mal !" << endl;}
return 0;
}
Lorsqu'il y a un défaut de mémoire, les
opérateurs new et new[] peuvent se comporter de deux manières :
·
retour d'un pointeur nul.
·
appel d'un gestionnaire d'erreur. Trois
cas se présentent :
à
correction de l'erreur d'allocation et
retour à l'opérateur new qui réitère
sa requête.
à
aucune action : dans ce cas,
l'opérateur new achève le programme
ou génère l'exception std::bad_alloc, qui retourne à la fonction ayant appelée
l'opérateur new.
à
le gestionnaire d'erreur est masqué par
la fonction std::set_new_handler,
déclarée dans le fichier en-tête new,
qui retourne l'adresse du gestionnaire d'erreur précédent.
·
La norme actuelle impose à tous les
compilateurs C++ de lancer une exception en cas de défaut de mémoire lors de
l'appel à l'opérateur new.
·
La
bibliothèque standard C++ définit la liste des exceptions de gestion des erreurs d'exécution dont certaines ont
été présentées plus haut.
·
Les objets exceptions peuvent être des instances
d'une classe dérivée. Ces dernières pouvant être considérées comme des
instances d'une de leurs classes de base, un gestionnaire d'exceptions peut traiter celles d'une classe dérivée par traitement
d'un objet d'une de ses classes de base.
·
Les erreurs
peuvent être classifiées selon une hiérarchie
de classe d'exceptions, l'écriture de traitements génériques utilisant des
objets d'un certain niveau de cette dernière.
! Exemple
// Classification
des exceptions
#include
<iostream>
using namespace
std;
// Classe de base
de toutes les exceptions :
class
ExRuntimeError
{};
// Classe de base
des exceptions pouvant se produire lors de manipulations de fichiers
class ExFileError
: public ExRuntimeError
{};
// Classes des
erreurs de manipulation des fichiers :
class
ExInvalidName : public ExFileError
{};
class ExEndOfFile
: public ExFileError
{};
class ExNoSpace :
public ExFileError
{};
class ExMediumFull
: public ExNoSpace
{};
class
ExFileSizeMaxLimit : public ExNoSpace
{};
// Fonction
faisant un travail quelconque sur un fichier :
void
WriteData(const char *szFileName)
{// Exemple
d'erreur :
if (szFileName ==
NULL) throw ExInvalidName();
else
{// Traitement de
la fonction
// etc.
// Lancement d'une exception :
throw ExMediumFull();
}
}
void Save(const
char *szFileName)
{try {WriteData(szFileName);}
// Traitement d'un
erreur spécifique :
catch (ExInvalidName &)
{cout <<
"Impossible de faire la sauvegarde" << endl;}
// Traitement de
toutes les autres erreurs en groupe :
catch (ExFileError &)
{cout <<
"Erreur d'entrée / sortie" << endl;}
}
int main(void)
{Save(NULL);
Save("data.dat");
return 0;
}
Þ
Règles de
gestion de la liste des exceptions
·
La liste
des exceptions autorisées dans une
fonction n'étant
pas explicitée dans sa signature, elle
n'apparaît pas dans celle des surcharges.
·
La liste
des exceptions doit être définie après les déclarations
des méthodes qualifiées const.
·
La liste
des exceptions doit être placée avant l'affectation =0
dans les déclarations des fonctions
virtuelles pures.
·
Les exceptions n'étant pas gérées par le mécanisme standard de gestion des erreurs des langages C et C++,
les tests de validité d'une opération doivent être explicites. Le lancement d'une exception de report du traitement en cas d'échec peut être
nécessaire.
·
La norme
spécifie que les exceptions générées
par la machine hôte du programme ne sont pas obligatoirement portables dans les
autres implémentations.
Þ
Retour sur
le mot clé try
Quand une classe fille hérite d'une ou plusieurs
classes mère, l'appel des constructeurs des classes de base doit être effectué
au travers de la méthode try et de la
première accolade. Rappelons que les constructeurs des classes de base peuvent également
lancer des exceptions.
Syntaxe
Classe::Classe
try : Base(paramètres) [, Base(paramètres) [...]]
{}
catch ...
Þ
Position du
problème
·
Le type effectif d'un objet peut être
ambigu dans un héritage : doit‑il être considéré comme objet de
sa classe dérivée ou de sa classe de base.
·
Les objets polymorphiques intégrent des
informations sur leur type dynamique
utilisées lors de l'appel des méthodes virtuelles. Cette propriété permet
l'identification de ce dernier et la vérification
de la validité des transtypages lors de dérivations.
15.1
Identification dynamique d’un type
15.1.1
L'opérateur typeid
·
L'opérateur
typeid permet d'accéder aux
informations de type d'une expression.
·
Il retourne
une référence sur un objet constant de la classe prédéfinie type_info.
Syntaxe
typeid(expression)
où expression
est l'expression dont le type dynamique
est à déterminer.
Þ
Type non
polymorphique
L'objet retourné
par l'opérateur caractérise le type statique de l'expression même si cette
dernière représente un objet dérivé d'ordre supérieur.
Þ
Type
polymorphique
Lorsqu'on opère
sur un objet avec un pointeur ou une référence sur une classe de base de sa
classe effective, son type effectif est déterminé à partir d'une détermination dynamique, et l'objet de
classe type_info renvoyé le décrit,
même si l'expression représente un objet dérivé d'ordre supérieur.
Þ Exemple
/// Opérateur typeid
#include <iostream.h>
#include <typeinfo>
class Base
{public: virtual ~Base(void){}; };
class Derivee : public Base
{public:
virtual
~Derivee(void){};
};
int main(void)
{Derivee* pd = new Derivee;
Base* pb
= pd;
Base*
pB=new Base;
const type_info &t1=typeid(*pd); // t1 qualifie le type de *pd.
const
type_info &t2=typeid(*pb); // t2
qualifie le type de *pb.
cout
<< t1.name() << endl << t2.name() << endl;
cout
<< typeid(*pb).before(typeid(*pd)) << endl;
cout
<< typeid(*pB).before(typeid(*pd)) << endl;
return 0 ;
}
// résultat
Derivee
Derivee
0
1
Þ
Remarques
·
Les objets
t1 et t2 qualifient le type Derivee et sont identiques.
·
Le type dynamique décrit par t2 contient les
informations du type effectif de
l'objet pointé par pb.
·
Les
informations de type effectif sont différentes sur un pointeur et sur un
pointeur déréférencé.
·
La classe type_info est définie dans l'espace de
nommage std dans l'en-tête typeinfo.
·
Quand le
pointeur déréférencé est nul, l'opérateur typeid
génère une exception dont l'objet est
une instance de la classe bad_typeid,
définie comme suit dans l'en-tête typeinfo :
class bad_typeid : public logic
{public:
bad_typeid(const
char * what_arg) : logic(what_arg)
{return
;}
void
raise(void)
{handle_raise(); throw *this;}
};
15.1.2
La classe type_info
Les informations
de type sont enregistrées dans des objets de la classe type_info, prédéfinie
dans l'en-tête typeinfo de la manière
suivante :
class type_info
{public:
virtual
~type_info();
bool
operator==(const type_info &rhs) const;
bool
operator!=(const type_info &rhs) const;
bool
before(const type_info &rhs) const;
const
char *name() const;
private:
type_info(const
type_info &rhs);
type_info
&operator=(const type_info &rhs);
};
·
Les objets
de la classe type_info ne peuvent
être copiés, les opérateurs d'affectation et le constructeur copie étant
qualifiés private.
·
La méthode typeid génère un objet de la classe type_info.
·
Les
opérateurs de comparaison testent l'égalité de deux objets type_info donc peuvent comparer les types de deux expressions.
·
Les
informations sur les types des objets de la classe type_info sont codées sous forme de chaînes de caractères dont une
représente le type, accessible par la méthode name, et une autre sous un format pour traitement, variable selon
l'implémentation.
·
La méthode before permet de déterminer un ordre
hiérarchique des types d'une hiérarchie de classes. Son utilisation est
toutefois délicate, l'ordre entre les différentes classes pouvant dépendre de
l'implémentation.
15.2
Transtypages en langage C++
Þ
Rappels
·
Les règles
de dérivation garantissent, en cas d’utilisation d’un pointeur sur une classe,
l'existence et l’appartenance de l’objet à la classe de base du pointeur ce qui
permet de convertir un pointeur sur un objet en un pointeur sur un objet
dérivé.
·
Il est
interdit d’autre part d'utiliser un pointeur sur un objet de la classe de base
pour initialiser un pointeur sur un objet d'une classe dérivée, même si cette
opération peut s'effectuer correctement, la grammaire du langage imposant un
transtypage explicite.
Þ
Opérateurs
de transtypage
Le langage C++
fournit un jeu d'opérateurs de transtypage garantissant ces
règles : opérateurs de transtypage
dynamique, transtypage statique, transtypage de constance et transtypage de réinterprétation des données.
15.2.2
Transtypage dynamique
Þ
Définition
Le transtypage dynamique permet de
convertir une expression en un pointeur, une référence d'une classe, un pointeur
sur un objet void.
Il est
implémenté par l'opérateur dynamic_cast.
Syntaxe
dynamic_cast<type>(expression)
où type désigne le type cible du
transtypage, et expression
l'expression à convertir.
Þ
Règles
d'utilisation
·
L'opérateur
dynamic_cast contrôle la validité du
transtypage.
·
Il ne
supprime pas les qualifications de
constance, réservées à l'opérateur const_cast.
·
Il permet
de qualifier constant un type complexe comme les conversions implicites du
langage l'autorisent.
·
Il ne peut
pas opérer sur les types de base du langage, sauf sur le type void *.
·
Le
transtypage d'un pointeur ou d'une référence d'une classe dérivée vers une
classe de base est effectué sans vérification
dynamique, cette opération étant
toujours valide.
!
Exemple
Les
instructions :
B *pb; //
La classe B est fille de la classe A
A *pA=dynamic_cast<A
*>(pB);
sont équivalentes aux instructions :
B *pb;
A *pA=pB;
·
Tout autre
opération de transtypage doit être effectuée à partir d'un type polymorphique
·
Le
transtypage d'un pointeur d'un objet vers un pointeur de type void retourne l'adresse de l'objet le
plus dérivé.
·
Le
transtypage d'un pointeur ou d'une référence d'un objet dérivé vers un pointeur ou une référence
d'un objet dérivé d'ordre supérieur
est effectué après vérification du type dynamique.
à
Le pointeur
nul est retourné si le type cible est un pointeur.
à
Une
exception de type bad_cast (Cf ci‑dessous)
est générée quand l'expression caractérise un objet ou une référence.
·
Lors d'un
transtypage, aucune ambiguïté n'est
autorisée pendant la recherche dynamique du type dans les héritages
multiples même si la coexistence de plusieurs objets de même type est possible.
Cette restriction mise à part, l'opérateur dynamic_cast
peut parcourir une hiérarchie de classe aussi bien verticalement (conversion d'un pointeur d'objet dérivé vers le
pointeur sur l'objet dérivé d'ordre supérieur) que transversalement (conversion d'un pointeur d'objet vers un pointeur
d'un autre objet frère dans la hiérarchie de classes).
·
L'opérateur
dynamic_cast peut convertir un
pointeur d'une classe de base virtuelle vers une de ses classes filles ce qui
est interdit aux opérateurs de transtypage du C.
·
L'opérateur
dynamic_cast ne permet pas d’accéder
aux objets inaccessibles de la classe de base.
!
Exemple
// Opérateur dynamic_cast
struct A
{virtual void f(void) {return ;};
};
struct B : public virtual A
{};
struct C : public virtual A, public B
{};
struct D
{virtual void g(void) {return ;};
};
struct E : public virtual B, public C,
public D
{};
int main(void)
{E
e; // e contient deux
objets dérivés de la classe B, un objet dérivé de la classe A
//
Les objets dérivés des classes C et D sont frères.
A *pA=&e; // Dérivation légale : l'objet dérivé de classe A est unique.
// C *pC=(C *) pA; // Illégal car A classe de base virtuelle (erreur de
compilation).
C *pC=dynamic_cast<C *>(pA); // Légal. Transtypage dynamique vertical
D *pD=dynamic_cast<D *>(pC); // Légal. Transtypage dynamique horizontal
B *pB=dynamic_cast<B *>(pA); //
Légal
return 0 ;
}
Þ
La classe bad_cast
La classe bad_cast
est définie comme suit dans l'en-tête typeinfo :
class bad_cast : public exception
{public:
bad_cast(void) throw();
bad_cast(const bad_cast&) throw();
bad_cast
&operator=(const bad_cast&) throw();
virtual
~bad_cast(void) throw();
virtual
const char* what(void) const throw();
};
15.2.3
Transtypage statique
Syntaxe
L'opérateur static_cast effectue le transtypage statique d’objet non polymorphique.
static_cast<type>(expression)
où type et expression ont les mêmes significations respectives que pour
l'opérateur dynamic_cast.
Synopsis
type_temporaire(expression);
Description
·
Construction
d'un objet temporaire du type indiqué et initialisation type de la valeur
retournée par l'opérateur.
·
Contrairement
à l'opérateur dynamic_cast,
l'opérateur static_cast permet
d'effectuer les conversions entre des types autres que les classes définies par
l'utilisateur, sans vérification de la
validité de la conversion.
·
Quand
l'expression est invalide, le
transtypage ne peut être effectué qu'entre classe dérivée et classe de base.
·
Enfin,
toute valeur d'une expression peut être supprimée par conversion vers le type void.
·
Un objet
peut être requalifié avec des qualifications de constance et de volatilité.
·
L'opérateur
static_cast n'autorise pas la suppression des qualifications de constance.
La suppression
des attributs de constance et de volatilité
peut être réalisée par l'opérateur const_cast
dont la syntaxe d'utilisation est identique à celle des opérateurs dynamic_cast et static_cast.
const_cast<type>(expression)
Synopsis
·
L'opérateur
const_cast opère surtout avec des références et des pointeurs.
·
Il effectue
des transtypages dont le type cible à moins de contraintes que le type source
qualifié const ou volatile.
·
Il
n’effectue pas les conversions que font les autres opérateurs de transtypage
comme convertir un flottant en entier.
·
Lorsqu'il
opère sur une référence, l'opérateur contrôle la légalité du transtypage en
convertissant les références en pointeurs et en vérifiant qu'il n'implique que
des attributs const et volatile.
·
Il ne
convertit pas de pointeurs sur des
fonctions.
L'opérateur de
transtypage le plus délicat est reinterpret_cast.
Sa syntaxe est identique à celle des autres opérateurs de transtypage dynamic_cast, static_cast et const_cast.
Syntaxe
reinterpret_cast<type>(expression)
Synopsis
Il permet de
réinterpréter les données d'un type en un autre type, sans vérification de la
validité de l'opération. Ainsi, les instructions :
double f=2.3;
int i=1, m;
int & j=&m;
j=reinterpret_cast<int &>(i);
j++;
sont
équivalentes aux instructions :
double f=2.3;
int i=1;
*((int *) &f)=i;
L'opérateur reinterpret_cast doit respecter les
règles suivantes :
·
il ne
permet pas la suppression des qualificatifs de constance et de volatilité.
·
il doit
être symétrique (la réinterprétation d'un type T1 comme type T2, puis la
réinterprétation du résultat en type T1 doit redonner l'objet initial).
On souhaite écrire un programme permettant
d'initialiser des tableaux d'entiers.
1°) Définir une classe TableauEntier avec deux
données membres représentant l'adresse et la taille en octet du tableau.
2°) Définir les différents constructeurs
nécessaires :
·
constructeur par défaut,
·
constructeur pour initialiser un tableau
d'une taille donnée,
·
constructeur d'initialisation d'un
tableau à partir d'un autre. Il faudra surcharger les opérateurs d'affectation
et crochet.
On définira une procédure init, appelée par les différents constructeurs pour initialiser le
tableau.
3°) Ne pas oublier le destructeur.
4°) Intégrer dans la classe une fonction inline permettant de connaître la taille
du tableau.
#include
<iostream.h>
#include
<assert.h>
const int TailleDef = 100; // taille par défaut
//
les classes
class
TableauEntier
{public:
// constructeurs d'initialisation des
tableaux
// constructeur par défaut (tableau non
dimensionné)
TableauEntier(int Taille = TailleDef);
// constructeur d'un tableau dimensionné
TableauEntier(const int*, int);
// constructeur d'un tableau à partir d'un
autre
TableauEntier(const TableauEntier &);
// destructeur
~TableauEntier(){delete [] adresse; }
// surcharge de l'opérateur d'affectation
TableauEntier& operator=(const TableauEntier&);
// surcharge de l'opérateur []
int& operator[] (int);
// fonction inline
int getSize() {return Taille;}
protected:
void
init (const int*, int);
//
données internes
int
Taille; // taille du tableau
int
*adresse; // adresse du tableau
};
//
constructeur par défaut d'un tableau de dimension non définie
TableauEntier::TableauEntier(int
TailleDef)
//
allocation d'un tableau d'entier de Taille composantes (taille par défaut)
{init (0,TailleDef);}
//
constructeur d'un tableau dont la dimension est fournie
TableauEntier::TableauEntier(const int *tableau, int Taille)
{init(tableau,Taille);}
//
contructeur d'initialisation d'un tableau à partir d'un autre
TableauEntier::TableauEntier(const TableauEntier &A)
{init(A.adresse,
A.Taille);}
//
procédure init
void TableauEntier::init(const int * tableau, int TailleDef)
{adresse
= new int[Taille=TailleDef];
assert(adresse !=0); // traitement des exceptions
for(int ix=0; ix < Taille; ++ix)
adresse[ix]=(tableau !=0) ? tableau[ix] : 0;
}
TableauEntier&
TableauEntier::operator=(const TableauEntier&A)
{if
(this== &A) return *this; //
tableau lui même
delete
adresse;
init(A.adresse, A.Taille);
return *this;
}
inline
int& TableauEntier::operator[] (int index)
{return(adresse[index]);}
void
swap(TableauEntier & tableau, int i, int j)
{int
tmp =tableau[i];
tableau[i]=tableau[j];
tableau[j]=tmp;
}
int
main()
{int
maTaille = 1024;
TableauEntier
Tableau, A(maTaille);
TableauEntier
*pA=&Tableau;
TableauEntier
A2=Tableau;
TableauEntier
A3;
cout
<< "Tableau.getSize() = " << Tableau.getSize() <<
"\n";
cout
<< "A.getSize() = " << A.getSize() <<
"\n";
cout
<< "(*pA).getSize() = " << (*pA).getSize() <<
"\n";
cout
<< "A2.getSize() = " << A2.getSize() <<
"\n";
A3=Tableau;
cout
<< "A3.getSize() = " << A3.getSize() <<
"\n";
for(int
i=0; i< maTaille;i++) Tableau[i]=i;
cout
<< Tableau[1] << "\t" << Tableau[Tableau.getSize()]
<< "\n";
swap(Tableau,
1, Tableau.getSize());
cout
<< Tableau[1] << "\t" << Tableau[Tableau.getSize()]
<< "\n";
return
1;
}
// résultat
Tableau.getSize()
= 100
A.getSize()
= 100
(*pA).getSize()
= 100
A2.getSize()
= 100
A3.getSize()
= 100
1 100
100 1
Un objet postal est décrit par son poids, la
valeur de l'affranchissement, et son type (pli ordinaire ou recommandé).
Si l'objet est recommandé, il faut indiquer sa
valeur déclarée.
1°) Construire la classe ObjetPostal
avec les données membres poids, valeur,
recommande.
2°) Définir les méthodes aValeurDeclaree,
poidsObjet, recommander permettant
d'accéder aux données membres précédentes.
3°) Définir un constructeur d'un objet
postal.
// Fichier SacPostal.C
#include <iostream.h>
class ObjetPostal
{private:
int poids, valeur, recommande;
public:
int tarif;
int aValeurDeclaree() {return (valeur >0);}
int poidsObjet() {return poids;}
void recommander() {recommande =1 ;}
// constructeurs
ObjetPostal(int);
ObjetPostal();
};
// constructeur par défaut
ObjetPostal::ObjetPostal()
{poids = 20 ; valeur =0; recommande =0; }
// constructeur explicite
ObjetPostal::ObjetPostal(int p)
{poids = p ; valeur =0; recommande =0;}
int main()
{ObjetPostal x; //
appel du constructeur par défaut pour l'instance x
cout << "x.poidsObjet() = "
<< x.poidsObjet() << endl ;
ObjetPostal y= 160; // appel du constructeur explicite
ObjetPostal z(160); // identique au précédent
cout << "y.poidsObjet() = "
<< y.poidsObjet() << endl ;
cout << "z.poidsObjet() = "
<< z.poidsObjet() << endl ;
return 1;
}
// résultat
x.poidsObjet() = 20
y.poidsObjet() = 160
z.poidsObjet() = 160
La capacité d'un sac postal lui permet de
contenir un certains nombre d'instances de la classe ObjetPostal.
Définir la classe SacPostal
et les méthodes associées (constructeurs et destructeurs d'un sac).
#include "SacPostal.C"
SacPostal::SacPostal(int cap) // constructeur
{capacite =cap; nbelts = 0; // sac vide
sac = new
ObjetPostal[cap]; // allocation d'un
tableau d'instances
}
SacPostal::~SacPostal() // destructeur
{delete
[capacite] sac;} // restitution
de l'espace mémoire utilisé par le tableau
int main()
{ObjetPostal x;
ObjetPostal y= 160;
SacPostal courrier(250); // 250 objets postaux dans le sac
cout << "courrier.nbelts = "
<< courrier.nbelts << "\tcourrier.capacité = " <<
courrier.capacite <<endl ;
}
// resultat
courrier.nbelts = 0 courrier.capacité = 250;
Analyser le programme suivant.
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
class Produit {private:
char
* nom;
float
prix;
char
* alloue(int LgrMem)
{//
fonction membre privée d'allocation pour la donnée membre nom
char
* Ptr = new char[LgrMem];
if
(Ptr == NULL) {cerr << "plus de place en mémoire" << endl
; exit (1); }
return
Ptr;
}
public:
Produit(
const char * Nom, float Valeur) // un constructeur
{nom
= alloue(strlen(Nom)+1);
strcpy
(nom, Nom);
prix
= Valeur;
}
Produit() // constructeur par défaut
{nom
= alloue(1);
nom[0]
= '\0'; // garantit le bon fonctionnement de la fonction AfficheToi
prix
= 0;
cout
<< "appel du constructeur par défaut avec prix = " <<
prix << endl ;
}
~Produit()
{delete [] nom;} // destructeur d'un
tableau d'instances
void ChangeNom(const char * NouveauNom) //
modification du nom
{delete [] nom;
nom=alloue(strlen(NouveauNom+1));
strcpy(nom,
NouveauNom);
}
void AfficheToi() const
{cout
<< "Produit " <<
nom << " de prix " << prix << " FF" << endl ; }
};
int main(void
)
{ Produit
P1("SAVON",7.5);
Produit
* Ptr = new Produit; // un objet dynamique local à main()
Ptr->ChangeNom("BROSSE
A DENTS");
Ptr->AfficheToi();
{Produit
P2("LIVRE DE POCHE 1 VOL",25); //
P2 local au bloc
P2.AfficheToi();
P2.ChangeNom("POCHE SIMPLE");
P2.AfficheToi();
}
// L'instance P2 est détruite à la sortie du bloc
Ptr->AfficheToi(); // on affiche à nouveau Ptr
delete Ptr; // destruction de l'objet dynamique pointé par Ptr
cout
<< "Allocation d'un tableau de 3 instances " << endl ;
Ptr
= new Produit[3]; // nouvelle allocation d'un tableau de 3
instances
for (int
k=0; k<3; k++)
{cout
<< "k= " << k << " : ";
Ptr[k].ChangeNom( "K");
Ptr[k].AfficheToi();
}
delete Ptr; // destruction du tableau de trois instances
P1.ChangeNom("SAVON
MENAGER");
P1.AfficheToi();
return(1);
}
// résultat
appel du constructeur par défaut avec prix = 0
Produit BROSSE A DENTS de prix 0 FF
Produit LIVRE DE POCHE 1 VOL de prix 25 FF
Produit POCHE SIMPLE de prix 25 FF
Produit BROSSE A DENTS de prix 0 FF
Allocation d'un tableau de 3 instances
appel du constructeur par défaut avec prix = 0
appel du constructeur par défaut avec prix = 0
appel du constructeur par défaut avec prix = 0
K= 0 : Produit K de prix 0 FF
K= 1 : Produit K de prix 0 FF
K= 2 : Produit K de prix 0 FF
Produit SAVON MENAGER de prix 7.5 FF
Reprendre l'implémentation d'une pile
en définissant la classe PILE avec ses données membres et ses méthodes. Il
faudra
·
définir des constructeurs et des
destructeurs,
·
définir un jeu de test.
Þ Contenu du fichier pile.h
class PILE {
int taille;
int* base;
int* top;
public:
PILE(int);
int vide(void);
int push(int);
int
pop(void);
void effacer(void);
~PILE(void);
};
Þ Contenu du fichier pile.C
PILE::PILE(int
t) //constructeur
{top=base=new int[taille=t]; }
int
PILE::vide(void)
{return
top==base; }
int
PILE::push(int e)
{if
((top-base)==taille) return 0;
*top++
=e;
return
1;
}
int
PILE::pop(void)
{if
(top != base) return *--top; }
void PILE::effacer(void)
{delete base;
this->top
= this->base = 0;
this->taille
= 0;
}
PILE::~PILE(void) {effacer();}
Þ Programme d'essai de la class
PILE
#include
<iostream.h>
#include
"pile.h"
PILE
pile(10); // initialisation de la pile à
exécuter avant la fonction main()
int main(void)
{int
i=0;
while
(pile.push(i++));
while
(!pile.vide()) cout << pile.pop() << endl ;
}
//
destruction de pile en fin de programme
Analyser le programme suivant :
Þ fichier pile.h
class PILE {
private:
int taille;
int* base;
int* top;
public:
void init(int);
int push(int);
int pop(void);
int vide(void);
void effacer(void);
};
Þ Fichier pile.c
#include <iostream.h>
#include "pile.h"
// résolution de la visibilité
void PILE::init(int t)
{top=base=new
int[taille=t]; }
int PILE::vide(void)
{return top==base;}
int PILE::push(int e)
{// référence implicite à l'objet
if ((top-base)==taille) return 0;
*top++ =e;
return 1;
}
int PILE::pop(void)
{if (top!=base) return *--top;}
void PILE::effacer(void)
{delete
base;
// référence explicite à l'objet
this->top = this->base = 0;
this->taille = 0;
}
Þ Programme d'essai de la class
PILE
int main(void)
{int i=0;
PILE pile;
/* initialisation */
pile.init(10); // appel d'une méthode
/* utilisation */
while (pile.push(i++));
while (!pile.vide()) cout << pile.pop()
<< endl ;
/* destruction */
pile.effacer();
return 1;
}
// résultat
9
8
7
6
5
4
3
2
1
0
Þ Avantages et inconvénients
++ encapsulation
des données : l'utilisateur ne peut modifier la représentation
d'un objet pile qu'en utilisant l'interface. La partie privée est réservée à le
développeur, la partie publique est accessible à tous.
+ abstraction
des données : l'utilisateur peut accéder à la représentation des
données mais il ne peut pas la modifier.
++ simplicité
de l'écriture : pas de pointeurs explicites. La définition d'un
type en C++ est aussi simple que celle d'un objet en C.
++ efficacité
à l'exécution garantie par le
langage (appels optimisés et pointeurs implicites).
+ gestion dynamique de l'allocation
mémoire.
++ le type pile
est défini ce qui permet d'instancier autant d'objets pile que nécessaire.
Þ Fichier pile.h
class PILE {
void* adr;
public:
PILE(int);
int vide(void);
int push(int);
int pop(void);
void effacer(void);
~PILE(void);
};
Þ Fichier pile.C
class pile {
int taille;
int* base;
int* top;
public:
pile(int t=1024) {top=base=new int[taille=t]; }
int vide(void){return
top==base; }
int push(int e)
{if((top-base)==taille) return 0;
*top++= e;return 1;
}
int pop(void)
{if(top!=base) return *--top;}
~pile(void)
{delete base;}
};
#include "pile.h"
typedef pile* adr_pile;
PILE::PILE(int t) {adr=new pile(t);}
int PILE::vide(void)
{return adr_pile(adr)->vide(); }
int PILE::push(int e)
{return adr_pile(adr)->push(e);}
int PILE::pop(void)
{return adr_pile(adr)->pop(); }
PILE::~PILE(void)
{delete
adr_pile(adr); adr=0;}
Þ Essai de la class PILE
#include <iostream.h>
#include "pile.h"
int main()
{int i=0;
PILE pile(10);
while (pile.push(i++));
while (!pile.vide()) cout << pile.pop()
<<endl ;
return 1;
}
Þ Avantages et inconvénients
++ encapsulation des données
++ abstraction des
données : l'utilisateur ne peut pas voir la représentation des
données.
++ simplicité de l'écriture : pas de
pointeurs explicites.
-- efficacité à
l'exécution : passage par des fonctions tampons. Ici, les méthodes de
la classe pile sont inline mais pas
de surcout.
+ occupation mémoire dynamique
++ le type pile est défini => l'utilisateur
peut instancier autant d'objets pile qu'il en veut.
++ on peut changer l'implémentation sans
modifier l'interface.
!
Autre implémentation
// Fichier pile.h
class PILE {
int taille; int* base; int* top;
public:
PILE(int t){top=base=new int[taille=t];}
int vide(void);
int push(int);
int pop(void);
void effacer(void);
~PILE(void)
{effacer();}
inline int PILE::vide(void)
{return top==base; }
inline int PILE::push(int e)
{if ((top-base)==taille) return 0;
*top++ e; return 1; }
inline int PILE::pop(void)
{if (top!=base) return *--top; }
inline void PILE::effacer(void)
{delete
base;
this->top = this->base = 0;
this->taille = 0;
}
#include "iostream.h"
#include "string.h"
const int nbmaxcarac = 25;
const float taux1 = 0.196;
const float taux2 = 0.055;
class C_Produit {
private:
char
nom[nbmaxcarac+1];
float
tauxTVA;
float
prixHT;
public:
void fixenom (char [] );
void PrixHT (float);
void tva (float);
float
prixTTC() const {return prixHT *
(1+tauxTVA);};
char*
Nom() {return nom;};
float
aff_prixHT() const {return prixHT;};
float
taux() const {return tauxTVA;}
C_Produit (char param_nom[] = "toto",
float param_prixHT =10/1.196, float param_tauxtva=.196)
{fixenom (param_nom);
PrixHT (param_prixHT);
tva (param_tauxtva);
}
/*C_Produit (char * param_nom)
{fixenom (param_nom);
tauxTVA=.196;
prixHT=10/1.196;
}
C_Produit()
{fixenom("Produit phare");
tauxTVA=.196;
prixHT=10/1.196;
}*/
};
void C_Produit::fixenom (char * param_nom )
{strncpy(nom, param_nom, nbmaxcarac);
nom[nbmaxcarac] = '\0';
}
void C_Produit::PrixHT (float param_prixHT)
{if ((param_prixHT < 0) | (param_prixHT >
1000))
{cout << "prix errone"
<<endl;
prixHT = 0;}
else
{prixHT = param_prixHT;}
}
void C_Produit::tva (float param_tauxtva)
{tauxTVA = param_tauxtva;
}
main()
{C_Produit P1("lait",2.5,taux2);
C_Produit P2("voiture",60000,taux1);
C_Produit P3("voiture2");
C_Produit P4;
cout << "nom " << P1.Nom()<<" prixHT
"<<P1.aff_prixHT() << " taux "<<
P1.taux() << " prixttc " << P1.prixTTC()<<endl;
cout << "nom " << P2.Nom()<<" prixHT
"<<P2.aff_prixHT() << " taux "<<
P2.taux() << " prixttc " << P2.prixTTC()<<endl;
cout << "nom " << P3.Nom()<<" prixHT
"<<P3.aff_prixHT() << " taux "<<
P3.taux() << " prixttc " << P3.prixTTC()<<endl;
cout << "nom " << P4.Nom()<<" prixHT
"<<P4.aff_prixHT() << " taux "<<
P4.taux() << " prixttc " << P4.prixTTC()<<endl;
}
Cette annexe
indique la priorité des opérateurs du langage C++, dans l'ordre décroissant.
|
Opérateur
|
Désignation
|
|
::
|
résolution de portée
|
|
[]
|
accès aux éléments de tableau
|
|
()
|
appel de fonction
|
|
type()
|
transtypage explicite
|
|
.
|
sélection de membre
|
|
->
|
sélection de membre par déréférencement
|
|
++
|
incrémentation post-fixé
|
|
—
|
décrémentation post-fixé
|
|
new
|
allocation dynamique d'objet
|
|
new[]
|
allocation dynamique de tableaux
|
|
delete
|
destruction d'objet créé dynamiquement
|
|
delete[]
|
destruction de tableaux créés dynamiquement
|
|
++
|
incrémentation préfixé
|
|
—
|
décrémentation préfixé
|
|
*
|
déréférenciation
|
|
&
|
référence
|
|
+
|
plus unaire
|
|
-
|
moins unaire
|
|
!
|
négation logique
|
|
~
|
complément logique
|
|
sizeof
|
taille d'objet ou de type
|
|
typeid
|
identification de type
|
|
(type)
|
transtypage
|
|
const_cast
|
transtypage de constance
|
|
dynamic_cast
|
transtypage dynamique
|
|
reinterpret_cast
|
réinterprétation
|
|
static_cast
|
transtypage statique
|
|
.*
|
sélection de membre par
pointeur sur membre
|
|
->*
|
sélection de membre par
pointeur sur membre par déréférencement
|
|
*
|
multiplication
|
|
/
|
division
|
|
%
|
modulo
|
|
+
|
addition
|
|
-
|
soustraction
|
|
<<
|
décalage à gauche
|
|
>>
|
décalage à droite
|
|
<
|
comparaison (infériorité)
|
|
>
|
comparaison (supériorité)
|
|
<=
|
infériorité ou d'égalité
|
|
>=
|
supériorité ou d'égalité
|
|
==
|
identité logique
|
|
!=
|
différence logique
|
|
&
|
et logique (champ de bits)
|
|
^
|
ou exclusif logique (champ de bits)
|
|
|
|
ou inclusif logique (champ de bits)
|
|
&&
|
et logique
|
|
||
|
ou logique
|
|
?:
|
ternaire
|
|
=
|
affectation
|
|
*=
|
Opérateur composé de multiplication et d'affectation
|
|
/=
|
Opérateur composé de division et d'affectation
|
|
%=
|
Opérateur composé : modulo et d'affectation
|
|
+=
|
Opérateur composé d'addition et d'affectation
|
|
-=
|
Opérateur composé de soustraction et d'affectation
|
|
<<=
|
Opérateur composé de décalage à gauche et d'affectation
|
|
>>=
|
Opérateur composé de décalage à droite et d'affectation
|
|
&=
|
Opérateur composé de et logique et d'affectation
|
|
|=
|
Opérateur composé de ou inclusif logique et d'affectation
|
|
^=
|
Opérateur composé de ou exclusif logique et d'affectation
|
|
,
|
Opérateur virgule
|
Þ Langage C
C as a Second Language For Native Speakers of
Pascal, Müldner and Steele,
Addison-Wesley.
The C Programming Language, Brian W. Kernigham and Dennis M.
Ritchie, Prentice Hall.
Þ Langage C++
L'essentiel du C++, Stanley B. Lippman, Addison-Wesley.
The C++ Programming Language, Bjarne Stroustrup, Addison-Wesley.
Working Paper for Draft Proposed International
Standard for Information Systems — Programming Language C++, ISO.
Þ Bibliothèque C / appels systèmes POSIX et algorithmique
Programmation système en C sous Linux, Christophe Blaess, Eyrolles.
Introduction à l'algorithmique, Thomas Cormen, Charles Leiserson, et
Ronald Rivest, Dunod.
&
&,62
(
(),62
*
*,62
*this,86
.
.*,62
/
//,61
[
[],62
>
->,62
A
abstraction,52
abstraction
des données,16
abstraction
procédurale,16
action,35
adressage
symbolique,18
adresse,92
affectation de pointeur,159
algorithme,22
allocation de
mémoire,53
allocation
dynamique,66, 102
alphabet,33
alphanumérique,18
analyse
amortie,24
analyse du cas
pire,23
analyse en
moyenne,24
analyse
formelle,13
analyse
syntaxique,31
analyseur
syntaxique,18
arité,108
B
Bjarne
Stroustrup,61
bloc,35
boucle,38
branchement
conditionnel,10
branchements
multiples,39
bug,14
C
calcul
effectif,22
calloc,102
cast,66
cerr,63
champ,82
champs,53
cin,63
class,62, 82,
84, 168
classe,52, 82
classe abstraite,161
classe de base,53,
138
classe de classes,171
classe
dérivée,53, 84, 138
classe
fille,53, 138
classe générique,168, 171
classe
imbriquée,131
classe
mère,53, 138
classe template,171
classe
virtuelle,53, 153
classes,54
classes
d'objets,82
clog,63
code
exécutable,17
code
générique,55
comportement,54
confidentialité,79
const,62, 66
constantes génériques,187
constructeur,53,
93
constructeur
copie,118, 122
constructeur
copie implicite,119
constructeur
explicite,94
constructeur
implicite,93
conteneur,162
conversion implicite,98
couche
objet,52, 53
cout,63
D
debogeur
symbolique,19
déclaration,34,
66
déclaration de
type,32
définition,34,
65
définition d'une fonction générique,170
delete,66,
102, 103
delete[],103
destructeur,53,
93, 102
destructeur
explicite,102
destructeur
par défaut,102
document
technique de référence,13
domaine de
définition,36
domaine de
valeur,36
donnée
membre,82
donnée membre statique,88
données
membres,53
dynamic_cast,156
E
éditeur de
texte,18
émetteur,52
encapsulation,54
encapsulation
des données,52
étiquette,18
exception,209
explicit,99
export,191
expression,33
extern,66
F
fonction,62
fonction
constructeur,55, 94
fonction
destructeur,55
fonction
générique,70, 168, 169
fonction générique amie,171
fonction
inline,82
fonction
membre,53, 82
fonction opérateur,108
fonction
spécifiée inline,80
fonction template,169
Fonctions statiques,80
friend,111
G
générateur
d'applications,10
généricité,56
génie
logiciel,11
grammaire,31
H
héritage,53,
138
héritage
multiple,138
héritage
qualifié private,141
héritage
qualifié protected,141
héritage
qualifié public,141
héritage
simple,138
hiérarchie de
classe,53
I
implémentation,54
induction
mathématique,26
inline,69
instance,82
instance,52
instanciation,53
instanciation des paramètres génériques,168, 176
instanciation du paramètre générique,187
instanciation explicite,178
instanciation implicite,176
instruction
exécutable,33, 65
instruction
généralisée,35
instruction
non exécutable,33
instruction
symbolique,70
intégrité,37
interface d'accès,54
iostream.h,63
itération,43
J
jeu d'essais,22
L
label,18
langage de
quatrième génération,10
levée de
l'encapsulation,111
libération de
la mémoire,66
lien dynamique,157
Lvaleur,78
M
main,38
maintenance,14
malloc,102
mécanisme
d'abstraction,16
message,52, 64
métaclasse,171, 186
métalangage,29
méthode,16,
52, 53, 82
méthode générique,174
méthode
inline,86
méthode
spécifiée constante,87
méthode
statique,91
méthode virtuelle,156, 188
méthode virtuelle pure,161
méthodes,52
modèle
abstrait,53
modularité,52
mutable,67
N
new,66, 102
nom
symbolique,34
O
objet,52, 64
objet de
référence,74
objet template,168
opérateur,33,
64
opérateur &,74
opérateur *,74
opérateur .,,83
opérateur
~,102
opérateur
arithmétique,32
opérateur de
déréférenciation,62, 74
opérateur de
portée,82
opérateur de
référence,62, 74, 128
opérateur de
résolution de visibilité,66, 67
opérateur de sélection de membre,128
opérateur fonctionnel,125
opérateur
logique,32
opérateur
relationnel,32
opérateur
surchargé,108
opérations,52
opérator,108
opérer,52
outils de
développement,17
P
paramètre générique,168
paramètre template template,186
passe,18
pile
d'exécution,37
pointeur
constant déréférencé,74
pointeur
déréferencé,78
pointeur
déréférencé,75
polymorphisme,55,
70, 157
portée,70
préprocesseur,70,
80
private,84,
141
privé,84
problème
calculatoire,22
problème
NP-complet,23
procédure,37
profileur,19
protected,84,
141
protégé,84
prototype,34,
76
prototype de
fonction,70
public,84, 141
pure virtual method,161
Q
qualification
de l’héritage,138
qualifications
du contrôle d'accès,141
R
realloc,102
récepteur,52
référence,17,
18, 74
référence,74
référence en
avant,18
référence
externe,18
référence
interne,18
règles de dérivation,159
relation
d'ordre,112
rémanence,79
représentation
digitale interne,32
représentation
interne,16, 54
requalification,145
résultat d'une
fonction,36
return,36, 69
rupture de
séquence,10
S
s,169
scope,82
sélecteur
d'objet membre,62
sélecteur sur
pointeur,62
sémantique,31
signature,70
signature
d'une fonction,70, 108
Signature
d'une fonction,70
Simula,52
sizeof,108
spécialisation partielle,182
spécialisation totale,184
spécificateur
const,77
spécificateur
d'accès,84
spécificateur
inline,86
spécificateur
inline,80
spécificateur template,183
spécification,12
static,80
struct,62, 82,
84
structures de
contrôle,38
support,14
surcharge,53,
55, 56, 70
surcharge de
l'opérateur [],116
surcharge de
l'opérateur d'affectation,122
surcharge des
fonctions,70
surcharge des
opérateurs,33
surcharge d'un
opérateur,55
surcharge
d'une fonction,55
symbole,18
syntaxe,31
T
table des
symboles,18
tableau,32, 62
template,168
test,38
test de fin de
boucle,43
test de
régression,19
tests de
couverture,19
this,86, 91,
109
transmission
des arguments,36
transmission
des arguments par référence,75
transmission
par adresse,36, 75
transmission
par valeur,37
transtypage,66
transtypage
explicite,98
transtypage
fonctionnel,66
transtypage
fonctionnel,98
transtypage
implicite,144
transtypage
par appel de fonction,66
typage,53
type
abstrait,17
type du
résultat d'une fonction,36
type effectif,168
type générique,168
type
référence,74
typedef,67
typename,168, 169, 191
types
symboliques,70
U
union,62
V
valeur par
défaut,72, 169
Valeur par défaut d'un type générique,168
variable,33
variable
statique,79
variable
symbolique,33, 34
variables,52
variables
d'instance,53
virtual,156
void*,62